 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForeSea: AI Forensic Search with Multi-modal Queries for Video Surveillance
Mar 24, 2026Despite decades of work, surveillance still struggles to find specific targets across long, multi-camera video. Prior methods -- tracking pipelines, CLIP based models, and VideoRAG -- require heavy manual filtering, capture only shallow attributes, and fail at temporal reasoning. Real-world searches are inherently multimodal (e.g., "When does this person join the fight?" with the person's image), yet this setting remains underexplored. Also, there are no proper benchmarks to evaluate those setting - asking video with multimodal queries. To address this gap, we introduce ForeSeaQA, a new benchmark specifically designed for video QA with image-and-text queries and timestamped annotations of key events. The dataset consists of long-horizon surveillance footage paired with diverse multimodal questions, enabling systematic evaluation of retrieval, temporal grounding, and multimodal reasoning in realistic forensic conditions. Not limited to this benchmark, we propose ForeSea, an AI forensic search system with a 3-stage, plug-and-play pipeline. (1) A tracking module filters irrelevant footage; (2) a multimodal embedding module indexes the remaining clips; and (3) during inference, the system retrieves top-K candidate clips for a Video Large Language Model (VideoLLM) to answer queries and localize events. On ForeSeaQA, ForeSea improves accuracy by 3.5% and temporal IoU by 11.0 over prior VideoRAG models. To our knowledge, ForeSeaQA is the first benchmark to support complex multimodal queries with precise temporal grounding, and ForeSea is the first VideoRAG system built to excel in this setting.
EmoTaG: Emotion-Aware Talking Head Synthesis on Gaussian Splatting with Few-Shot Personalization
Mar 22, 2026Audio-driven 3D talking head synthesis has advanced rapidly with Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). By leveraging rich pre-trained priors, few-shot methods enable instant personalization from just a few seconds of video. However, under expressive facial motion, existing few-shot approaches often suffer from geometric instability and audio-emotion mismatch, highlighting the need for more effective emotion-aware motion modeling. In this work, we present EmoTaG, a few-shot emotion-aware 3D talking head synthesis framework built on the Pretrain-and-Adapt paradigm. Our key insight is to reformulate motion prediction in a structured FLAME parameter space rather than directly deforming 3D Gaussians, thereby introducing explicit geometric priors that improve motion stability. Building upon this, we propose a Gated Residual Motion Network (GRMN), which captures emotional prosody from audio while supplementing head pose and upper-face cues absent from audio, enabling expressive and coherent motion generation. Extensive experiments demonstrate that EmoTaG achieves state-of-the-art performance in emotional expressiveness, lip synchronization, visual realism, and motion stability.
HumanOrbit: 3D Human Reconstruction as 360° Orbit Generation
Feb 27, 2026We present a method for generating a full 360° orbit video around a person from a single input image. Existing methods typically adapt image-based diffusion models for multi-view synthesis, but yield inconsistent results across views and with the original identity. In contrast, recent video diffusion models have demonstrated their ability in generating photorealistic results that align well with the given prompts. Inspired by these results, we propose HumanOrbit, a video diffusion model for multi-view human image generation. Our approach enables the model to synthesize continuous camera rotations around the subject, producing geometrically consistent novel views while preserving the appearance and identity of the person. Using the generated multi-view frames, we further propose a reconstruction pipeline that recovers a textured mesh of the subject. Experimental results validate the effectiveness of HumanOrbit for multi-view image generation and that the reconstructed 3D models exhibit superior completeness and fidelity compared to those from state-of-the-art baselines.
