 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefined Geometry-guided Head Avatar Reconstruction from Monocular RGB Video
Mar 27, 2025High-fidelity reconstruction of head avatars from monocular videos is highly desirable for virtual human applications, but it remains a challenge in the fields of computer graphics and computer vision. In this paper, we propose a two-phase head avatar reconstruction network that incorporates a refined 3D mesh representation. Our approach, in contrast to existing methods that rely on coarse template-based 3D representations derived from 3DMM, aims to learn a refined mesh representation suitable for a NeRF that captures complex facial nuances. In the first phase, we train 3DMM-stored NeRF with an initial mesh to utilize geometric priors and integrate observations across frames using a consistent set of latent codes. In the second phase, we leverage a novel mesh refinement procedure based on an SDF constructed from the density field of the initial NeRF. To mitigate the typical noise in the NeRF density field without compromising the features of the 3DMM, we employ Laplace smoothing on the displacement field. Subsequently, we apply a second-phase training with these refined meshes, directing the learning process of the network towards capturing intricate facial details. Our experiments demonstrate that our method further enhances the NeRF rendering based on the initial mesh and achieves performance superior to state-of-the-art methods in reconstructing high-fidelity head avatars with such input.
EdgeRelight360: Text-Conditioned 360-Degree HDR Image Generation for Real-Time On-Device Video Portrait Relighting
Apr 15, 2024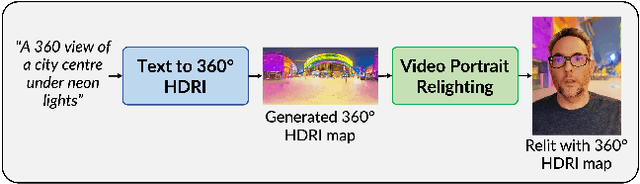
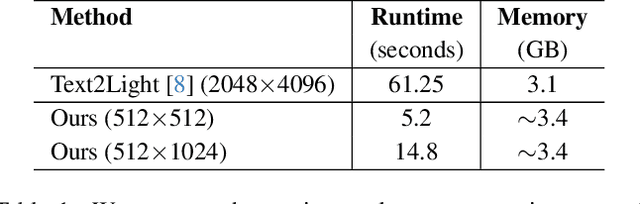
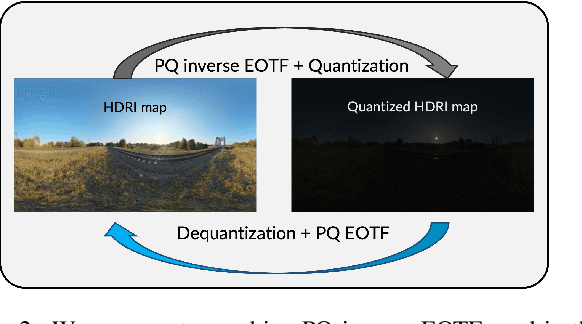

In this paper, we present EdgeRelight360, an approach for real-time video portrait relighting on mobile devices, utilizing text-conditioned generation of 360-degree high dynamic range image (HDRI) maps. Our method proposes a diffusion-based text-to-360-degree image generation in the HDR domain, taking advantage of the HDR10 standard. This technique facilitates the generation of high-quality, realistic lighting conditions from textual descriptions, offering flexibility and control in portrait video relighting task. Unlike the previous relighting frameworks, our proposed system performs video relighting directly on-device, enabling real-time inference with real 360-degree HDRI maps. This on-device processing ensures both privacy and guarantees low runtime, providing an immediate response to changes in lighting conditions or user inputs. Our approach paves the way for new possibilities in real-time video applications, including video conferencing, gaming, and augmented reality, by allowing dynamic, text-based control of lighting conditions.
INFAMOUS-NeRF: ImproviNg FAce MOdeling Using Semantically-Aligned Hypernetworks with Neural Radiance Fields
Dec 23, 2023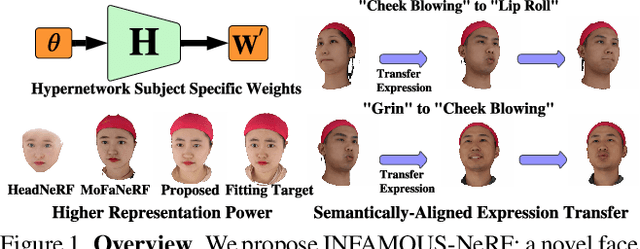
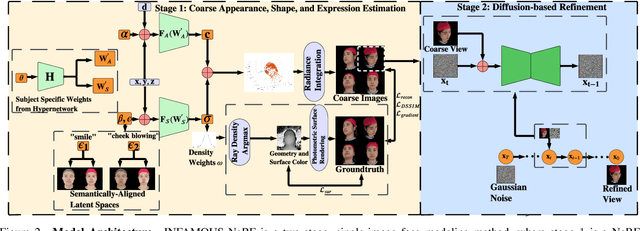


