 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAP-DIFF: Semantic Adversarial Patch Generation for Black-Box Face Recognition Models via Diffusion Models
Feb 27, 2025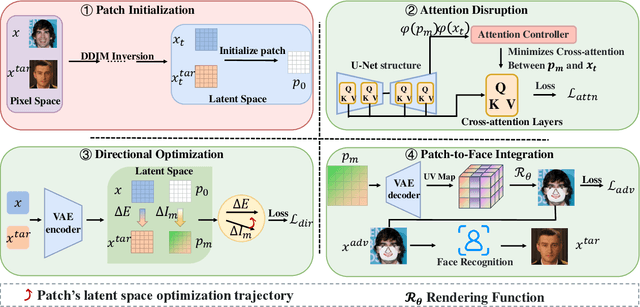
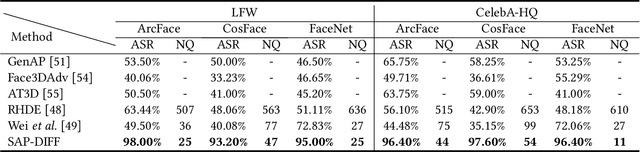

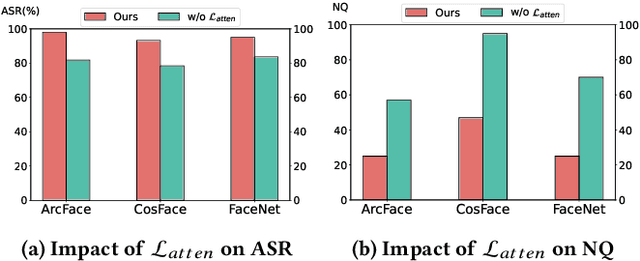
Given the need to evaluate the robustness of face recognition (FR) models, many efforts have focused on adversarial patch attacks that mislead FR models by introducing localized perturbations. Impersonation attacks are a significant threat because adversarial perturbations allow attackers to disguise themselves as legitimate users. This can lead to severe consequences, including data breaches, system damage, and misuse of resources. However, research on such attacks in FR remains limited. Existing adversarial patch generation methods exhibit limited efficacy in impersonation attacks due to (1) the need for high attacker capabilities, (2) low attack success rates, and (3) excessive query requirements. To address these challenges, we propose a novel method SAP-DIFF that leverages diffusion models to generate adversarial patches via semantic perturbations in the latent space rather than direct pixel manipulation. We introduce an attention disruption mechanism to generate features unrelated to the original face, facilitating the creation of adversarial samples and a directional loss function to guide perturbations toward the target identity feature space, thereby enhancing attack effectiveness and efficiency. Extensive experiments on popular FR models and datasets demonstrate that our method outperforms state-of-the-art approaches, achieving an average attack success rate improvement of 45.66% (all exceeding 40%), and a reduction in the number of queries by about 40% compared to the SOTA approach
Rule-based Data Selection for Large Language Models
Oct 07, 2024
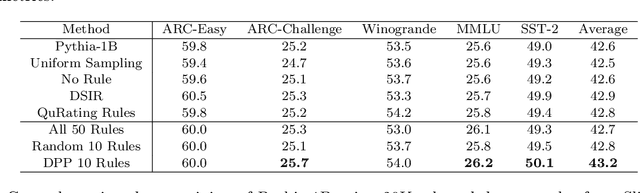
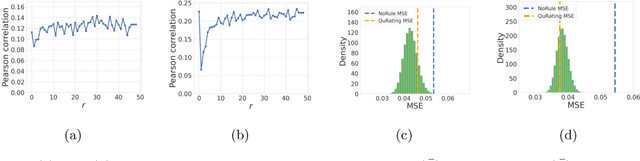
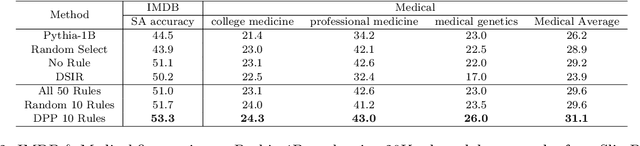
The quality of training data significantly impacts the performance of large language models (LLMs). There are increasing studies using LLMs to rate and select data based on several human-crafted metrics (rules). However, these conventional rule-based approaches often depend too heavily on human heuristics, lack effective metrics for assessing rules, and exhibit limited adaptability to new tasks. In our study, we introduce an innovative rule-based framework that utilizes the orthogonality of score vectors associated with rules as a novel metric for rule evaluations. Our approach includes an automated pipeline that first uses LLMs to generate a diverse set of rules, encompassing various rating dimensions to evaluate data quality. Then it rates a batch of data based on these rules and uses the determinantal point process (DPP) from random matrix theory to select the most orthogonal score vectors, thereby identifying a set of independent rules. These rules are subsequently used to evaluate all data, selecting samples with the highest average scores for downstream tasks such as LLM training. We verify the effectiveness of our method through two experimental setups: 1) comparisons with ground truth ratings and 2) benchmarking LLMs trained with the chosen data. Our comprehensive experiments cover a range of scenarios, including general pre-training and domain-specific fine-tuning in areas such as IMDB, Medical, Math, and Code. The outcomes demonstrate that our DPP-based rule rating method consistently outperforms other approaches, including rule-free rating, uniform sampling, importance resampling, and QuRating, in terms of both rating precision and model performance.
