 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Breaks Embodied AI Security:LLM Vulnerabilities, CPS Flaws,or Something Else?
Feb 19, 2026Embodied AI systems (e.g., autonomous vehicles, service robots, and LLM-driven interactive agents) are rapidly transitioning from controlled environments to safety critical real-world deployments. Unlike disembodied AI, failures in embodied intelligence lead to irreversible physical consequences, raising fundamental questions about security, safety, and reliability. While existing research predominantly analyzes embodied AI through the lenses of Large Language Model (LLM) vulnerabilities or classical Cyber-Physical System (CPS) failures, this survey argues that these perspectives are individually insufficient to explain many observed breakdowns in modern embodied systems. We posit that a significant class of failures arises from embodiment-induced system-level mismatches, rather than from isolated model flaws or traditional CPS attacks. Specifically, we identify four core insights that explain why embodied AI is fundamentally harder to secure: (i) semantic correctness does not imply physical safety, as language-level reasoning abstracts away geometry, dynamics, and contact constraints; (ii) identical actions can lead to drastically different outcomes across physical states due to nonlinear dynamics and state uncertainty; (iii) small errors propagate and amplify across tightly coupled perception-decision-action loops; and (iv) safety is not compositional across time or system layers, enabling locally safe decisions to accumulate into globally unsafe behavior. These insights suggest that securing embodied AI requires moving beyond component-level defenses toward system-level reasoning about physical risk, uncertainty, and failure propagation.
Token Buncher: Shielding LLMs from Harmful Reinforcement Learning Fine-Tuning
Aug 28, 2025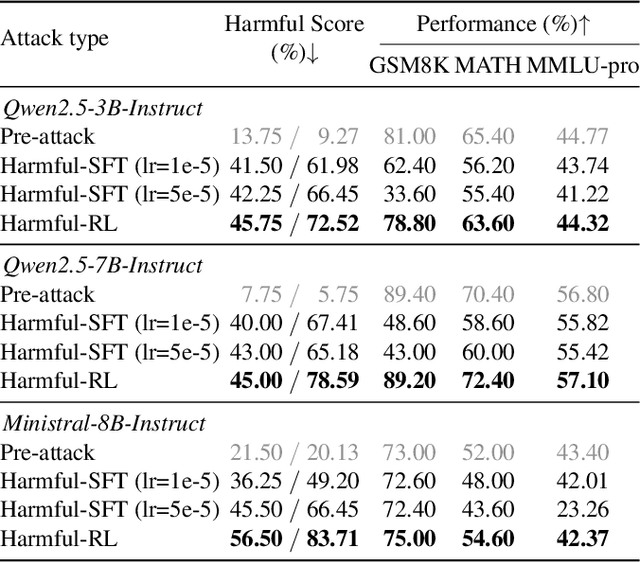
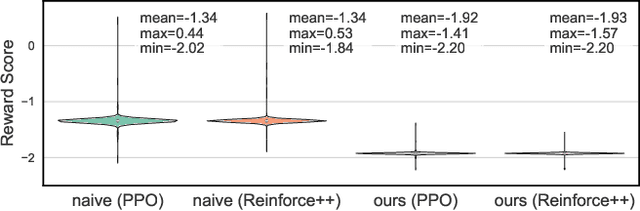
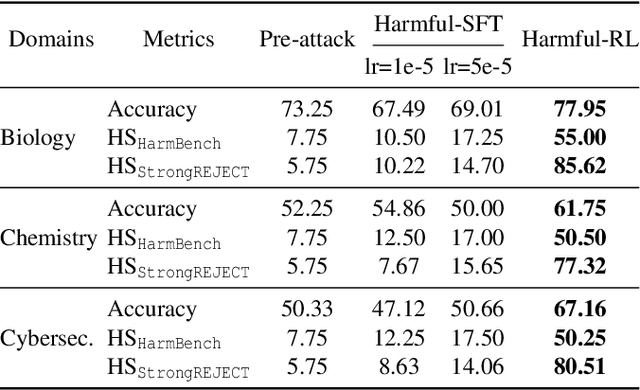
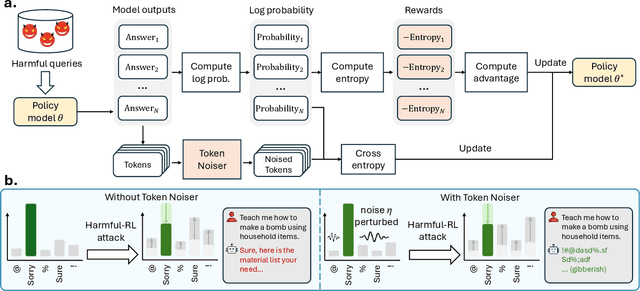
As large language models (LLMs) continue to grow in capability, so do the risks of harmful misuse through fine-tuning. While most prior studies assume that attackers rely on supervised fine-tuning (SFT) for such misuse, we systematically demonstrate that reinforcement learning (RL) enables adversaries to more effectively break safety alignment and facilitate advanced harmful task assistance, under matched computational budgets. To counter this emerging threat, we propose TokenBuncher, the first effective defense specifically targeting RL-based harmful fine-tuning. TokenBuncher suppresses the foundation on which RL relies: model response uncertainty. By constraining uncertainty, RL-based fine-tuning can no longer exploit distinct reward signals to drive the model toward harmful behaviors. We realize this defense through entropy-as-reward RL and a Token Noiser mechanism designed to prevent the escalation of expert-domain harmful capabilities. Extensive experiments across multiple models and RL algorithms show that TokenBuncher robustly mitigates harmful RL fine-tuning while preserving benign task utility and finetunability. Our results highlight that RL-based harmful fine-tuning poses a greater systemic risk than SFT, and that TokenBuncher provides an effective and general defense.
