 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverting the Shield: Systematically Generating Safety Tests from Policy Specifications
May 24, 2026The widespread integration of Large Language Models (LLMs) necessitates rigorous and systematic safety evaluation. Existing paradigms either rely on constructed benchmarks to assess safety from predefined perspectives, or employ dynamic red-teaming to probe potential vulnerabilities. While effective, these approaches face challenges, as they depend heavily on expert domain knowledge, offer limited systematic guarantees, and are vulnerable to rapid obsolescence. To address these limitations, we introduce a novel framework POLARIS that brings the rigor of specification-based software testing to AI safety. POLARIS first compiles unstructured natural-language policies into First-Order Logic (FOL) representations, establishing a traceable link between high-level rules and concrete test cases. This formalization enables the construction of a Semantic Policy Graph, where complex policy violation scenarios are encoded as traversable paths. By systematically exploring this graph, POLARIS uncovers compositional violation patterns, which are then instantiated into executable natural-language test queries, enabling coverage-driven and reproducible safety testing. Experiments demonstrate that POLARIS achieves higher policy coverage and attack success counts compared to established baselines. Crucially, by bridging formal methods and AI safety, POLARIS provides a principled, automated approach to ensuring LLMs adhere to safety-critical policies with verifiable traceability. We release our code at https://github.com/huac-lxy/POLARIS.
UniAda: Universal Adaptive Multi-objective Adversarial Attack for End-to-End Autonomous Driving Systems
Apr 25, 2026Adversarial attacks play a pivotal role in testing and improving the reliability of deep learning (DL) systems. Existing literature has demonstrated that subtle perturbations to the input can elicit erroneous outcomes, thereby substantially compromising the security of DL systems. This has emerged as a critical concern in the development of DL-based safety-critical systems like Autonomous Driving Systems (ADSs). The focus of existing adversarial attack methods on End-to-End (E2E) ADSs has predominantly centered on misbehaviors of steering angle, which overlooks speed-related controls or imperceptible perturbations. To address these challenges, we introduce UniAda, a multi-objective white-box attack technique with a core function that revolves around crafting an image-agnostic adversarial perturbation capable of simultaneously influencing both steering and speed controls. UniAda capitalizes on an intricately designed multi-objective optimization function with the Adaptive Weighting Scheme (AWS), enabling the concurrent optimization of diverse objectives. Validated with both simulated and real-world driving data, UniAda outperforms five benchmarks across two metrics, inducing steering and speed deviations from 3.54 degrees to 29 degrees and 11 km per hour to 22 km per hour on average. This systematic approach establishes UniAda as a proven technique for adversarial attacks on modern DL-based E2E ADSs.
Advancing Autonomous Driving System Testing: Demands, Challenges, and Future Directions
Dec 09, 2025Autonomous driving systems (ADSs) promise improved transportation efficiency and safety, yet ensuring their reliability in complex real-world environments remains a critical challenge. Effective testing is essential to validate ADS performance and reduce deployment risks. This study investigates current ADS testing practices for both modular and end-to-end systems, identifies key demands from industry practitioners and academic researchers, and analyzes the gaps between existing research and real-world requirements. We review major testing techniques and further consider emerging factors such as Vehicle-to-Everything (V2X) communication and foundation models, including large language models and vision foundation models, to understand their roles in enhancing ADS testing. We conducted a large-scale survey with 100 participants from both industry and academia. Survey questions were refined through expert discussions, followed by quantitative and qualitative analyses to reveal key trends, challenges, and unmet needs. Our results show that existing ADS testing techniques struggle to comprehensively evaluate real-world performance, particularly regarding corner case diversity, the simulation to reality gap, the lack of systematic testing criteria, exposure to potential attacks, practical challenges in V2X deployment, and the high computational cost of foundation model-based testing. By further analyzing participant responses together with 105 representative studies, we summarize the current research landscape and highlight major limitations. This study consolidates critical research gaps in ADS testing and outlines key future research directions, including comprehensive testing criteria, cross-model collaboration in V2X systems, cross-modality adaptation for foundation model-based testing, and scalable validation frameworks for large-scale ADS evaluation.