We propose INFAMOUS-NeRF, an implicit morphable face model that introduces hypernetworks to NeRF to improve the representation power in the presence of many training subjects. At the same time, INFAMOUS-NeRF resolves the classic hypernetwork tradeoff of representation power and editability by learning semantically-aligned latent spaces despite the subject-specific models, all without requiring a large pretrained model. INFAMOUS-NeRF further introduces a novel constraint to improve NeRF rendering along the face boundary. Our constraint can leverage photometric surface rendering and multi-view supervision to guide surface color prediction and improve rendering near the surface. Finally, we introduce a novel, loss-guided adaptive sampling method for more effective NeRF training by reducing the sampling redundancy. We show quantitatively and qualitatively that our method achieves higher representation power than prior face modeling methods in both controlled and in-the-wild settings. Code and models will be released upon publication.
PVP: Personalized Video Prior for Editable Dynamic Portraits using StyleGAN
Jun 29, 2023Portrait synthesis creates realistic digital avatars which enable users to interact with others in a compelling way. Recent advances in StyleGAN and its extensions have shown promising results in synthesizing photorealistic and accurate reconstruction of human faces. However, previous methods often focus on frontal face synthesis and most methods are not able to handle large head rotations due to the training data distribution of StyleGAN. In this work, our goal is to take as input a monocular video of a face, and create an editable dynamic portrait able to handle extreme head poses. The user can create novel viewpoints, edit the appearance, and animate the face. Our method utilizes pivotal tuning inversion (PTI) to learn a personalized video prior from a monocular video sequence. Then we can input pose and expression coefficients to MLPs and manipulate the latent vectors to synthesize different viewpoints and expressions of the subject. We also propose novel loss functions to further disentangle pose and expression in the latent space. Our algorithm shows much better performance over previous approaches on monocular video datasets, and it is also capable of running in real-time at 54 FPS on an RTX 3080.
Face Relighting with Geometrically Consistent Shadows
Mar 30, 2022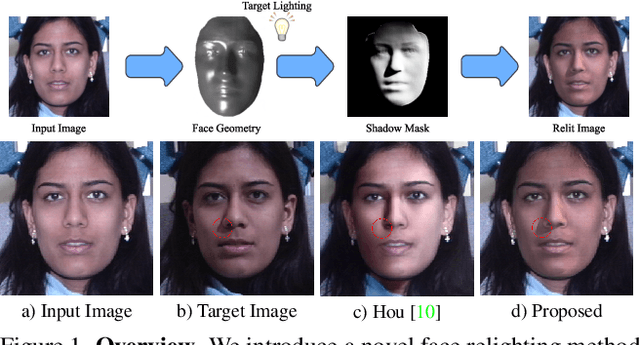
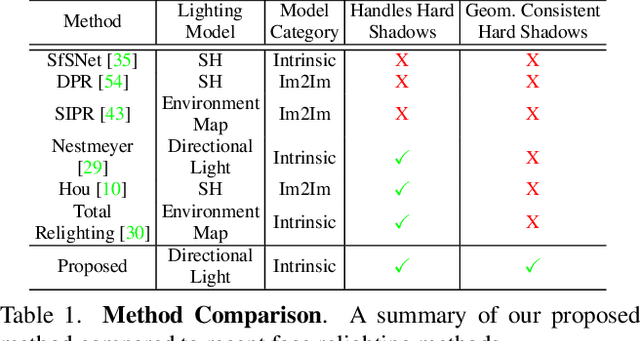
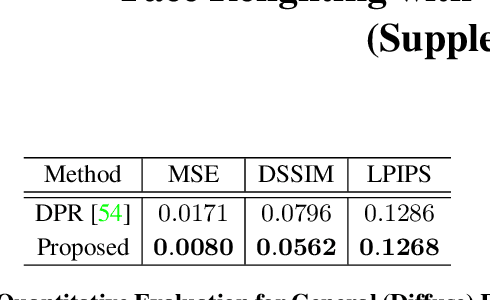

