 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Robustness of Deep Neural Networks: A Survey from a Formal Verification Perspective
Paper and Code
Jun 24, 2022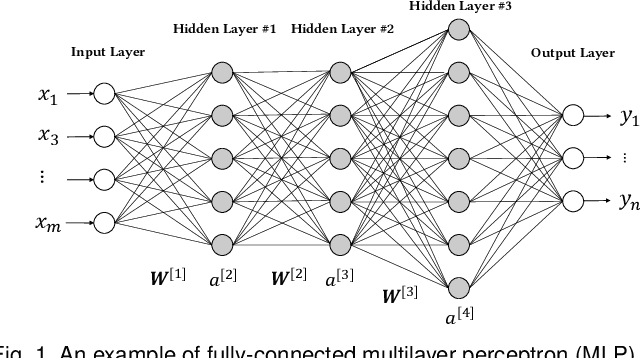
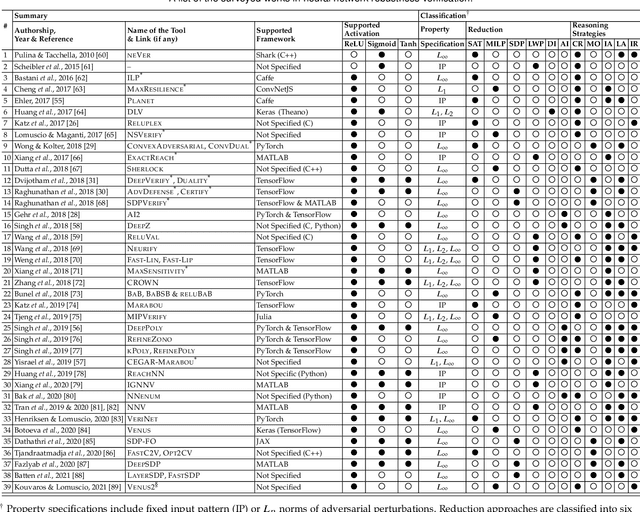
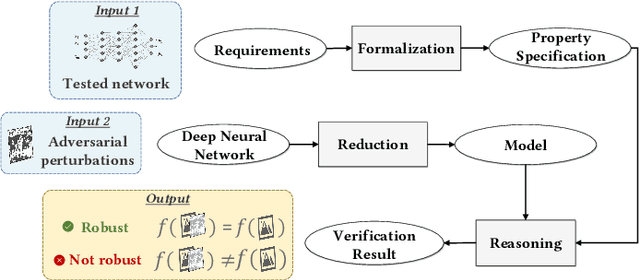

Neural networks have been widely applied in security applications such as spam and phishing detection, intrusion prevention, and malware detection. This black-box method, however, often has uncertainty and poor explainability in applications. Furthermore, neural networks themselves are often vulnerable to adversarial attacks. For those reasons, there is a high demand for trustworthy and rigorous methods to verify the robustness of neural network models. Adversarial robustness, which concerns the reliability of a neural network when dealing with maliciously manipulated inputs, is one of the hottest topics in security and machine learning. In this work, we survey existing literature in adversarial robustness verification for neural networks and collect 39 diversified research works across machine learning, security, and software engineering domains. We systematically analyze their approaches, including how robustness is formulated, what verification techniques are used, and the strengths and limitations of each technique. We provide a taxonomy from a formal verification perspective for a comprehensive understanding of this topic. We classify the existing techniques based on property specification, problem reduction, and reasoning strategies. We also demonstrate representative techniques that have been applied in existing studies with a sample model. Finally, we discuss open questions for future research.