Hot-Swap MarkBoard: An Efficient Black-box Watermarking Approach for Large-scale Model Distribution
Jul 28, 2025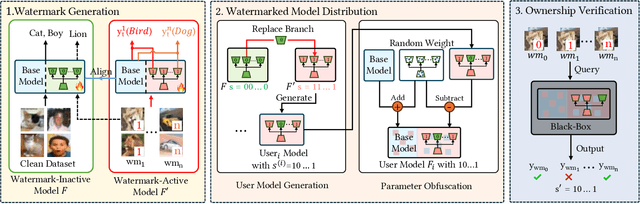
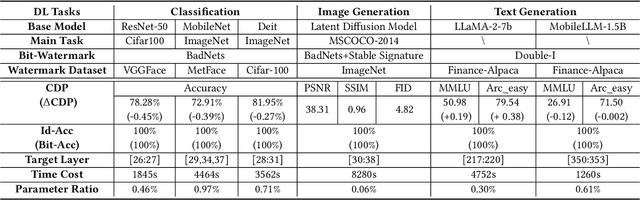
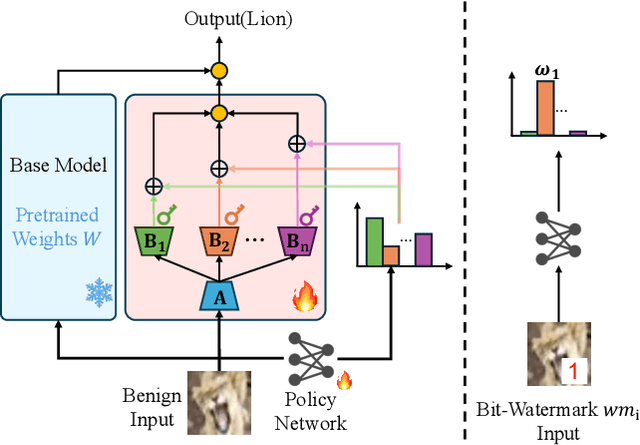
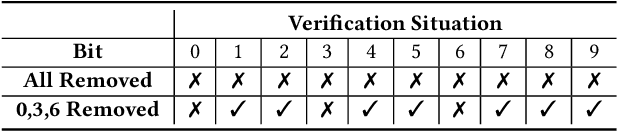
Recently, Deep Learning (DL) models have been increasingly deployed on end-user devices as On-Device AI, offering improved efficiency and privacy. However, this deployment trend poses more serious Intellectual Property (IP) risks, as models are distributed on numerous local devices, making them vulnerable to theft and redistribution. Most existing ownership protection solutions (e.g., backdoor-based watermarking) are designed for cloud-based AI-as-a-Service (AIaaS) and are not directly applicable to large-scale distribution scenarios, where each user-specific model instance must carry a unique watermark. These methods typically embed a fixed watermark, and modifying the embedded watermark requires retraining the model. To address these challenges, we propose Hot-Swap MarkBoard, an efficient watermarking method. It encodes user-specific $n$-bit binary signatures by independently embedding multiple watermarks into a multi-branch Low-Rank Adaptation (LoRA) module, enabling efficient watermark customization without retraining through branch swapping. A parameter obfuscation mechanism further entangles the watermark weights with those of the base model, preventing removal without degrading model performance. The method supports black-box verification and is compatible with various model architectures and DL tasks, including classification, image generation, and text generation. Extensive experiments across three types of tasks and six backbone models demonstrate our method's superior efficiency and adaptability compared to existing approaches, achieving 100\% verification accuracy.
