 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Resolution Be Aware! Improving the Self-Supervised Real-World Super-Resolution
Nov 25, 2024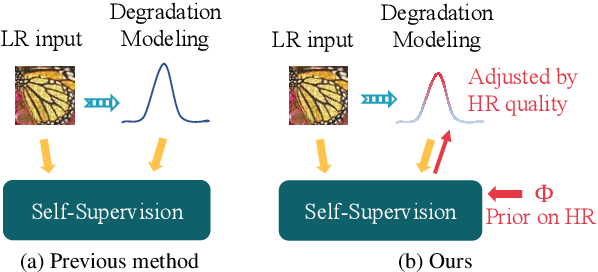
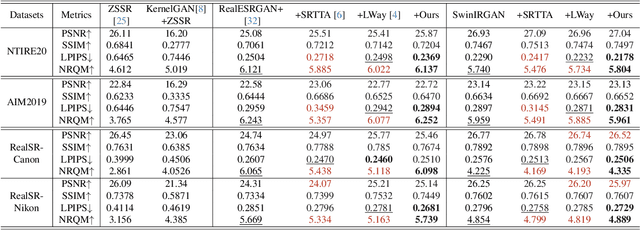
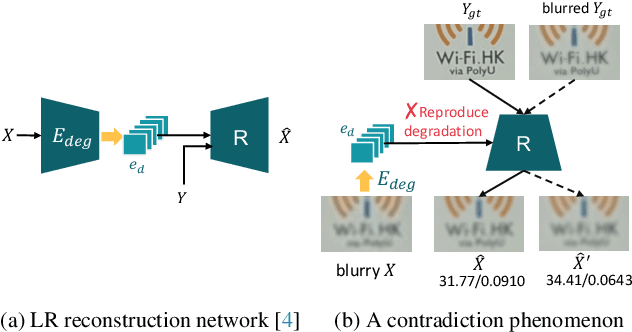
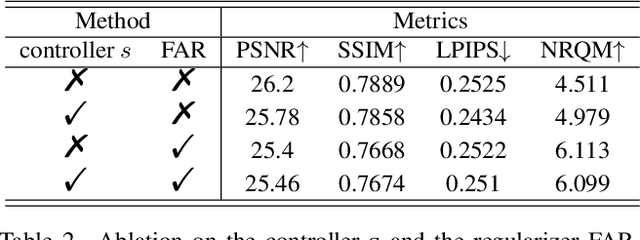
Self-supervised learning is crucial for super-resolution because ground-truth images are usually unavailable for real-world settings. Existing methods derive self-supervision from low-resolution images by creating pseudo-pairs or by enforcing a low-resolution reconstruction objective. These methods struggle with insufficient modeling of real-world degradations and the lack of knowledge about high-resolution imagery, resulting in unnatural super-resolved results. This paper strengthens awareness of the high-resolution image to improve the self-supervised real-world super-resolution. We propose a controller to adjust the degradation modeling based on the quality of super-resolution results. We also introduce a novel feature-alignment regularizer that directly constrains the distribution of super-resolved images. Our method finetunes the off-the-shelf SR models for a target real-world domain. Experiments show that it produces natural super-resolved images with state-of-the-art perceptual performance.
