 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Model Modulation with Logits Redistribution
Mar 13, 2026Large-scale models are typically adapted to meet the diverse requirements of model owners and users. However, maintaining multiple specialized versions of the model is inefficient. In response, we propose AIM, a novel model modulation paradigm that enables a single model to exhibit diverse behaviors to meet the specific end requirements. AIM enables two key modulation modes: utility and focus modulations. The former provides model owners with dynamic control over output quality to deliver varying utility levels, and the latter offers users precise control to shift model's focused input features. AIM introduces a logits redistribution strategy that operates in a training data-agnostic and retraining-free manner. We establish a formal foundation to ensure AIM's regulation capability, based on the statistical properties of logits ordering via joint probability distributions. Our evaluation confirms AIM's practicality and versatility for Al model modulation, with tasks spanning image classification, semantic segmentation and text generation, and prevalent architectures including ResNet, SegFormer and Llama.
SecureSplit: Mitigating Backdoor Attacks in Split Learning
Jan 20, 2026Split Learning (SL) offers a framework for collaborative model training that respects data privacy by allowing participants to share the same dataset while maintaining distinct feature sets. However, SL is susceptible to backdoor attacks, in which malicious clients subtly alter their embeddings to insert hidden triggers that compromise the final trained model. To address this vulnerability, we introduce SecureSplit, a defense mechanism tailored to SL. SecureSplit applies a dimensionality transformation strategy to accentuate subtle differences between benign and poisoned embeddings, facilitating their separation. With this enhanced distinction, we develop an adaptive filtering approach that uses a majority-based voting scheme to remove contaminated embeddings while preserving clean ones. Rigorous experiments across four datasets (CIFAR-10, MNIST, CINIC-10, and ImageNette), five backdoor attack scenarios, and seven alternative defenses confirm the effectiveness of SecureSplit under various challenging conditions.
Text Meets Topology: Rethinking Out-of-distribution Detection in Text-Rich Networks
Aug 25, 2025Out-of-distribution (OOD) detection remains challenging in text-rich networks, where textual features intertwine with topological structures. Existing methods primarily address label shifts or rudimentary domain-based splits, overlooking the intricate textual-structural diversity. For example, in social networks, where users represent nodes with textual features (name, bio) while edges indicate friendship status, OOD may stem from the distinct language patterns between bot and normal users. To address this gap, we introduce the TextTopoOOD framework for evaluating detection across diverse OOD scenarios: (1) attribute-level shifts via text augmentations and embedding perturbations; (2) structural shifts through edge rewiring and semantic connections; (3) thematically-guided label shifts; and (4) domain-based divisions. Furthermore, we propose TNT-OOD to model the complex interplay between Text aNd Topology using: 1) a novel cross-attention module to fuse local structure into node-level text representations, and 2) a HyperNetwork to generate node-specific transformation parameters. This aligns topological and semantic features of ID nodes, enhancing ID/OOD distinction across structural and textual shifts. Experiments on 11 datasets across four OOD scenarios demonstrate the nuanced challenge of TextTopoOOD for evaluating OOD detection in text-rich networks.
Detecting Manipulated Contents Using Knowledge-Grounded Inference
Apr 29, 2025The detection of manipulated content, a prevalent form of fake news, has been widely studied in recent years. While existing solutions have been proven effective in fact-checking and analyzing fake news based on historical events, the reliance on either intrinsic knowledge obtained during training or manually curated context hinders them from tackling zero-day manipulated content, which can only be recognized with real-time contextual information. In this work, we propose Manicod, a tool designed for detecting zero-day manipulated content. Manicod first sources contextual information about the input claim from mainstream search engines, and subsequently vectorizes the context for the large language model (LLM) through retrieval-augmented generation (RAG). The LLM-based inference can produce a "truthful" or "manipulated" decision and offer a textual explanation for the decision. To validate the effectiveness of Manicod, we also propose a dataset comprising 4270 pieces of manipulated fake news derived from 2500 recent real-world news headlines. Manicod achieves an overall F1 score of 0.856 on this dataset and outperforms existing methods by up to 1.9x in F1 score on their benchmarks on fact-checking and claim verification.
MAA: Meticulous Adversarial Attack against Vision-Language Pre-trained Models
Feb 12, 2025Current adversarial attacks for evaluating the robustness of vision-language pre-trained (VLP) models in multi-modal tasks suffer from limited transferability, where attacks crafted for a specific model often struggle to generalize effectively across different models, limiting their utility in assessing robustness more broadly. This is mainly attributed to the over-reliance on model-specific features and regions, particularly in the image modality. In this paper, we propose an elegant yet highly effective method termed Meticulous Adversarial Attack (MAA) to fully exploit model-independent characteristics and vulnerabilities of individual samples, achieving enhanced generalizability and reduced model dependence. MAA emphasizes fine-grained optimization of adversarial images by developing a novel resizing and sliding crop (RScrop) technique, incorporating a multi-granularity similarity disruption (MGSD) strategy. Extensive experiments across diverse VLP models, multiple benchmark datasets, and a variety of downstream tasks demonstrate that MAA significantly enhances the effectiveness and transferability of adversarial attacks. A large cohort of performance studies is conducted to generate insights into the effectiveness of various model configurations, guiding future advancements in this domain.