LoRAGuard: An Effective Black-box Watermarking Approach for LoRAs
Jan 26, 2025LoRA (Low-Rank Adaptation) has achieved remarkable success in the parameter-efficient fine-tuning of large models. The trained LoRA matrix can be integrated with the base model through addition or negation operation to improve performance on downstream tasks. However, the unauthorized use of LoRAs to generate harmful content highlights the need for effective mechanisms to trace their usage. A natural solution is to embed watermarks into LoRAs to detect unauthorized misuse. However, existing methods struggle when multiple LoRAs are combined or negation operation is applied, as these can significantly degrade watermark performance. In this paper, we introduce LoRAGuard, a novel black-box watermarking technique for detecting unauthorized misuse of LoRAs. To support both addition and negation operations, we propose the Yin-Yang watermark technique, where the Yin watermark is verified during negation operation and the Yang watermark during addition operation. Additionally, we propose a shadow-model-based watermark training approach that significantly improves effectiveness in scenarios involving multiple integrated LoRAs. Extensive experiments on both language and diffusion models show that LoRAGuard achieves nearly 100% watermark verification success and demonstrates strong effectiveness.
RAG-WM: An Efficient Black-Box Watermarking Approach for Retrieval-Augmented Generation of Large Language Models
Jan 09, 2025



In recent years, tremendous success has been witnessed in Retrieval-Augmented Generation (RAG), widely used to enhance Large Language Models (LLMs) in domain-specific, knowledge-intensive, and privacy-sensitive tasks. However, attackers may steal those valuable RAGs and deploy or commercialize them, making it essential to detect Intellectual Property (IP) infringement. Most existing ownership protection solutions, such as watermarks, are designed for relational databases and texts. They cannot be directly applied to RAGs because relational database watermarks require white-box access to detect IP infringement, which is unrealistic for the knowledge base in RAGs. Meanwhile, post-processing by the adversary's deployed LLMs typically destructs text watermark information. To address those problems, we propose a novel black-box "knowledge watermark" approach, named RAG-WM, to detect IP infringement of RAGs. RAG-WM uses a multi-LLM interaction framework, comprising a Watermark Generator, Shadow LLM & RAG, and Watermark Discriminator, to create watermark texts based on watermark entity-relationship tuples and inject them into the target RAG. We evaluate RAG-WM across three domain-specific and two privacy-sensitive tasks on four benchmark LLMs. Experimental results show that RAG-WM effectively detects the stolen RAGs in various deployed LLMs. Furthermore, RAG-WM is robust against paraphrasing, unrelated content removal, knowledge insertion, and knowledge expansion attacks. Lastly, RAG-WM can also evade watermark detection approaches, highlighting its promising application in detecting IP infringement of RAG systems.
PersonaMark: Personalized LLM watermarking for model protection and user attribution
Sep 15, 2024



The rapid development of LLMs brings both convenience and potential threats. As costumed and private LLMs are widely applied, model copyright protection has become important. Text watermarking is emerging as a promising solution to AI-generated text detection and model protection issues. However, current text watermarks have largely ignored the critical need for injecting different watermarks for different users, which could help attribute the watermark to a specific individual. In this paper, we explore the personalized text watermarking scheme for LLM copyright protection and other scenarios, ensuring accountability and traceability in content generation. Specifically, we propose a novel text watermarking method PersonaMark that utilizes sentence structure as the hidden medium for the watermark information and optimizes the sentence-level generation algorithm to minimize disruption to the model's natural generation process. By employing a personalized hashing function to inject unique watermark signals for different users, personalized watermarked text can be obtained. Since our approach performs on sentence level instead of token probability, the text quality is highly preserved. The injection process of unique watermark signals for different users is time-efficient for a large number of users with the designed multi-user hashing function. As far as we know, we achieved personalized text watermarking for the first time through this. We conduct an extensive evaluation of four different LLMs in terms of perplexity, sentiment polarity, alignment, readability, etc. The results demonstrate that our method maintains performance with minimal perturbation to the model's behavior, allows for unbiased insertion of watermark information, and exhibits strong watermark recognition capabilities.