Learning Interpretable Differentiable Logic Networks
Jul 04, 2024The ubiquity of neural networks (NNs) in real-world applications, from healthcare to natural language processing, underscores their immense utility in capturing complex relationships within high-dimensional data. However, NNs come with notable disadvantages, such as their "black-box" nature, which hampers interpretability, as well as their tendency to overfit the training data. We introduce a novel method for learning interpretable differentiable logic networks (DLNs) that are architectures that employ multiple layers of binary logic operators. We train these networks by softening and differentiating their discrete components, e.g., through binarization of inputs, binary logic operations, and connections between neurons. This approach enables the use of gradient-based learning methods. Experimental results on twenty classification tasks indicate that differentiable logic networks can achieve accuracies comparable to or exceeding that of traditional NNs. Equally importantly, these networks offer the advantage of interpretability. Moreover, their relatively simple structure results in the number of logic gate-level operations during inference being up to a thousand times smaller than NNs, making them suitable for deployment on edge devices.
Model-Enhanced LLM-Driven VUI Testing of VPA Apps
Jul 03, 2024The flourishing ecosystem centered around voice personal assistants (VPA), such as Amazon Alexa, has led to the booming of VPA apps. The largest app market Amazon skills store, for example, hosts over 200,000 apps. Despite their popularity, the open nature of app release and the easy accessibility of apps also raise significant concerns regarding security, privacy and quality. Consequently, various testing approaches have been proposed to systematically examine VPA app behaviors. To tackle the inherent lack of a visible user interface in the VPA app, two strategies are employed during testing, i.e., chatbot-style testing and model-based testing. The former often lacks effective guidance for expanding its search space, while the latter falls short in interpreting the semantics of conversations to construct precise and comprehensive behavior models for apps. In this work, we introduce Elevate, a model-enhanced large language model (LLM)-driven VUI testing framework. Elevate leverages LLMs' strong capability in natural language processing to compensate for semantic information loss during model-based VUI testing. It operates by prompting LLMs to extract states from VPA apps' outputs and generate context-related inputs. During the automatic interactions with the app, it incrementally constructs the behavior model, which facilitates the LLM in generating inputs that are highly likely to discover new states. Elevate bridges the LLM and the behavior model with innovative techniques such as encoding behavior model into prompts and selecting LLM-generated inputs based on the context relevance. Elevate is benchmarked on 4,000 real-world Alexa skills, against the state-of-the-art tester Vitas. It achieves 15% higher state space coverage compared to Vitas on all types of apps, and exhibits significant advancement in efficiency.
