 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoTaG: Emotion-Aware Talking Head Synthesis on Gaussian Splatting with Few-Shot Personalization
Mar 22, 2026Audio-driven 3D talking head synthesis has advanced rapidly with Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). By leveraging rich pre-trained priors, few-shot methods enable instant personalization from just a few seconds of video. However, under expressive facial motion, existing few-shot approaches often suffer from geometric instability and audio-emotion mismatch, highlighting the need for more effective emotion-aware motion modeling. In this work, we present EmoTaG, a few-shot emotion-aware 3D talking head synthesis framework built on the Pretrain-and-Adapt paradigm. Our key insight is to reformulate motion prediction in a structured FLAME parameter space rather than directly deforming 3D Gaussians, thereby introducing explicit geometric priors that improve motion stability. Building upon this, we propose a Gated Residual Motion Network (GRMN), which captures emotional prosody from audio while supplementing head pose and upper-face cues absent from audio, enabling expressive and coherent motion generation. Extensive experiments demonstrate that EmoTaG achieves state-of-the-art performance in emotional expressiveness, lip synchronization, visual realism, and motion stability.
PVP: Personalized Video Prior for Editable Dynamic Portraits using StyleGAN
Jun 29, 2023Portrait synthesis creates realistic digital avatars which enable users to interact with others in a compelling way. Recent advances in StyleGAN and its extensions have shown promising results in synthesizing photorealistic and accurate reconstruction of human faces. However, previous methods often focus on frontal face synthesis and most methods are not able to handle large head rotations due to the training data distribution of StyleGAN. In this work, our goal is to take as input a monocular video of a face, and create an editable dynamic portrait able to handle extreme head poses. The user can create novel viewpoints, edit the appearance, and animate the face. Our method utilizes pivotal tuning inversion (PTI) to learn a personalized video prior from a monocular video sequence. Then we can input pose and expression coefficients to MLPs and manipulate the latent vectors to synthesize different viewpoints and expressions of the subject. We also propose novel loss functions to further disentangle pose and expression in the latent space. Our algorithm shows much better performance over previous approaches on monocular video datasets, and it is also capable of running in real-time at 54 FPS on an RTX 3080.
Real-Time Selfie Video Stabilization
Sep 04, 2020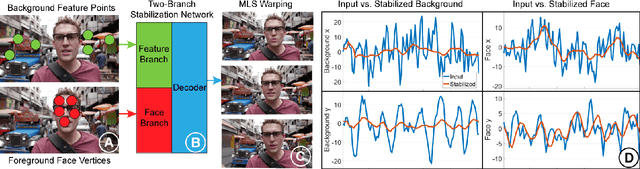

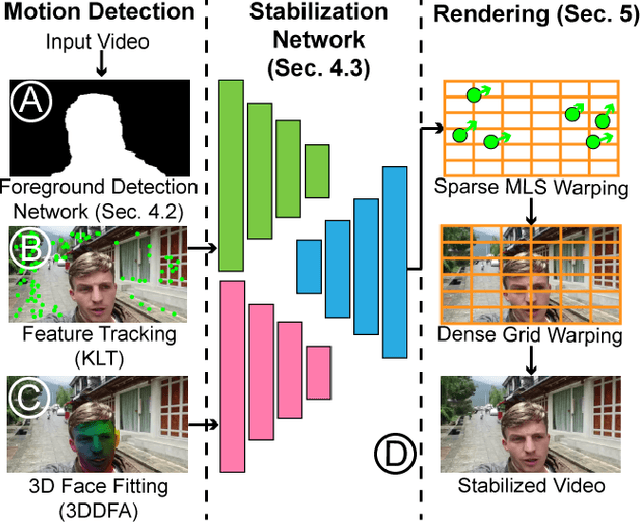
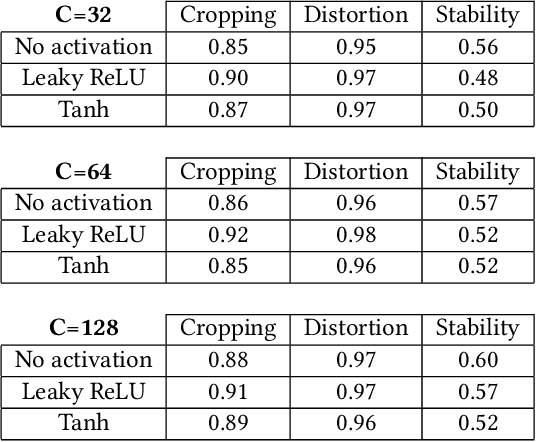
We propose a novel real-time selfie video stabilization method. Our method is completely automatic and runs at 26 fps. We use a 1D linear convolutional network to directly infer the rigid moving least squares warping which implicitly balances between the global rigidity and local flexibility. Our network structure is specifically designed to stabilize the background and foreground at the same time, while providing optional control of stabilization focus (relative importance of foreground vs. background) to the users. To train our network, we collect a selfie video dataset with 1005 videos, which is significantly larger than previous selfie video datasets. We also propose a grid approximation method to the rigid moving least squares warping that enables the real-time frame warping. Our method is fully automatic and produces visually and quantitatively better results than previous real-time general video stabilization methods. Compared to previous offline selfie video methods, our approach produces comparable quality with a speed improvement of orders of magnitude.