SafeMobile: Chain-level Jailbreak Detection and Automated Evaluation for Multimodal Mobile Agents
Jul 01, 2025With the wide application of multimodal foundation models in intelligent agent systems, scenarios such as mobile device control, intelligent assistant interaction, and multimodal task execution are gradually relying on such large model-driven agents. However, the related systems are also increasingly exposed to potential jailbreak risks. Attackers may induce the agents to bypass the original behavioral constraints through specific inputs, and then trigger certain risky and sensitive operations, such as modifying settings, executing unauthorized commands, or impersonating user identities, which brings new challenges to system security. Existing security measures for intelligent agents still have limitations when facing complex interactions, especially in detecting potentially risky behaviors across multiple rounds of conversations or sequences of tasks. In addition, an efficient and consistent automated methodology to assist in assessing and determining the impact of such risks is currently lacking. This work explores the security issues surrounding mobile multimodal agents, attempts to construct a risk discrimination mechanism by incorporating behavioral sequence information, and designs an automated assisted assessment scheme based on a large language model. Through preliminary validation in several representative high-risk tasks, the results show that the method can improve the recognition of risky behaviors to some extent and assist in reducing the probability of agents being jailbroken. We hope that this study can provide some valuable references for the security risk modeling and protection of multimodal intelligent agent systems.
On the Mistaken Assumption of Interchangeable Deep Reinforcement Learning Implementations
Mar 28, 2025Deep Reinforcement Learning (DRL) is a paradigm of artificial intelligence where an agent uses a neural network to learn which actions to take in a given environment. DRL has recently gained traction from being able to solve complex environments like driving simulators, 3D robotic control, and multiplayer-online-battle-arena video games. Numerous implementations of the state-of-the-art algorithms responsible for training these agents, like the Deep Q-Network (DQN) and Proximal Policy Optimization (PPO) algorithms, currently exist. However, studies make the mistake of assuming implementations of the same algorithm to be consistent and thus, interchangeable. In this paper, through a differential testing lens, we present the results of studying the extent of implementation inconsistencies, their effect on the implementations' performance, as well as their impact on the conclusions of prior studies under the assumption of interchangeable implementations. The outcomes of our differential tests showed significant discrepancies between the tested algorithm implementations, indicating that they are not interchangeable. In particular, out of the five PPO implementations tested on 56 games, three implementations achieved superhuman performance for 50% of their total trials while the other two implementations only achieved superhuman performance for less than 15% of their total trials. As part of a meticulous manual analysis of the implementations' source code, we analyzed implementation discrepancies and determined that code-level inconsistencies primarily caused these discrepancies. Lastly, we replicated a study and showed that this assumption of implementation interchangeability was sufficient to flip experiment outcomes. Therefore, this calls for a shift in how implementations are being used.
HiQ-Lip: The First Quantum-Classical Hierarchical Method for Global Lipschitz Constant Estimation of ReLU Networks
Mar 20, 2025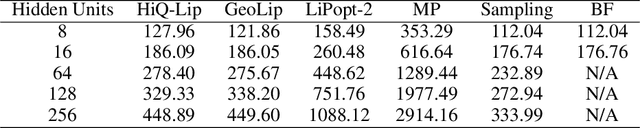
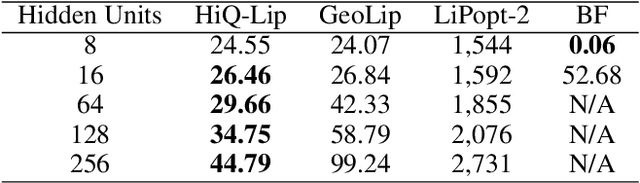
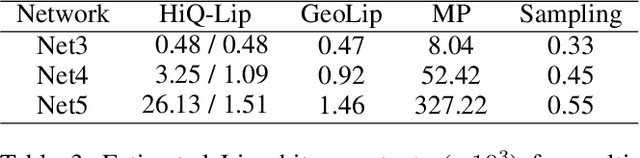

Estimating the global Lipschitz constant of neural networks is crucial for understanding and improving their robustness and generalization capabilities. However, precise calculations are NP-hard, and current semidefinite programming (SDP) methods face challenges such as high memory usage and slow processing speeds. In this paper, we propose \textbf{HiQ-Lip}, a hybrid quantum-classical hierarchical method that leverages Coherent Ising Machines (CIMs) to estimate the global Lipschitz constant. We tackle the estimation by converting it into a Quadratic Unconstrained Binary Optimization (QUBO) problem and implement a multilevel graph coarsening and refinement strategy to adapt to the constraints of contemporary quantum hardware. Our experimental evaluations on fully connected neural networks demonstrate that HiQ-Lip not only provides estimates comparable to state-of-the-art methods but also significantly accelerates the computation process. In specific tests involving two-layer neural networks with 256 hidden neurons, HiQ-Lip doubles the solving speed and offers more accurate upper bounds than the existing best method, LiPopt. These findings highlight the promising utility of small-scale quantum devices in advancing the estimation of neural network robustness.