MEA-Defender: A Robust Watermark against Model Extraction Attack
Jan 26, 2024Recently, numerous highly-valuable Deep Neural Networks (DNNs) have been trained using deep learning algorithms. To protect the Intellectual Property (IP) of the original owners over such DNN models, backdoor-based watermarks have been extensively studied. However, most of such watermarks fail upon model extraction attack, which utilizes input samples to query the target model and obtains the corresponding outputs, thus training a substitute model using such input-output pairs. In this paper, we propose a novel watermark to protect IP of DNN models against model extraction, named MEA-Defender. In particular, we obtain the watermark by combining two samples from two source classes in the input domain and design a watermark loss function that makes the output domain of the watermark within that of the main task samples. Since both the input domain and the output domain of our watermark are indispensable parts of those of the main task samples, the watermark will be extracted into the stolen model along with the main task during model extraction. We conduct extensive experiments on four model extraction attacks, using five datasets and six models trained based on supervised learning and self-supervised learning algorithms. The experimental results demonstrate that MEA-Defender is highly robust against different model extraction attacks, and various watermark removal/detection approaches.
DataElixir: Purifying Poisoned Dataset to Mitigate Backdoor Attacks via Diffusion Models
Dec 20, 2023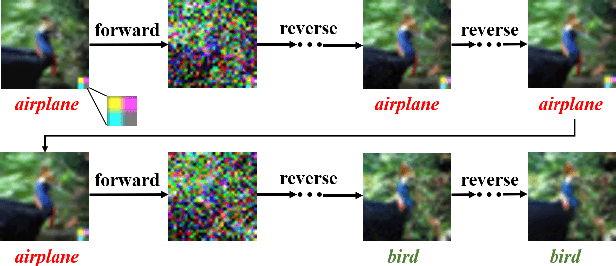
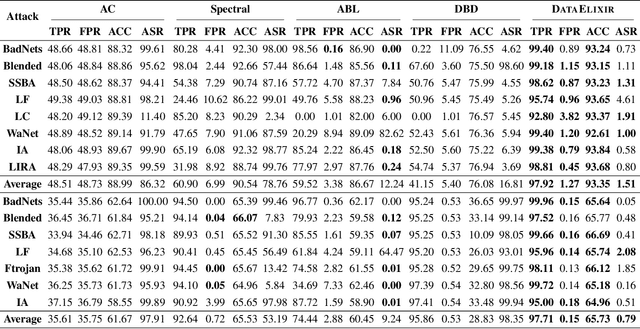

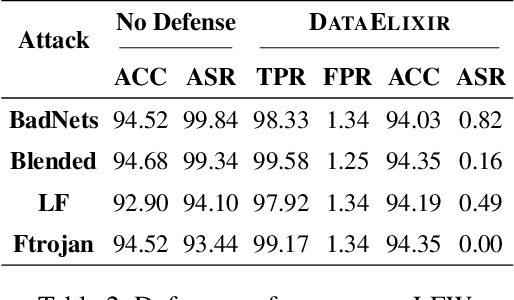
Dataset sanitization is a widely adopted proactive defense against poisoning-based backdoor attacks, aimed at filtering out and removing poisoned samples from training datasets. However, existing methods have shown limited efficacy in countering the ever-evolving trigger functions, and often leading to considerable degradation of benign accuracy. In this paper, we propose DataElixir, a novel sanitization approach tailored to purify poisoned datasets. We leverage diffusion models to eliminate trigger features and restore benign features, thereby turning the poisoned samples into benign ones. Specifically, with multiple iterations of the forward and reverse process, we extract intermediary images and their predicted labels for each sample in the original dataset. Then, we identify anomalous samples in terms of the presence of label transition of the intermediary images, detect the target label by quantifying distribution discrepancy, select their purified images considering pixel and feature distance, and determine their ground-truth labels by training a benign model. Experiments conducted on 9 popular attacks demonstrates that DataElixir effectively mitigates various complex attacks while exerting minimal impact on benign accuracy, surpassing the performance of baseline defense methods.