Most face relighting methods are able to handle diffuse shadows, but struggle to handle hard shadows, such as those cast by the nose. Methods that propose techniques for handling hard shadows often do not produce geometrically consistent shadows since they do not directly leverage the estimated face geometry while synthesizing them. We propose a novel differentiable algorithm for synthesizing hard shadows based on ray tracing, which we incorporate into training our face relighting model. Our proposed algorithm directly utilizes the estimated face geometry to synthesize geometrically consistent hard shadows. We demonstrate through quantitative and qualitative experiments on Multi-PIE and FFHQ that our method produces more geometrically consistent shadows than previous face relighting methods while also achieving state-of-the-art face relighting performance under directional lighting. In addition, we demonstrate that our differentiable hard shadow modeling improves the quality of the estimated face geometry over diffuse shading models.
Towards High Fidelity Face Relighting with Realistic Shadows
Apr 02, 2021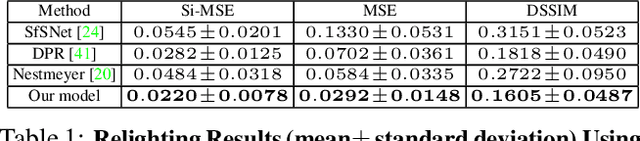


Existing face relighting methods often struggle with two problems: maintaining the local facial details of the subject and accurately removing and synthesizing shadows in the relit image, especially hard shadows. We propose a novel deep face relighting method that addresses both problems. Our method learns to predict the ratio (quotient) image between a source image and the target image with the desired lighting, allowing us to relight the image while maintaining the local facial details. During training, our model also learns to accurately modify shadows by using estimated shadow masks to emphasize on the high-contrast shadow borders. Furthermore, we introduce a method to use the shadow mask to estimate the ambient light intensity in an image, and are thus able to leverage multiple datasets during training with different global lighting intensities. With quantitative and qualitative evaluations on the Multi-PIE and FFHQ datasets, we demonstrate that our proposed method faithfully maintains the local facial details of the subject and can accurately handle hard shadows while achieving state-of-the-art face relighting performance.
Real-Time Selfie Video Stabilization
Sep 04, 2020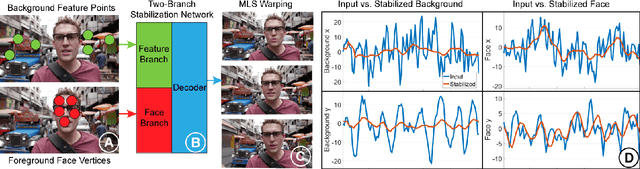

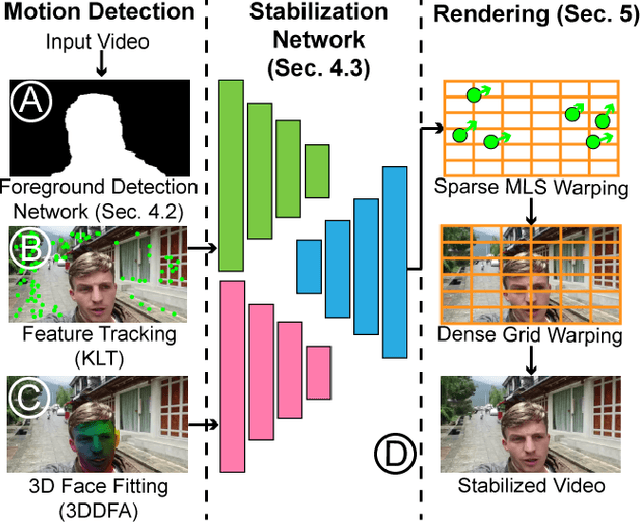
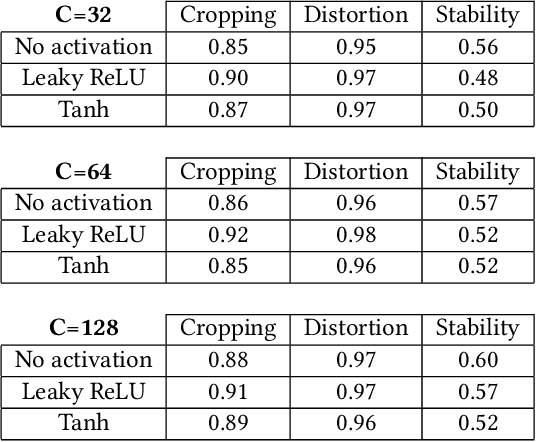
We propose a novel real-time selfie video stabilization method. Our method is completely automatic and runs at 26 fps. We use a 1D linear convolutional network to directly infer the rigid moving least squares warping which implicitly balances between the global rigidity and local flexibility. Our network structure is specifically designed to stabilize the background and foreground at the same time, while providing optional control of stabilization focus (relative importance of foreground vs. background) to the users. To train our network, we collect a selfie video dataset with 1005 videos, which is significantly larger than previous selfie video datasets. We also propose a grid approximation method to the rigid moving least squares warping that enables the real-time frame warping. Our method is fully automatic and produces visually and quantitatively better results than previous real-time general video stabilization methods. Compared to previous offline selfie video methods, our approach produces comparable quality with a speed improvement of orders of magnitude.