AortaDiff: A Unified Multitask Diffusion Framework For Contrast-Free AAA Imaging
Oct 01, 2025While contrast-enhanced CT (CECT) is standard for assessing abdominal aortic aneurysms (AAA), the required iodinated contrast agents pose significant risks, including nephrotoxicity, patient allergies, and environmental harm. To reduce contrast agent use, recent deep learning methods have focused on generating synthetic CECT from non-contrast CT (NCCT) scans. However, most adopt a multi-stage pipeline that first generates images and then performs segmentation, which leads to error accumulation and fails to leverage shared semantic and anatomical structures. To address this, we propose a unified deep learning framework that generates synthetic CECT images from NCCT scans while simultaneously segmenting the aortic lumen and thrombus. Our approach integrates conditional diffusion models (CDM) with multi-task learning, enabling end-to-end joint optimization of image synthesis and anatomical segmentation. Unlike previous multitask diffusion models, our approach requires no initial predictions (e.g., a coarse segmentation mask), shares both encoder and decoder parameters across tasks, and employs a semi-supervised training strategy to learn from scans with missing segmentation labels, a common constraint in real-world clinical data. We evaluated our method on a cohort of 264 patients, where it consistently outperformed state-of-the-art single-task and multi-stage models. For image synthesis, our model achieved a PSNR of 25.61 dB, compared to 23.80 dB from a single-task CDM. For anatomical segmentation, it improved the lumen Dice score to 0.89 from 0.87 and the challenging thrombus Dice score to 0.53 from 0.48 (nnU-Net). These segmentation enhancements led to more accurate clinical measurements, reducing the lumen diameter MAE to 4.19 mm from 5.78 mm and the thrombus area error to 33.85% from 41.45% when compared to nnU-Net. Code is available at https://github.com/yuxuanou623/AortaDiff.git.
EgoPrivacy: What Your First-Person Camera Says About You?
Jun 13, 2025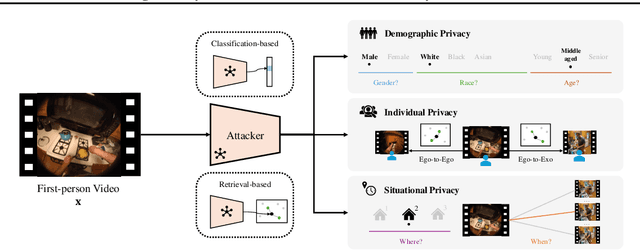
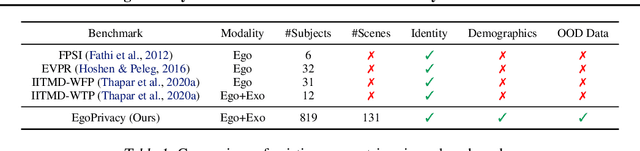
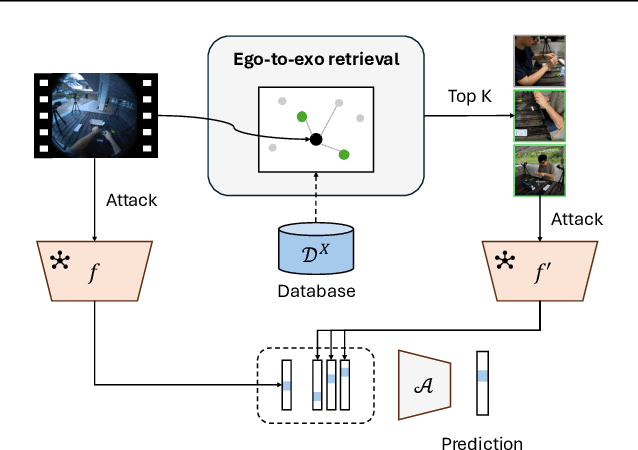
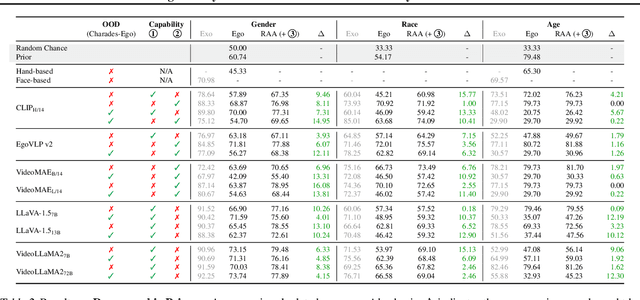
While the rapid proliferation of wearable cameras has raised significant concerns about egocentric video privacy, prior work has largely overlooked the unique privacy threats posed to the camera wearer. This work investigates the core question: How much privacy information about the camera wearer can be inferred from their first-person view videos? We introduce EgoPrivacy, the first large-scale benchmark for the comprehensive evaluation of privacy risks in egocentric vision. EgoPrivacy covers three types of privacy (demographic, individual, and situational), defining seven tasks that aim to recover private information ranging from fine-grained (e.g., wearer's identity) to coarse-grained (e.g., age group). To further emphasize the privacy threats inherent to egocentric vision, we propose Retrieval-Augmented Attack, a novel attack strategy that leverages ego-to-exo retrieval from an external pool of exocentric videos to boost the effectiveness of demographic privacy attacks. An extensive comparison of the different attacks possible under all threat models is presented, showing that private information of the wearer is highly susceptible to leakage. For instance, our findings indicate that foundation models can effectively compromise wearer privacy even in zero-shot settings by recovering attributes such as identity, scene, gender, and race with 70-80% accuracy. Our code and data are available at https://github.com/williamium3000/ego-privacy.