Probabilistic Quantum SVM Training on Ising Machine
Mar 20, 2025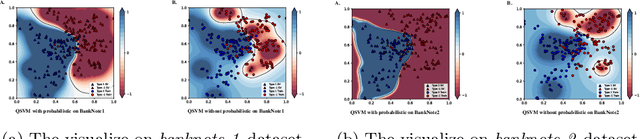
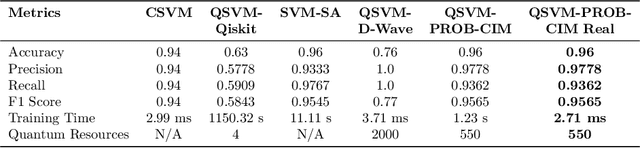
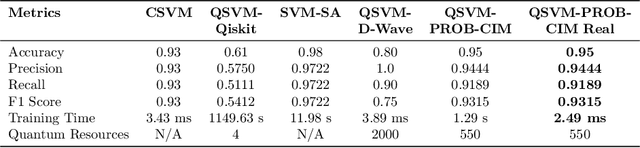
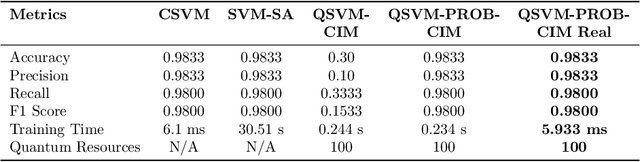
Quantum computing holds significant potential to accelerate machine learning algorithms, especially in solving optimization problems like those encountered in Support Vector Machine (SVM) training. However, current QUBO-based Quantum SVM (QSVM) methods rely solely on binary optimal solutions, limiting their ability to identify fuzzy boundaries in data. Additionally, the limited qubit count in contemporary quantum devices constrains training on larger datasets. In this paper, we propose a probabilistic quantum SVM training framework suitable for Coherent Ising Machines (CIMs). By formulating the SVM training problem as a QUBO model, we leverage CIMs' energy minimization capabilities and introduce a Boltzmann distribution-based probabilistic approach to better approximate optimal SVM solutions, enhancing robustness. To address qubit limitations, we employ batch processing and multi-batch ensemble strategies, enabling small-scale quantum devices to train SVMs on larger datasets and support multi-class classification tasks via a one-vs-one approach. Our method is validated through simulations and real-machine experiments on binary and multi-class datasets. On the banknote binary classification dataset, our CIM-based QSVM, utilizing an energy-based probabilistic approach, achieved up to 20% higher accuracy compared to the original QSVM, while training up to $10^4$ times faster than simulated annealing methods. Compared with classical SVM, our approach either matched or reduced training time. On the IRIS three-class dataset, our improved QSVM outperformed existing QSVM models in all key metrics. As quantum technology advances, increased qubit counts are expected to further enhance QSVM performance relative to classical SVM.
