 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEA-Defender: A Robust Watermark against Model Extraction Attack
Jan 26, 2024Recently, numerous highly-valuable Deep Neural Networks (DNNs) have been trained using deep learning algorithms. To protect the Intellectual Property (IP) of the original owners over such DNN models, backdoor-based watermarks have been extensively studied. However, most of such watermarks fail upon model extraction attack, which utilizes input samples to query the target model and obtains the corresponding outputs, thus training a substitute model using such input-output pairs. In this paper, we propose a novel watermark to protect IP of DNN models against model extraction, named MEA-Defender. In particular, we obtain the watermark by combining two samples from two source classes in the input domain and design a watermark loss function that makes the output domain of the watermark within that of the main task samples. Since both the input domain and the output domain of our watermark are indispensable parts of those of the main task samples, the watermark will be extracted into the stolen model along with the main task during model extraction. We conduct extensive experiments on four model extraction attacks, using five datasets and six models trained based on supervised learning and self-supervised learning algorithms. The experimental results demonstrate that MEA-Defender is highly robust against different model extraction attacks, and various watermark removal/detection approaches.
DataElixir: Purifying Poisoned Dataset to Mitigate Backdoor Attacks via Diffusion Models
Dec 20, 2023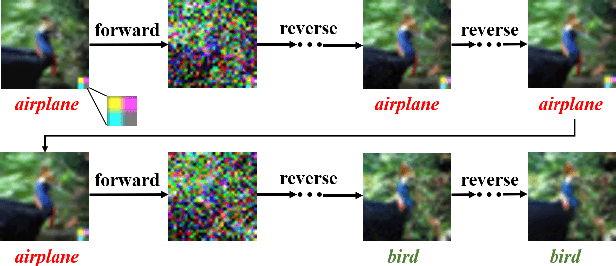
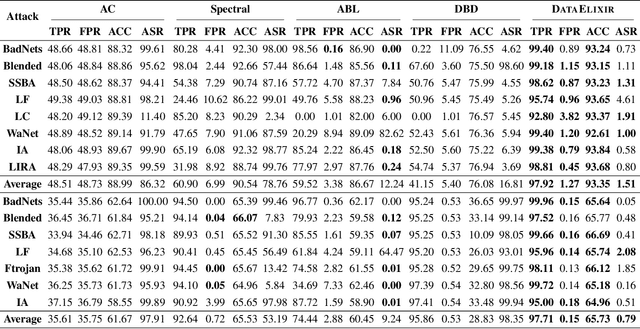

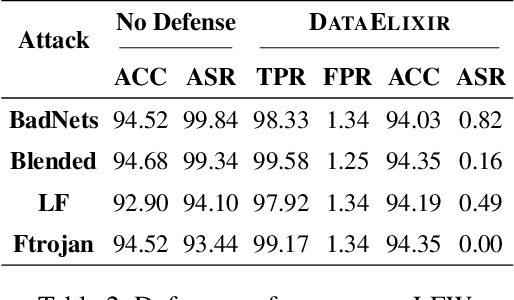
Dataset sanitization is a widely adopted proactive defense against poisoning-based backdoor attacks, aimed at filtering out and removing poisoned samples from training datasets. However, existing methods have shown limited efficacy in countering the ever-evolving trigger functions, and often leading to considerable degradation of benign accuracy. In this paper, we propose DataElixir, a novel sanitization approach tailored to purify poisoned datasets. We leverage diffusion models to eliminate trigger features and restore benign features, thereby turning the poisoned samples into benign ones. Specifically, with multiple iterations of the forward and reverse process, we extract intermediary images and their predicted labels for each sample in the original dataset. Then, we identify anomalous samples in terms of the presence of label transition of the intermediary images, detect the target label by quantifying distribution discrepancy, select their purified images considering pixel and feature distance, and determine their ground-truth labels by training a benign model. Experiments conducted on 9 popular attacks demonstrates that DataElixir effectively mitigates various complex attacks while exerting minimal impact on benign accuracy, surpassing the performance of baseline defense methods.
SSL-WM: A Black-Box Watermarking Approach for Encoders Pre-trained by Self-supervised Learning
Sep 08, 2022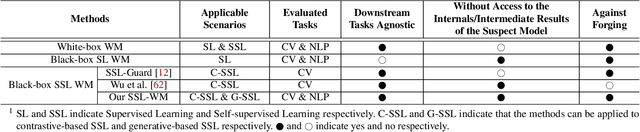
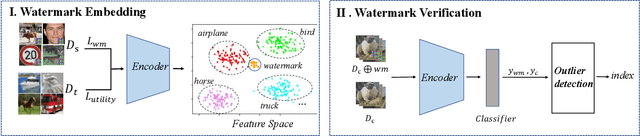

