 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Free-Viewpoint Relighting for Glossy Indirect Illumination
Jul 12, 2023Precomputed Radiance Transfer (PRT) remains an attractive solution for real-time rendering of complex light transport effects such as glossy global illumination. After precomputation, we can relight the scene with new environment maps while changing viewpoint in real-time. However, practical PRT methods are usually limited to low-frequency spherical harmonic lighting. All-frequency techniques using wavelets are promising but have so far had little practical impact. The curse of dimensionality and much higher data requirements have typically limited them to relighting with fixed view or only direct lighting with triple product integrals. In this paper, we demonstrate a hybrid neural-wavelet PRT solution to high-frequency indirect illumination, including glossy reflection, for relighting with changing view. Specifically, we seek to represent the light transport function in the Haar wavelet basis. For global illumination, we learn the wavelet transport using a small multi-layer perceptron (MLP) applied to a feature field as a function of spatial location and wavelet index, with reflected direction and material parameters being other MLP inputs. We optimize/learn the feature field (compactly represented by a tensor decomposition) and MLP parameters from multiple images of the scene under different lighting and viewing conditions. We demonstrate real-time (512 x 512 at 24 FPS, 800 x 600 at 13 FPS) precomputed rendering of challenging scenes involving view-dependent reflections and even caustics.
PVP: Personalized Video Prior for Editable Dynamic Portraits using StyleGAN
Jun 29, 2023Portrait synthesis creates realistic digital avatars which enable users to interact with others in a compelling way. Recent advances in StyleGAN and its extensions have shown promising results in synthesizing photorealistic and accurate reconstruction of human faces. However, previous methods often focus on frontal face synthesis and most methods are not able to handle large head rotations due to the training data distribution of StyleGAN. In this work, our goal is to take as input a monocular video of a face, and create an editable dynamic portrait able to handle extreme head poses. The user can create novel viewpoints, edit the appearance, and animate the face. Our method utilizes pivotal tuning inversion (PTI) to learn a personalized video prior from a monocular video sequence. Then we can input pose and expression coefficients to MLPs and manipulate the latent vectors to synthesize different viewpoints and expressions of the subject. We also propose novel loss functions to further disentangle pose and expression in the latent space. Our algorithm shows much better performance over previous approaches on monocular video datasets, and it is also capable of running in real-time at 54 FPS on an RTX 3080.
NerfDiff: Single-image View Synthesis with NeRF-guided Distillation from 3D-aware Diffusion
Feb 20, 2023



Novel view synthesis from a single image requires inferring occluded regions of objects and scenes whilst simultaneously maintaining semantic and physical consistency with the input. Existing approaches condition neural radiance fields (NeRF) on local image features, projecting points to the input image plane, and aggregating 2D features to perform volume rendering. However, under severe occlusion, this projection fails to resolve uncertainty, resulting in blurry renderings that lack details. In this work, we propose NerfDiff, which addresses this issue by distilling the knowledge of a 3D-aware conditional diffusion model (CDM) into NeRF through synthesizing and refining a set of virtual views at test time. We further propose a novel NeRF-guided distillation algorithm that simultaneously generates 3D consistent virtual views from the CDM samples, and finetunes the NeRF based on the improved virtual views. Our approach significantly outperforms existing NeRF-based and geometry-free approaches on challenging datasets, including ShapeNet, ABO, and Clevr3D.
Vision Transformer for NeRF-Based View Synthesis from a Single Input Image
Jul 12, 2022

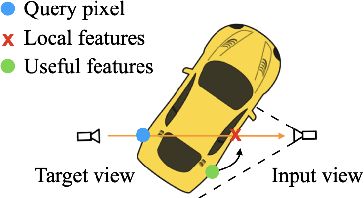
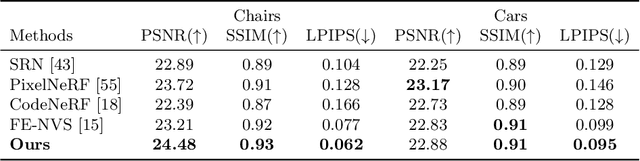
Although neural radiance fields (NeRF) have shown impressive advances for novel view synthesis, most methods typically require multiple input images of the same scene with accurate camera poses. In this work, we seek to substantially reduce the inputs to a single unposed image. Existing approaches condition on local image features to reconstruct a 3D object, but often render blurry predictions at viewpoints that are far away from the source view. To address this issue, we propose to leverage both the global and local features to form an expressive 3D representation. The global features are learned from a vision transformer, while the local features are extracted from a 2D convolutional network. To synthesize a novel view, we train a multilayer perceptron (MLP) network conditioned on the learned 3D representation to perform volume rendering. This novel 3D representation allows the network to reconstruct unseen regions without enforcing constraints like symmetry or canonical coordinate systems. Our method can render novel views from only a single input image and generalize across multiple object categories using a single model. Quantitative and qualitative evaluations demonstrate that the proposed method achieves state-of-the-art performance and renders richer details than existing approaches.
Deep 3D Mask Volume for View Synthesis of Dynamic Scenes
Aug 30, 2021
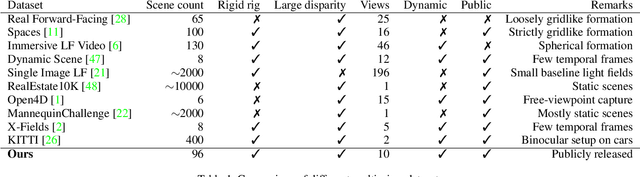