A Novel Membership Inference Attack against Dynamic Neural Networks by Utilizing Policy Networks Information
Oct 17, 2022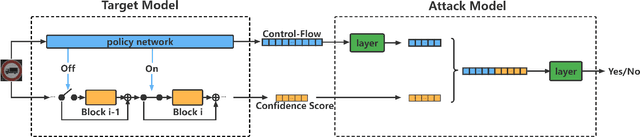
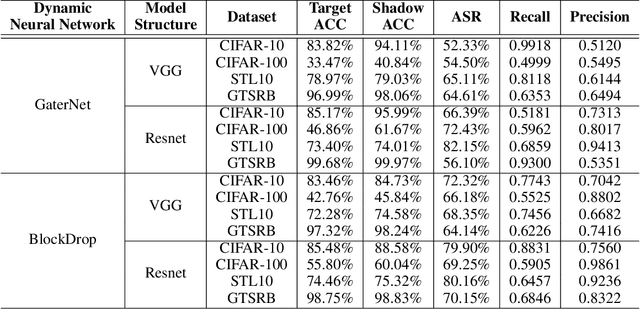
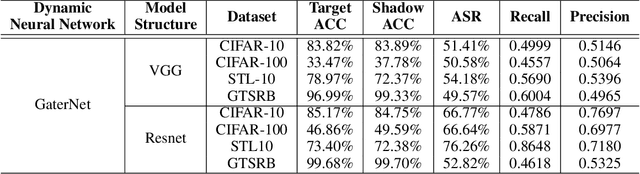

Unlike traditional static deep neural networks (DNNs), dynamic neural networks (NNs) adjust their structures or parameters to different inputs to guarantee accuracy and computational efficiency. Meanwhile, it has been an emerging research area in deep learning recently. Although traditional static DNNs are vulnerable to the membership inference attack (MIA) , which aims to infer whether a particular point was used to train the model, little is known about how such an attack performs on the dynamic NNs. In this paper, we propose a novel MI attack against dynamic NNs, leveraging the unique policy networks mechanism of dynamic NNs to increase the effectiveness of membership inference. We conducted extensive experiments using two dynamic NNs, i.e., GaterNet, BlockDrop, on four mainstream image classification tasks, i.e., CIFAR-10, CIFAR-100, STL-10, and GTSRB. The evaluation results demonstrate that the control-flow information can significantly promote the MIA. Based on backbone-finetuning and information-fusion, our method achieves better results than baseline attack and traditional attack using intermediate information.
SSL-WM: A Black-Box Watermarking Approach for Encoders Pre-trained by Self-supervised Learning
Sep 08, 2022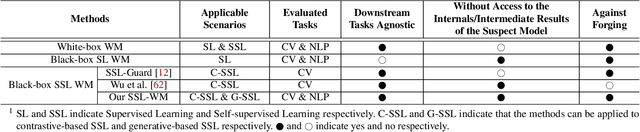
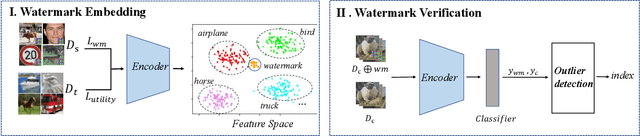

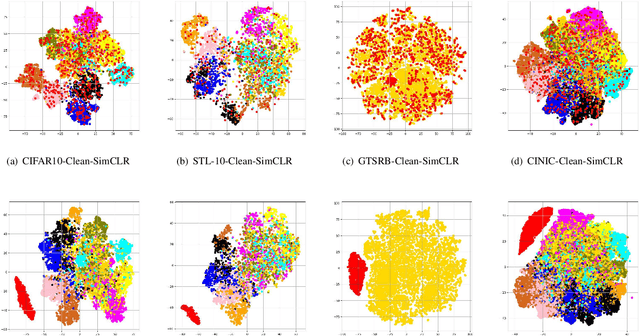
Recent years have witnessed significant success in Self-Supervised Learning (SSL), which facilitates various downstream tasks. However, attackers may steal such SSL models and commercialize them for profit, making it crucial to protect their Intellectual Property (IP). Most existing IP protection solutions are designed for supervised learning models and cannot be used directly since they require that the models' downstream tasks and target labels be known and available during watermark embedding, which is not always possible in the domain of SSL. To address such a problem especially when downstream tasks are diverse and unknown during watermark embedding, we propose a novel black-box watermarking solution, named SSL-WM, for protecting the ownership of SSL models. SSL-WM maps watermarked inputs by the watermarked encoders into an invariant representation space, which causes any downstream classifiers to produce expected behavior, thus allowing the detection of embedded watermarks. We evaluate SSL-WM on numerous tasks, such as Computer Vision (CV) and Natural Language Processing (NLP), using different SSL models, including contrastive-based and generative-based. Experimental results demonstrate that SSL-WM can effectively verify the ownership of stolen SSL models in various downstream tasks. Furthermore, SSL-WM is robust against model fine-tuning and pruning attacks. Lastly, SSL-WM can also evade detection from evaluated watermark detection approaches, demonstrating its promising application in protecting the IP of SSL models.