RITFIS: Robust input testing framework for LLMs-based intelligent software
Feb 21, 2024The dependence of Natural Language Processing (NLP) intelligent software on Large Language Models (LLMs) is increasingly prominent, underscoring the necessity for robustness testing. Current testing methods focus solely on the robustness of LLM-based software to prompts. Given the complexity and diversity of real-world inputs, studying the robustness of LLMbased software in handling comprehensive inputs (including prompts and examples) is crucial for a thorough understanding of its performance. To this end, this paper introduces RITFIS, a Robust Input Testing Framework for LLM-based Intelligent Software. To our knowledge, RITFIS is the first framework designed to assess the robustness of LLM-based intelligent software against natural language inputs. This framework, based on given threat models and prompts, primarily defines the testing process as a combinatorial optimization problem. Successful test cases are determined by a goal function, creating a transformation space for the original examples through perturbation means, and employing a series of search methods to filter cases that meet both the testing objectives and language constraints. RITFIS, with its modular design, offers a comprehensive method for evaluating the robustness of LLMbased intelligent software. RITFIS adapts 17 automated testing methods, originally designed for Deep Neural Network (DNN)-based intelligent software, to the LLM-based software testing scenario. It demonstrates the effectiveness of RITFIS in evaluating LLM-based intelligent software through empirical validation. However, existing methods generally have limitations, especially when dealing with lengthy texts and structurally complex threat models. Therefore, we conducted a comprehensive analysis based on five metrics and provided insightful testing method optimization strategies, benefiting both researchers and everyday users.
LEAP: Efficient and Automated Test Method for NLP Software
Aug 22, 2023The widespread adoption of DNNs in NLP software has highlighted the need for robustness. Researchers proposed various automatic testing techniques for adversarial test cases. However, existing methods suffer from two limitations: weak error-discovering capabilities, with success rates ranging from 0% to 24.6% for BERT-based NLP software, and time inefficiency, taking 177.8s to 205.28s per test case, making them challenging for time-constrained scenarios. To address these issues, this paper proposes LEAP, an automated test method that uses LEvy flight-based Adaptive Particle swarm optimization integrated with textual features to generate adversarial test cases. Specifically, we adopt Levy flight for population initialization to increase the diversity of generated test cases. We also design an inertial weight adaptive update operator to improve the efficiency of LEAP's global optimization of high-dimensional text examples and a mutation operator based on the greedy strategy to reduce the search time. We conducted a series of experiments to validate LEAP's ability to test NLP software and found that the average success rate of LEAP in generating adversarial test cases is 79.1%, which is 6.1% higher than the next best approach (PSOattack). While ensuring high success rates, LEAP significantly reduces time overhead by up to 147.6s compared to other heuristic-based methods. Additionally, the experimental results demonstrate that LEAP can generate more transferable test cases and significantly enhance the robustness of DNN-based systems.
Towards Stealthy Backdoor Attacks against Speech Recognition via Elements of Sound
Jul 17, 2023Deep neural networks (DNNs) have been widely and successfully adopted and deployed in various applications of speech recognition. Recently, a few works revealed that these models are vulnerable to backdoor attacks, where the adversaries can implant malicious prediction behaviors into victim models by poisoning their training process. In this paper, we revisit poison-only backdoor attacks against speech recognition. We reveal that existing methods are not stealthy since their trigger patterns are perceptible to humans or machine detection. This limitation is mostly because their trigger patterns are simple noises or separable and distinctive clips. Motivated by these findings, we propose to exploit elements of sound ($e.g.$, pitch and timbre) to design more stealthy yet effective poison-only backdoor attacks. Specifically, we insert a short-duration high-pitched signal as the trigger and increase the pitch of remaining audio clips to `mask' it for designing stealthy pitch-based triggers. We manipulate timbre features of victim audios to design the stealthy timbre-based attack and design a voiceprint selection module to facilitate the multi-backdoor attack. Our attacks can generate more `natural' poisoned samples and therefore are more stealthy. Extensive experiments are conducted on benchmark datasets, which verify the effectiveness of our attacks under different settings ($e.g.$, all-to-one, all-to-all, clean-label, physical, and multi-backdoor settings) and their stealthiness. The code for reproducing main experiments are available at \url{https://github.com/HanboCai/BadSpeech_SoE}.