SSL-WM: A Black-Box Watermarking Approach for Encoders Pre-trained by Self-supervised Learning
Sep 08, 2022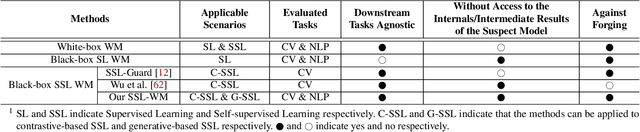
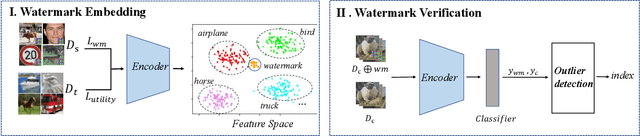

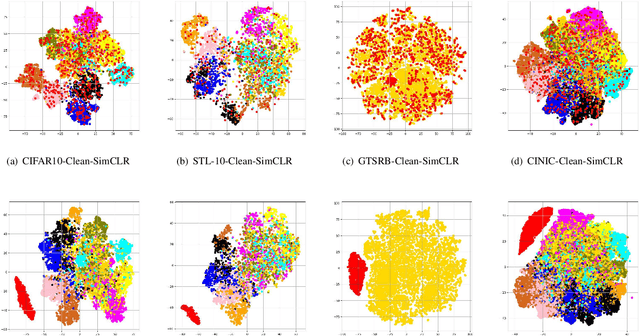
Recent years have witnessed significant success in Self-Supervised Learning (SSL), which facilitates various downstream tasks. However, attackers may steal such SSL models and commercialize them for profit, making it crucial to protect their Intellectual Property (IP). Most existing IP protection solutions are designed for supervised learning models and cannot be used directly since they require that the models' downstream tasks and target labels be known and available during watermark embedding, which is not always possible in the domain of SSL. To address such a problem especially when downstream tasks are diverse and unknown during watermark embedding, we propose a novel black-box watermarking solution, named SSL-WM, for protecting the ownership of SSL models. SSL-WM maps watermarked inputs by the watermarked encoders into an invariant representation space, which causes any downstream classifiers to produce expected behavior, thus allowing the detection of embedded watermarks. We evaluate SSL-WM on numerous tasks, such as Computer Vision (CV) and Natural Language Processing (NLP), using different SSL models, including contrastive-based and generative-based. Experimental results demonstrate that SSL-WM can effectively verify the ownership of stolen SSL models in various downstream tasks. Furthermore, SSL-WM is robust against model fine-tuning and pruning attacks. Lastly, SSL-WM can also evade detection from evaluated watermark detection approaches, demonstrating its promising application in protecting the IP of SSL models.
CTRL: Clustering Training Losses for Label Error Detection
Aug 17, 2022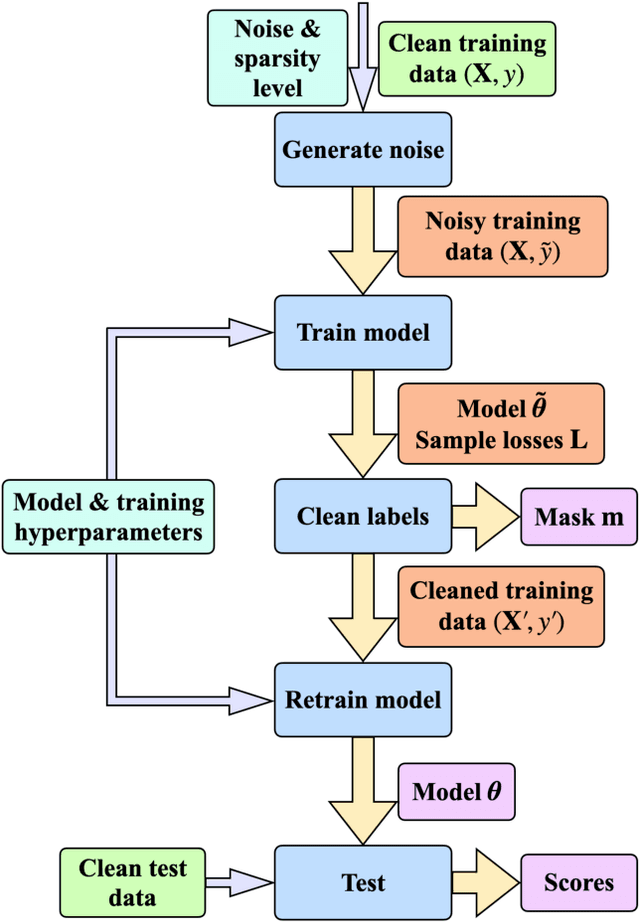
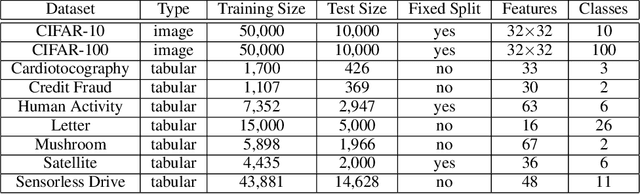
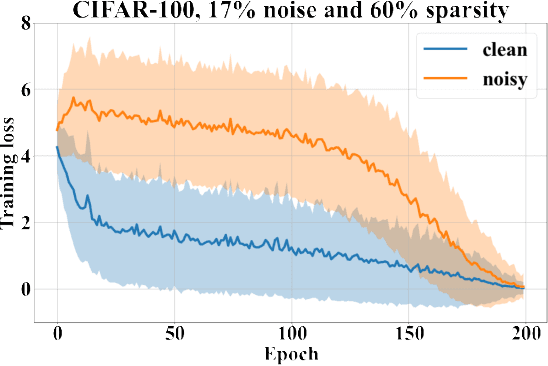
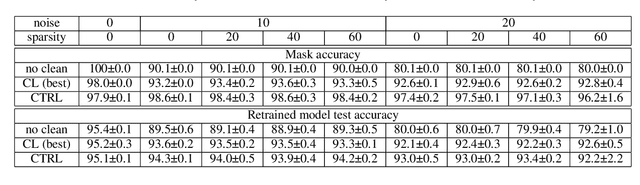
In supervised machine learning, use of correct labels is extremely important to ensure high accuracy. Unfortunately, most datasets contain corrupted labels. Machine learning models trained on such datasets do not generalize well. Thus, detecting their label errors can significantly increase their efficacy. We propose a novel framework, called CTRL (Clustering TRaining Losses for label error detection), to detect label errors in multi-class datasets. It detects label errors in two steps based on the observation that models learn clean and noisy labels in different ways. First, we train a