PersonaMark: Personalized LLM watermarking for model protection and user attribution
Sep 15, 2024



The rapid development of LLMs brings both convenience and potential threats. As costumed and private LLMs are widely applied, model copyright protection has become important. Text watermarking is emerging as a promising solution to AI-generated text detection and model protection issues. However, current text watermarks have largely ignored the critical need for injecting different watermarks for different users, which could help attribute the watermark to a specific individual. In this paper, we explore the personalized text watermarking scheme for LLM copyright protection and other scenarios, ensuring accountability and traceability in content generation. Specifically, we propose a novel text watermarking method PersonaMark that utilizes sentence structure as the hidden medium for the watermark information and optimizes the sentence-level generation algorithm to minimize disruption to the model's natural generation process. By employing a personalized hashing function to inject unique watermark signals for different users, personalized watermarked text can be obtained. Since our approach performs on sentence level instead of token probability, the text quality is highly preserved. The injection process of unique watermark signals for different users is time-efficient for a large number of users with the designed multi-user hashing function. As far as we know, we achieved personalized text watermarking for the first time through this. We conduct an extensive evaluation of four different LLMs in terms of perplexity, sentiment polarity, alignment, readability, etc. The results demonstrate that our method maintains performance with minimal perturbation to the model's behavior, allows for unbiased insertion of watermark information, and exhibits strong watermark recognition capabilities.
UniFashion: A Unified Vision-Language Model for Multimodal Fashion Retrieval and Generation
Aug 21, 2024
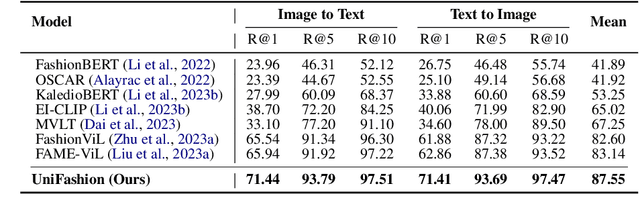
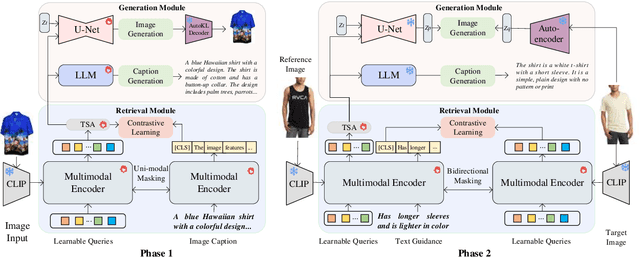
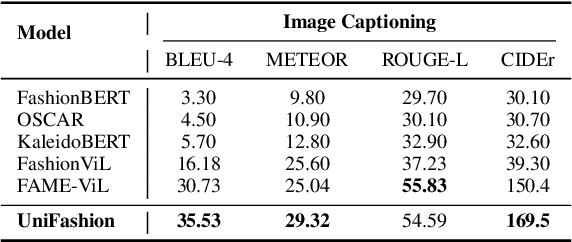
The fashion domain encompasses a variety of real-world multimodal tasks, including multimodal retrieval and multimodal generation. The rapid advancements in artificial intelligence generated content, particularly in technologies like large language models for text generation and diffusion models for visual generation, have sparked widespread research interest in applying these multimodal models in the fashion domain. However, tasks involving embeddings, such as image-to-text or text-to-image retrieval, have been largely overlooked from this perspective due to the diverse nature of the multimodal fashion domain. And current research on multi-task single models lack focus on image generation. In this work, we present UniFashion, a unified framework that simultaneously tackles the challenges of multimodal generation and retrieval tasks within the fashion domain, integrating image generation with retrieval tasks and text generation tasks. UniFashion unifies embedding and generative tasks by integrating a diffusion model and LLM, enabling controllable and high-fidelity generation. Our model significantly outperforms previous single-task state-of-the-art models across diverse fashion tasks, and can be readily adapted to manage complex vision-language tasks. This work demonstrates the potential learning synergy between multimodal generation and retrieval, offering a promising direction for future research in the fashion domain. The source code is available at https://github.com/xiangyu-mm/UniFashion.