GOLD: Graph Out-of-Distribution Detection via Implicit Adversarial Latent Generation
Feb 09, 2025Despite graph neural networks' (GNNs) great success in modelling graph-structured data, out-of-distribution (OOD) test instances still pose a great challenge for current GNNs. One of the most effective techniques to detect OOD nodes is to expose the detector model with an additional OOD node-set, yet the extra OOD instances are often difficult to obtain in practice. Recent methods for image data address this problem using OOD data synthesis, typically relying on pre-trained generative models like Stable Diffusion. However, these approaches require vast amounts of additional data, as well as one-for-all pre-trained generative models, which are not available for graph data. Therefore, we propose the GOLD framework for graph OOD detection, an implicit adversarial learning pipeline with synthetic OOD exposure without pre-trained models. The implicit adversarial training process employs a novel alternating optimisation framework by training: (1) a latent generative model to regularly imitate the in-distribution (ID) embeddings from an evolving GNN, and (2) a GNN encoder and an OOD detector to accurately classify ID data while increasing the energy divergence between the ID embeddings and the generative model's synthetic embeddings. This novel approach implicitly transforms the synthetic embeddings into pseudo-OOD instances relative to the ID data, effectively simulating exposure to OOD scenarios without auxiliary data. Extensive OOD detection experiments are conducted on five benchmark graph datasets, verifying the superior performance of GOLD without using real OOD data compared with the state-of-the-art OOD exposure and non-exposure baselines.
Model-Enhanced LLM-Driven VUI Testing of VPA Apps
Jul 03, 2024The flourishing ecosystem centered around voice personal assistants (VPA), such as Amazon Alexa, has led to the booming of VPA apps. The largest app market Amazon skills store, for example, hosts over 200,000 apps. Despite their popularity, the open nature of app release and the easy accessibility of apps also raise significant concerns regarding security, privacy and quality. Consequently, various testing approaches have been proposed to systematically examine VPA app behaviors. To tackle the inherent lack of a visible user interface in the VPA app, two strategies are employed during testing, i.e., chatbot-style testing and model-based testing. The former often lacks effective guidance for expanding its search space, while the latter falls short in interpreting the semantics of conversations to construct precise and comprehensive behavior models for apps. In this work, we introduce Elevate, a model-enhanced large language model (LLM)-driven VUI testing framework. Elevate leverages LLMs' strong capability in natural language processing to compensate for semantic information loss during model-based VUI testing. It operates by prompting LLMs to extract states from VPA apps' outputs and generate context-related inputs. During the automatic interactions with the app, it incrementally constructs the behavior model, which facilitates the LLM in generating inputs that are highly likely to discover new states. Elevate bridges the LLM and the behavior model with innovative techniques such as encoding behavior model into prompts and selecting LLM-generated inputs based on the context relevance. Elevate is benchmarked on 4,000 real-world Alexa skills, against the state-of-the-art tester Vitas. It achieves 15% higher state space coverage compared to Vitas on all types of apps, and exhibits significant advancement in efficiency.
Effective and Robust Adversarial Training against Data and Label Corruptions
May 07, 2024



Corruptions due to data perturbations and label noise are prevalent in the datasets from unreliable sources, which poses significant threats to model training. Despite existing efforts in developing robust models, current learning methods commonly overlook the possible co-existence of both corruptions, limiting the effectiveness and practicability of the model. In this paper, we develop an Effective and Robust Adversarial Training (ERAT) framework to simultaneously handle two types of corruption (i.e., data and label) without prior knowledge of their specifics. We propose a hybrid adversarial training surrounding multiple potential adversarial perturbations, alongside a semi-supervised learning based on class-rebalancing sample selection to enhance the resilience of the model for dual corruption. On the one hand, in the proposed adversarial training, the perturbation generation module learns multiple surrogate malicious data perturbations by taking a DNN model as the victim, while the model is trained to maintain semantic consistency between the original data and the hybrid perturbed data. It is expected to enable the model to cope with unpredictable perturbations in real-world data corruption. On the other hand, a class-rebalancing data selection strategy is designed to fairly differentiate clean labels from noisy labels. Semi-supervised learning is performed accordingly by discarding noisy labels. Extensive experiments demonstrate the superiority of the proposed ERAT framework.
PAODING: A High-fidelity Data-free Pruning Toolkit for Debloating Pre-trained Neural Networks
Apr 30, 2024

We present PAODING, a toolkit to debloat pretrained neural network models through the lens of data-free pruning. To preserve the model fidelity, PAODING adopts an iterative process, which dynamically measures the effect of deleting a neuron to identify candidates that have the least impact to the output layer. Our evaluation shows that PAODING can significantly reduce the model size, generalize on different datasets and models, and meanwhile preserve the model fidelity in terms of test accuracy and adversarial robustness. PAODING is publicly available on PyPI via https://pypi.org/project/paoding-dl.
