 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapley-Guided Neural Repair Approach via Derivative-Free Optimization
Apr 01, 2026DNNs are susceptible to defects like backdoors, adversarial attacks, and unfairness, undermining their reliability. Existing approaches mainly involve retraining, optimization, constraint-solving, or search algorithms. However, most methods rely on gradient calculations, restricting applicability to specific activation functions (e.g., ReLU), or use search algorithms with uninterpretable localization and repair. Furthermore, they often lack generalizability across multiple properties. We propose SHARPEN, integrating interpretable fault localization with a derivative-free optimization strategy. First, SHARPEN introduces a Deep SHAP-based localization strategy quantifying each layer's and neuron's marginal contribution to erroneous outputs. Specifically, a hierarchical coarse-to-fine approach reranks layers by aggregated impact, then locates faulty neurons/filters by analyzing activation divergences between property-violating and benign states. Subsequently, SHARPEN incorporates CMA-ES to repair identified neurons. CMA-ES leverages a covariance matrix to capture variable dependencies, enabling gradient-free search and coordinated adjustments across coupled neurons. By combining interpretable localization with evolutionary optimization, SHARPEN enables derivative-free repair across architectures, being less sensitive to gradient anomalies and hyperparameters. We demonstrate SHARPEN's effectiveness on three repair tasks. Balancing property repair and accuracy preservation, it outperforms baselines in backdoor removal (+10.56%), adversarial mitigation (+5.78%), and unfairness repair (+11.82%). Notably, SHARPEN handles diverse tasks, and its modular design is plug-and-play with different derivative-free optimizers, highlighting its flexibility.
Model-Enhanced LLM-Driven VUI Testing of VPA Apps
Jul 03, 2024The flourishing ecosystem centered around voice personal assistants (VPA), such as Amazon Alexa, has led to the booming of VPA apps. The largest app market Amazon skills store, for example, hosts over 200,000 apps. Despite their popularity, the open nature of app release and the easy accessibility of apps also raise significant concerns regarding security, privacy and quality. Consequently, various testing approaches have been proposed to systematically examine VPA app behaviors. To tackle the inherent lack of a visible user interface in the VPA app, two strategies are employed during testing, i.e., chatbot-style testing and model-based testing. The former often lacks effective guidance for expanding its search space, while the latter falls short in interpreting the semantics of conversations to construct precise and comprehensive behavior models for apps. In this work, we introduce Elevate, a model-enhanced large language model (LLM)-driven VUI testing framework. Elevate leverages LLMs' strong capability in natural language processing to compensate for semantic information loss during model-based VUI testing. It operates by prompting LLMs to extract states from VPA apps' outputs and generate context-related inputs. During the automatic interactions with the app, it incrementally constructs the behavior model, which facilitates the LLM in generating inputs that are highly likely to discover new states. Elevate bridges the LLM and the behavior model with innovative techniques such as encoding behavior model into prompts and selecting LLM-generated inputs based on the context relevance. Elevate is benchmarked on 4,000 real-world Alexa skills, against the state-of-the-art tester Vitas. It achieves 15% higher state space coverage compared to Vitas on all types of apps, and exhibits significant advancement in efficiency.
Things You May Not Know About Adversarial Example: A Black-box Adversarial Image Attack
May 21, 2019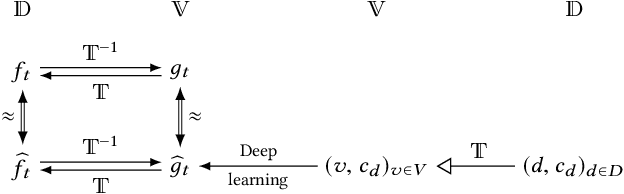

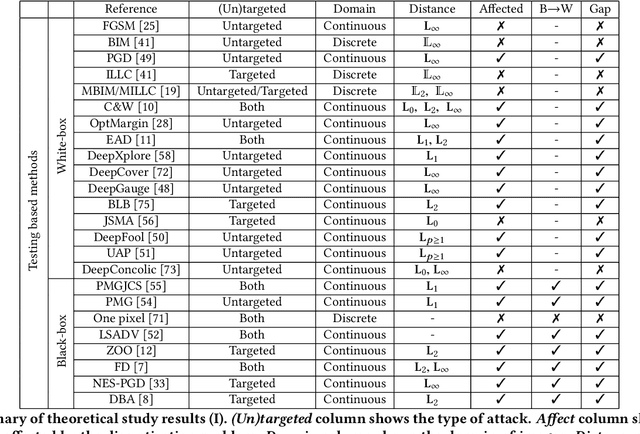

Numerous methods for crafting adversarial examples were proposed recently with high success rate. Most existing works normalize images into a continuous, real vector, domain firstly, and then craft adversarial examples in this domain. However, "adversarial" examples may become benign after de-normalizing them back into the discrete integer domain, known as the discretization problem. The discretization problem was mentioned in some work, but was underestimated and has received relatively little attention. In this work, we conduct the first comprehensive study of the discretization problem. We theoretically analyze 34 representative methods and empirically study 20 representative open source tools for crafting adversarial images. Our study reveals that almost all existing works suffer from the discretization problem and it is far more serious than originally thought. For instance, most black-box methods downgrade to white-box ones and methods having higher success rates drop down to lower high success rates, e.g., from 100% to 10%. This suggests that the discretization problem should be taken into account when crafting adversarial examples. As a first step towards addressing this problem, we propose a black-box method which reduces the adversarial example searching problem to a derivative-free optimization problem. Our method is able to craft `real' adversarial images by derivative-free search on the discrete integer domain. Experimental results show that our method achieves significantly higher success rate in terms of adversarial examples in the discrete integer domain than most other methods, no matter white-box or black-box. Moreover, our method is able to handle models that is non-differentiable and we successfully break the winner of NIPS 17 competition on defense with 95% success rate.