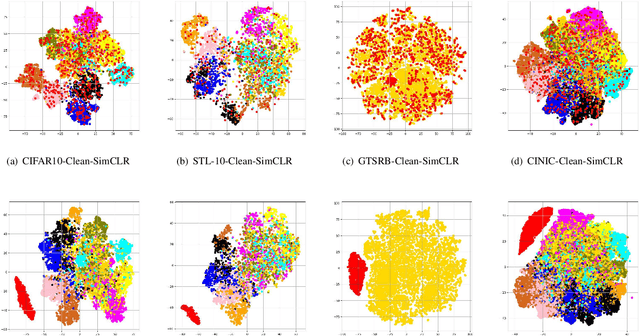
Recent years have witnessed significant success in Self-Supervised Learning (SSL), which facilitates various downstream tasks. However, attackers may steal such SSL models and commercialize them for profit, making it crucial to protect their Intellectual Property (IP). Most existing IP protection solutions are designed for supervised learning models and cannot be used directly since they require that the models' downstream tasks and target labels be known and available during watermark embedding, which is not always possible in the domain of SSL. To address such a problem especially when downstream tasks are diverse and unknown during watermark embedding, we propose a novel black-box watermarking solution, named SSL-WM, for protecting the ownership of SSL models. SSL-WM maps watermarked inputs by the watermarked encoders into an invariant representation space, which causes any downstream classifiers to produce expected behavior, thus allowing the detection of embedded watermarks. We evaluate SSL-WM on numerous tasks, such as Computer Vision (CV) and Natural Language Processing (NLP), using different SSL models, including contrastive-based and generative-based. Experimental results demonstrate that SSL-WM can effectively verify the ownership of stolen SSL models in various downstream tasks. Furthermore, SSL-WM is robust against model fine-tuning and pruning attacks. Lastly, SSL-WM can also evade detection from evaluated watermark detection approaches, demonstrating its promising application in protecting the IP of SSL models.
DBIA: Data-free Backdoor Injection Attack against Transformer Networks
Nov 22, 2021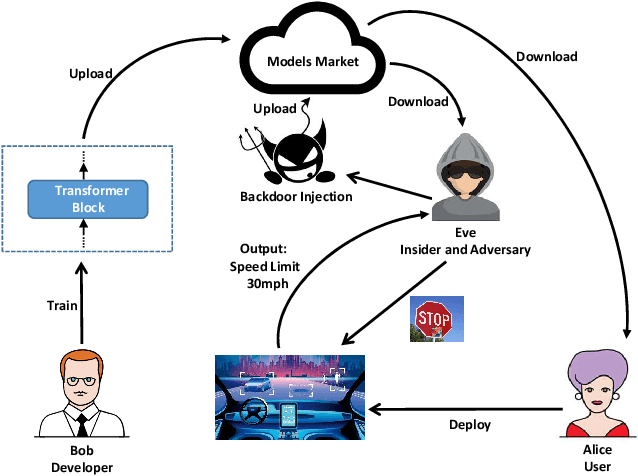

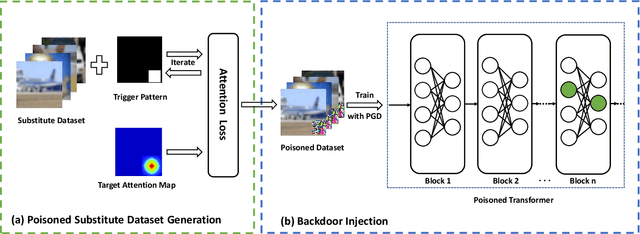
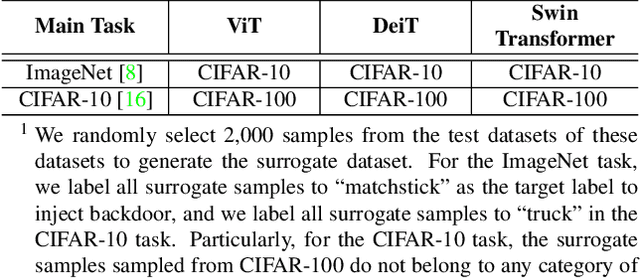
Recently, transformer architecture has demonstrated its significance in both Natural Language Processing (NLP) and Computer Vision (CV) tasks. Though other network models are known to be vulnerable to the backdoor attack, which embeds triggers in the model and controls the model behavior when the triggers are presented, little is known whether such an attack is still valid on the transformer models and if so, whether it can be done in a more cost-efficient manner. In this paper, we propose DBIA, a novel data-free backdoor attack against the CV-oriented transformer networks, leveraging the inherent attention mechanism of transformers to generate triggers and injecting the backdoor using the poisoned surrogate dataset. We conducted extensive experiments based on three benchmark transformers, i.e., ViT, DeiT and Swin Transformer, on two mainstream image classification tasks, i.e., CIFAR10 and ImageNet. The evaluation results demonstrate that, consuming fewer resources, our approach can embed backdoors with a high success rate and a low impact on the performance of the victim transformers. Our code is available at https://anonymous.4open.science/r/DBIA-825D.