Beyond Fidelity: Explaining Vulnerability Localization of Learning-based Detectors
Jan 05, 2024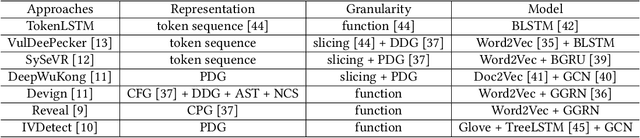
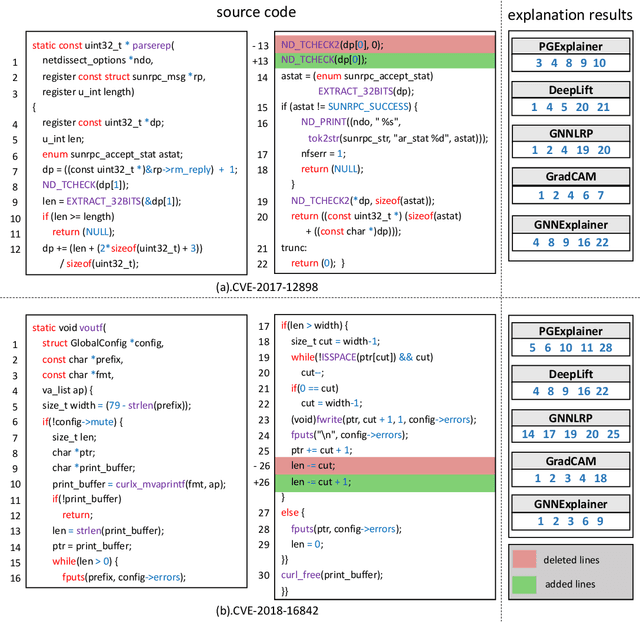
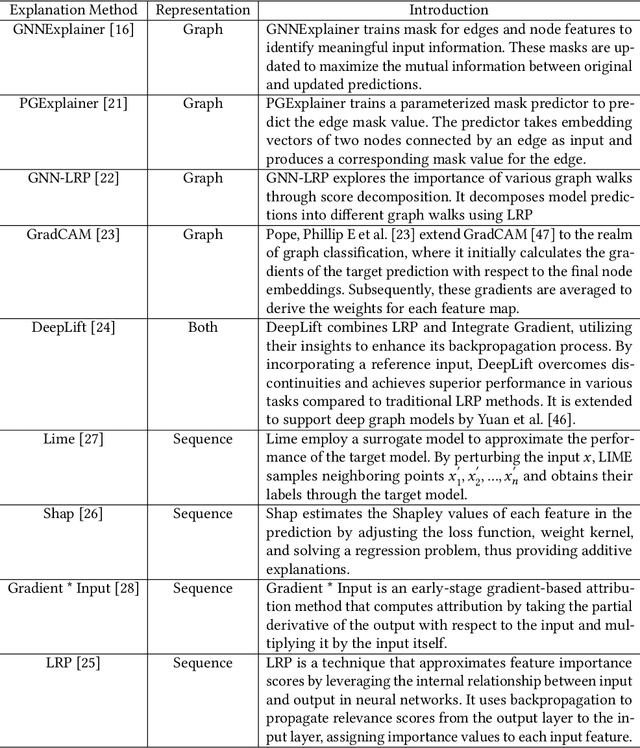
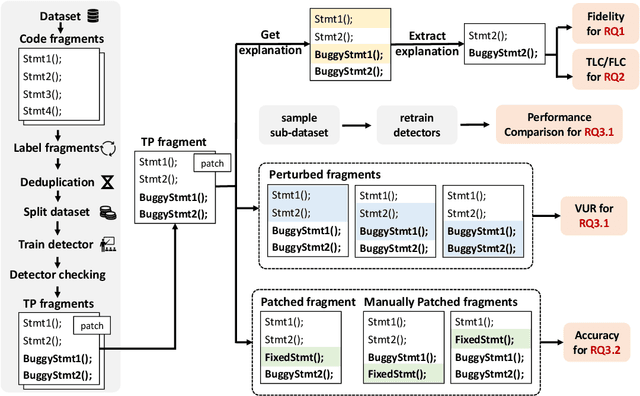
Vulnerability detectors based on deep learning (DL) models have proven their effectiveness in recent years. However, the shroud of opacity surrounding the decision-making process of these detectors makes it difficult for security analysts to comprehend. To address this, various explanation approaches have been proposed to explain the predictions by highlighting important features, which have been demonstrated effective in other domains such as computer vision and natural language processing. Unfortunately, an in-depth evaluation of vulnerability-critical features, such as fine-grained vulnerability-related code lines, learned and understood by these explanation approaches remains lacking. In this study, we first evaluate the performance of ten explanation approaches for vulnerability detectors based on graph and sequence representations, measured by two quantitative metrics including fidelity and vulnerability line coverage rate. Our results show that fidelity alone is not sufficient for evaluating these approaches, as fidelity incurs significant fluctuations across different datasets and detectors. We subsequently check the precision of the vulnerability-related code lines reported by the explanation approaches, and find poor accuracy in this task among all of them. This can be attributed to the inefficiency of explainers in selecting important features and the presence of irrelevant artifacts learned by DL-based detectors.