Refined Geometry-guided Head Avatar Reconstruction from Monocular RGB Video
Mar 27, 2025High-fidelity reconstruction of head avatars from monocular videos is highly desirable for virtual human applications, but it remains a challenge in the fields of computer graphics and computer vision. In this paper, we propose a two-phase head avatar reconstruction network that incorporates a refined 3D mesh representation. Our approach, in contrast to existing methods that rely on coarse template-based 3D representations derived from 3DMM, aims to learn a refined mesh representation suitable for a NeRF that captures complex facial nuances. In the first phase, we train 3DMM-stored NeRF with an initial mesh to utilize geometric priors and integrate observations across frames using a consistent set of latent codes. In the second phase, we leverage a novel mesh refinement procedure based on an SDF constructed from the density field of the initial NeRF. To mitigate the typical noise in the NeRF density field without compromising the features of the 3DMM, we employ Laplace smoothing on the displacement field. Subsequently, we apply a second-phase training with these refined meshes, directing the learning process of the network towards capturing intricate facial details. Our experiments demonstrate that our method further enhances the NeRF rendering based on the initial mesh and achieves performance superior to state-of-the-art methods in reconstructing high-fidelity head avatars with such input.
EdgeRelight360: Text-Conditioned 360-Degree HDR Image Generation for Real-Time On-Device Video Portrait Relighting
Apr 15, 2024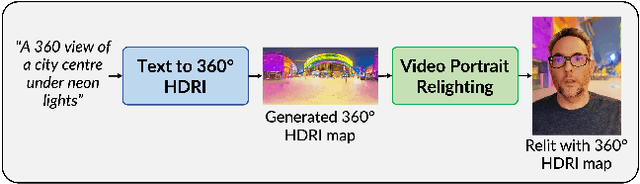
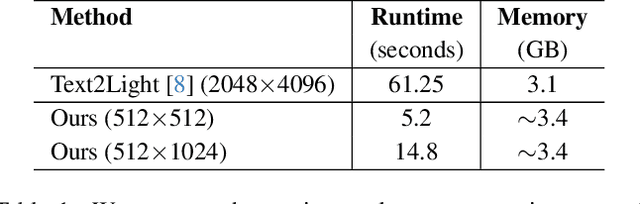
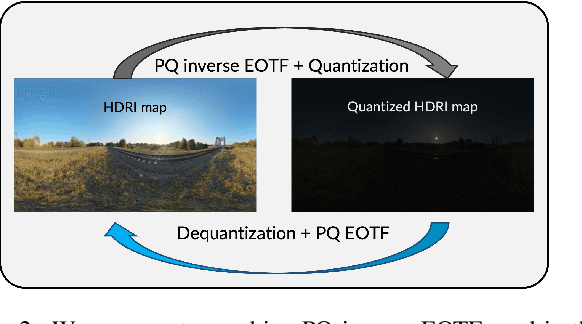

In this paper, we present EdgeRelight360, an approach for real-time video portrait relighting on mobile devices, utilizing text-conditioned generation of 360-degree high dynamic range image (HDRI) maps. Our method proposes a diffusion-based text-to-360-degree image generation in the HDR domain, taking advantage of the HDR10 standard. This technique facilitates the generation of high-quality, realistic lighting conditions from textual descriptions, offering flexibility and control in portrait video relighting task. Unlike the previous relighting frameworks, our proposed system performs video relighting directly on-device, enabling real-time inference with real 360-degree HDRI maps. This on-device processing ensures both privacy and guarantees low runtime, providing an immediate response to changes in lighting conditions or user inputs. Our approach paves the way for new possibilities in real-time video applications, including video conferencing, gaming, and augmented reality, by allowing dynamic, text-based control of lighting conditions.