RealViformer: Investigating Attention for Real-World Video Super-Resolution
Jul 19, 2024In real-world video super-resolution (VSR), videos suffer from in-the-wild degradations and artifacts. VSR methods, especially recurrent ones, tend to propagate artifacts over time in the real-world setting and are more vulnerable than image super-resolution. This paper investigates the influence of artifacts on commonly used covariance-based attention mechanisms in VSR. Comparing the widely-used spatial attention, which computes covariance over space, versus the channel attention, we observe that the latter is less sensitive to artifacts. However, channel attention leads to feature redundancy, as evidenced by the higher covariance among output channels. As such, we explore simple techniques such as the squeeze-excite mechanism and covariance-based rescaling to counter the effects of high channel covariance. Based on our findings, we propose RealViformer. This channel-attention-based real-world VSR framework surpasses state-of-the-art on two real-world VSR datasets with fewer parameters and faster runtimes. The source code is available at https://github.com/Yuehan717/RealViformer.
Pairwise Distance Distillation for Unsupervised Real-World Image Super-Resolution
Jul 10, 2024



Standard single-image super-resolution creates paired training data from high-resolution images through fixed downsampling kernels. However, real-world super-resolution (RWSR) faces unknown degradations in the low-resolution inputs, all the while lacking paired training data. Existing methods approach this problem by learning blind general models through complex synthetic augmentations on training inputs; they sacrifice the performance on specific degradation for broader generalization to many possible ones. We address the unsupervised RWSR for a targeted real-world degradation. We study from a distillation perspective and introduce a novel pairwise distance distillation framework. Through our framework, a model specialized in synthetic degradation adapts to target real-world degradations by distilling intra- and inter-model distances across the specialized model and an auxiliary generalized model. Experiments on diverse datasets demonstrate that our method significantly enhances fidelity and perceptual quality, surpassing state-of-the-art approaches in RWSR. The source code is available at https://github.com/Yuehan717/PDD.
Perception-Distortion Balanced ADMM Optimization for Single-Image Super-Resolution
Aug 16, 2022
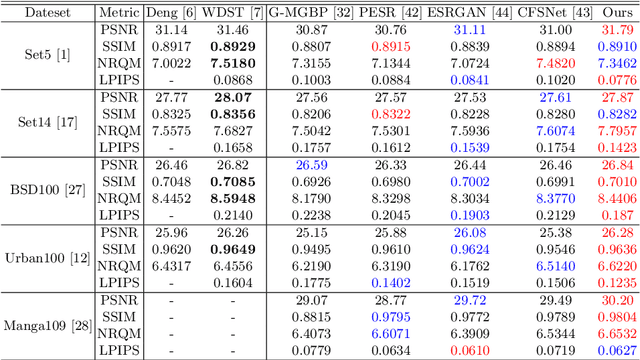
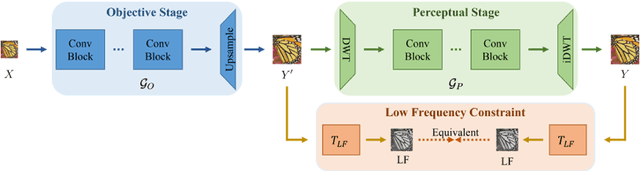
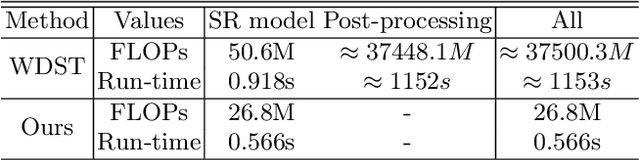
In image super-resolution, both pixel-wise accuracy and perceptual fidelity are desirable. However, most deep learning methods only achieve high performance in one aspect due to the perception-distortion trade-off, and works that successfully balance the trade-off rely on fusing results from separately trained models with ad-hoc post-processing. In this paper, we propose a novel super-resolution model with a low-frequency constraint (LFc-SR), which balances the objective and perceptual quality through a single model and yields super-resolved images with high PSNR and perceptual scores. We further introduce an ADMM-based alternating optimization method for the non-trivial learning of the constrained model. Experiments showed that our method, without cumbersome post-processing procedures, achieved the state-of-the-art performance. The code is available at https://github.com/Yuehan717/PDASR.