Image view synthesis has seen great success in reconstructing photorealistic visuals, thanks to deep learning and various novel representations. The next key step in immersive virtual experiences is view synthesis of dynamic scenes. However, several challenges exist due to the lack of high-quality training datasets, and the additional time dimension for videos of dynamic scenes. To address this issue, we introduce a multi-view video dataset, captured with a custom 10-camera rig in 120FPS. The dataset contains 96 high-quality scenes showing various visual effects and human interactions in outdoor scenes. We develop a new algorithm, Deep 3D Mask Volume, which enables temporally-stable view extrapolation from binocular videos of dynamic scenes, captured by static cameras. Our algorithm addresses the temporal inconsistency of disocclusions by identifying the error-prone areas with a 3D mask volume, and replaces them with static background observed throughout the video. Our method enables manipulation in 3D space as opposed to simple 2D masks, We demonstrate better temporal stability than frame-by-frame static view synthesis methods, or those that use 2D masks. The resulting view synthesis videos show minimal flickering artifacts and allow for larger translational movements.
NeLF: Neural Light-transport Field for Portrait View Synthesis and Relighting
Jul 26, 2021
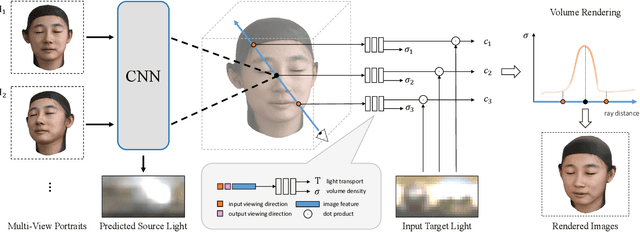
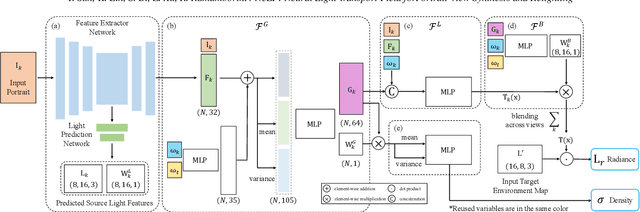
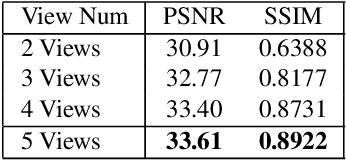
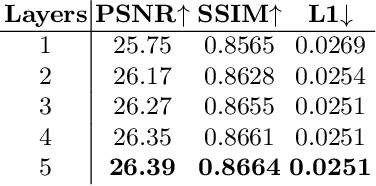
Human portraits exhibit various appearances when observed from different views under different lighting conditions. We can easily imagine how the face will look like in another setup, but computer algorithms still fail on this problem given limited observations. To this end, we present a system for portrait view synthesis and relighting: given multiple portraits, we use a neural network to predict the light-transport field in 3D space, and from the predicted Neural Light-transport Field (NeLF) produce a portrait from a new camera view under a new environmental lighting. Our system is trained on a large number of synthetic models, and can generalize to different synthetic and real portraits under various lighting conditions. Our method achieves simultaneous view synthesis and relighting given multi-view portraits as the input, and achieves state-of-the-art results.
Deep Multi Depth Panoramas for View Synthesis
Aug 04, 2020
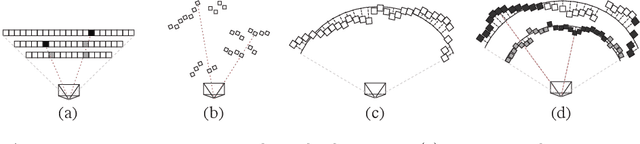

We propose a learning-based approach for novel view synthesis for multi-camera 360$^{\circ}$ panorama capture rigs. Previous work constructs RGBD panoramas from such data, allowing for view synthesis with small amounts of translation, but cannot handle the disocclusions and view-dependent effects that are caused by large translations. To address this issue, we present a novel scene representation - Multi Depth Panorama (MDP) - that consists of multiple RGBD$\alpha$ panoramas that represent both scene geometry and appearance. We demonstrate a deep neural network-based method to reconstruct MDPs from multi-camera 360$^{\circ}$ images. MDPs are more compact than previous 3D scene representations and enable high-quality, efficient new view rendering. We demonstrate this via experiments on both synthetic and real data and comparisons with previous state-of-the-art methods spanning both learning-based approaches and classical RGBD-based methods.