neural network using the noisy training dataset and obtain the loss curve for each sample. Then, we apply clustering algorithms to the training losses to group samples into two categories: cleanly-labeled and noisily-labeled. After label error detection, we remove samples with noisy labels and retrain the model. Our experimental results demonstrate state-of-the-art error detection accuracy on both image (CIFAR-10 and CIFAR-100) and tabular datasets under simulated noise. We also use a theoretical analysis to provide insights into why CTRL performs so well.
Invisible Backdoor Attacks Using Data Poisoning in the Frequency Domain
Jul 09, 2022
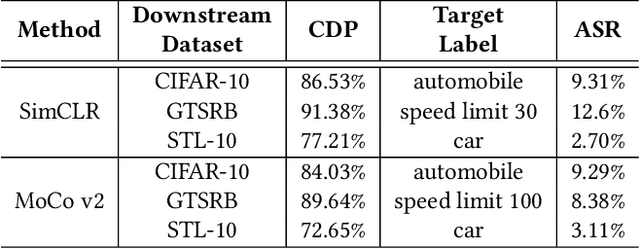

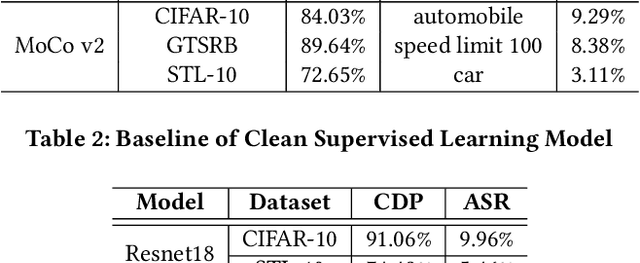
With the broad application of deep neural networks (DNNs), backdoor attacks have gradually attracted attention. Backdoor attacks are insidious, and poisoned models perform well on benign samples and are only triggered when given specific inputs, which cause the neural network to produce incorrect outputs. The state-of-the-art backdoor attack work is implemented by data poisoning, i.e., the attacker injects poisoned samples into the dataset, and the models trained with that dataset are infected with the backdoor. However, most of the triggers used in the current study are fixed patterns patched on a small fraction of an image and are often clearly mislabeled, which is easily detected by humans or defense methods such as Neural Cleanse and SentiNet. Also, it's difficult to be learned by DNNs without mislabeling, as they may ignore small patterns. In this paper, we propose a generalized backdoor attack method based on the frequency domain, which can implement backdoor implantation without mislabeling and accessing the training process. It is invisible to human beings and able to evade the commonly used defense methods. We evaluate our approach in the no-label and clean-label cases on three datasets (CIFAR-10, STL-10, and GTSRB) with two popular scenarios (self-supervised learning and supervised learning). The results show our approach can achieve a high attack success rate (above 90%) on all the tasks without significant performance degradation on main tasks. Also, we evaluate the bypass performance of our approach for different kinds of defenses, including the detection of training data (i.e., Activation Clustering), the preprocessing of inputs (i.e., Filtering), the detection of inputs (i.e., SentiNet), and the detection of models (i.e., Neural Cleanse). The experimental results demonstrate that our approach shows excellent robustness to such defenses.