AUEditNet: Dual-Branch Facial Action Unit Intensity Manipulation with Implicit Disentanglement
Apr 10, 2024Facial action unit (AU) intensity plays a pivotal role in quantifying fine-grained expression behaviors, which is an effective condition for facial expression manipulation. However, publicly available datasets containing intensity annotations for multiple AUs remain severely limited, often featuring a restricted number of subjects. This limitation places challenges to the AU intensity manipulation in images due to disentanglement issues, leading researchers to resort to other large datasets with pretrained AU intensity estimators for pseudo labels. In addressing this constraint and fully leveraging manual annotations of AU intensities for precise manipulation, we introduce AUEditNet. Our proposed model achieves impressive intensity manipulation across 12 AUs, trained effectively with only 18 subjects. Utilizing a dual-branch architecture, our approach achieves comprehensive disentanglement of facial attributes and identity without necessitating additional loss functions or implementing with large batch sizes. This approach offers a potential solution to achieve desired facial attribute editing despite the dataset's limited subject count. Our experiments demonstrate AUEditNet's superior accuracy in editing AU intensities, affirming its capability in disentangling facial attributes and identity within a limited subject pool. AUEditNet allows conditioning by either intensity values or target images, eliminating the need for constructing AU combinations for specific facial expression synthesis. Moreover, AU intensity estimation, as a downstream task, validates the consistency between real and edited images, confirming the effectiveness of our proposed AU intensity manipulation method.
INFAMOUS-NeRF: ImproviNg FAce MOdeling Using Semantically-Aligned Hypernetworks with Neural Radiance Fields
Dec 23, 2023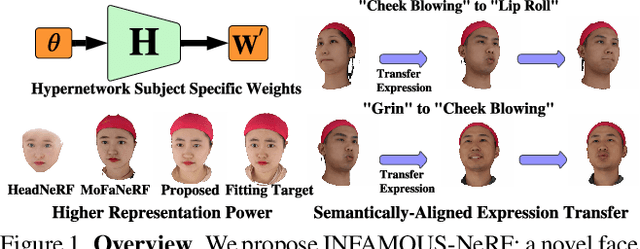
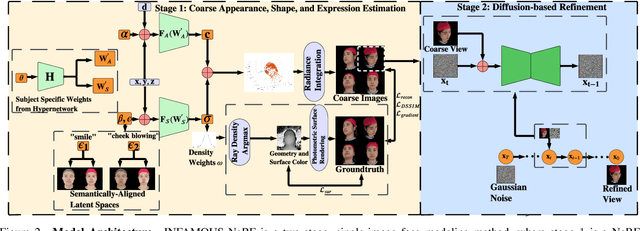


We propose INFAMOUS-NeRF, an implicit morphable face model that introduces hypernetworks to NeRF to improve the representation power in the presence of many training subjects. At the same time, INFAMOUS-NeRF resolves the classic hypernetwork tradeoff of representation power and editability by learning semantically-aligned latent spaces despite the subject-specific models, all without requiring a large pretrained model. INFAMOUS-NeRF further introduces a novel constraint to improve NeRF rendering along the face boundary. Our constraint can leverage photometric surface rendering and multi-view supervision to guide surface color prediction and improve rendering near the surface. Finally, we introduce a novel, loss-guided adaptive sampling method for more effective NeRF training by reducing the sampling redundancy. We show quantitatively and qualitatively that our method achieves higher representation power than prior face modeling methods in both controlled and in-the-wild settings. Code and models will be released upon publication.
PVP: Personalized Video Prior for Editable Dynamic Portraits using StyleGAN
Jun 29, 2023Portrait synthesis creates realistic digital avatars which enable users to interact with others in a compelling way. Recent advances in StyleGAN and its extensions have shown promising results in synthesizing photorealistic and accurate reconstruction of human faces. However, previous methods often focus on frontal face synthesis and most methods are not able to handle large head rotations due to the training data distribution of StyleGAN. In this work, our goal is to take as input a monocular video of a face, and create an editable dynamic portrait able to handle extreme head poses. The user can create novel viewpoints, edit the appearance, and animate the face. Our method utilizes pivotal tuning inversion (PTI) to learn a personalized video prior from a monocular video sequence. Then we can input pose and expression coefficients to MLPs and manipulate the latent vectors to synthesize different viewpoints and expressions of the subject. We also propose novel loss functions to further disentangle pose and expression in the latent space. Our algorithm shows much better performance over previous approaches on monocular video datasets, and it is also capable of running in real-time at 54 FPS on an RTX 3080.