 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtility-Aware Progressive Inference over UDP Packet Blocks for Emergency Communications
May 11, 2026Emergency communications increasingly rely on remote visual inference for timely hazard detection under stringent bandwidth and latency constraints. However, conventional UDP-based visual delivery typically performs inference only after the full payload has been received, even though partially received packet blocks may already contain sufficient task-relevant evidence for reliable decision making. This paper proposes a utility-aware progressive inference framework for emergency communications, which operates directly on UDP packet blocks and determines when sufficient task value has been accumulated for early hazard recognition. Specifically, the sender estimates packet-level decision utility as lightweight control metadata, while the receiver progressively updates partial observations, accumulates the utility of received packets, and triggers an early stop once the normalized utility exceeds a prescribed threshold. Experiments on a fire-scene detection dataset show that, at the main operating point, the proposed method reduces the average packet budget by 34.2% and the decision delay by 1209.17 ms while retaining 91.5% of the full-reception match rate. The method also maintains its advantage over the stability-based baseline under moderate packet loss and different packet-arrival orders. These results demonstrate that packet-level utility provides an effective basis for communication-efficient and delay-aware hazard recognition over UDP-based emergency links.
ReaGeo: Reasoning-Enhanced End-to-End Geocoding with LLMs
Apr 23, 2026This paper proposes ReaGeo, an end-to-end geocoding framework based on large language models, designed to overcome the limitations of traditional multi-stage approaches that rely on text or vector similarity retrieval over geographic databases, including workflow complexity, error propagation, and heavy dependence on structured geographic knowledge bases. The method converts geographic coordinates into geohash sequences, reformulating the coordinate prediction task as a text generation problem, and introduces a Chain-of-Thought mechanism to enhance the model's reasoning over spatial relationships. Furthermore, reinforcement learning with a distance-deviation-based reward is applied to optimize the generation accuracy. Comprehensive experiments show that ReaGeo can accurately handle explicit address queries in single-point predictions and effectively resolve vague relative location queries. In addition, the model demonstrates strong predictive capability for non-point geometric regions, highlighting its versatility and generalization ability in geocoding tasks.
Artic: AI-oriented Real-time Communication for MLLM Video Assistant
Feb 13, 2026AI Video Assistant emerges as a new paradigm for Real-time Communication (RTC), where one peer is a Multimodal Large Language Model (MLLM) deployed in the cloud. This makes interaction between humans and AI more intuitive, akin to chatting with a real person. However, a fundamental mismatch exists between current RTC frameworks and AI Video Assistants, stemming from the drastic shift in Quality of Experience (QoE) and more challenging networks. Measurements on our production prototype also confirm that current RTC fails, causing latency spikes and accuracy drops. To address these challenges, we propose Artic, an AI-oriented RTC framework for MLLM Video Assistants, exploring the shift from "humans watching video" to "AI understanding video." Specifically, Artic proposes: (1) Response Capability-aware Adaptive Bitrate, which utilizes MLLM accuracy saturation to proactively cap bitrate, reserving bandwidth headroom to absorb future fluctuations for latency reduction; (2) Zero-overhead Context-aware Streaming, which allocates limited bitrate to regions most important for the response, maintaining accuracy even under ultra-low bitrates; and (3) Degraded Video Understanding Benchmark, the first benchmark evaluating how RTC-induced video degradation affects MLLM accuracy. Prototype experiments using real-world uplink traces show that compared with existing methods, Artic significantly improves accuracy by 15.12% and reduces latency by 135.31 ms. We will release the benchmark and codes at https://github.com/pku-netvideo/DeViBench.
OrientDream: Streamlining Text-to-3D Generation with Explicit Orientation Control
Jun 14, 2024



In the evolving landscape of text-to-3D technology, Dreamfusion has showcased its proficiency by utilizing Score Distillation Sampling (SDS) to optimize implicit representations such as NeRF. This process is achieved through the distillation of pretrained large-scale text-to-image diffusion models. However, Dreamfusion encounters fidelity and efficiency constraints: it faces the multi-head Janus issue and exhibits a relatively slow optimization process. To circumvent these challenges, we introduce OrientDream, a camera orientation conditioned framework designed for efficient and multi-view consistent 3D generation from textual prompts. Our strategy emphasizes the implementation of an explicit camera orientation conditioned feature in the pre-training of a 2D text-to-image diffusion module. This feature effectively utilizes data from MVImgNet, an extensive external multi-view dataset, to refine and bolster its functionality. Subsequently, we utilize the pre-conditioned 2D images as a basis for optimizing a randomly initialized implicit representation (NeRF). This process is significantly expedited by a decoupled back-propagation technique, allowing for multiple updates of implicit parameters per optimization cycle. Our experiments reveal that our method not only produces high-quality NeRF models with consistent multi-view properties but also achieves an optimization speed significantly greater than existing methods, as quantified by comparative metrics.
OAM-SWIPT for IoE-Driven 6G
Jun 08, 2024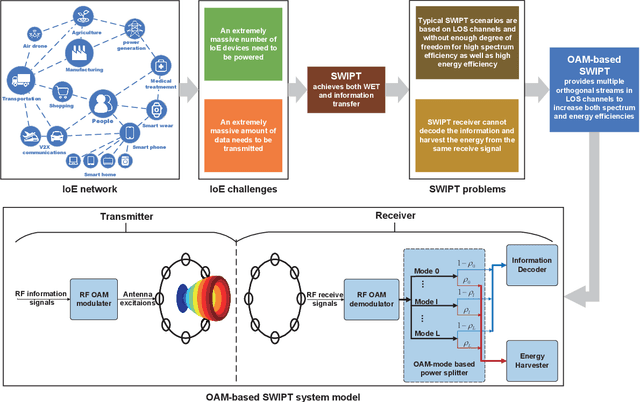
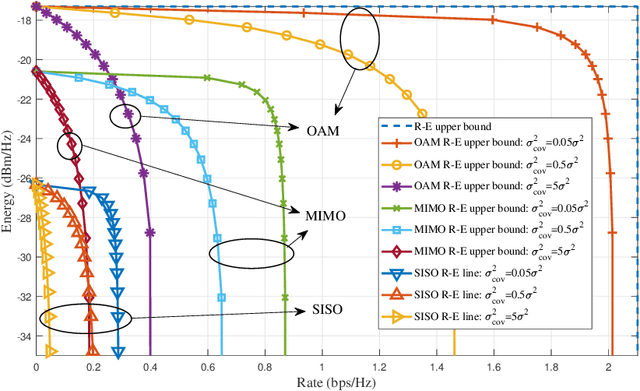
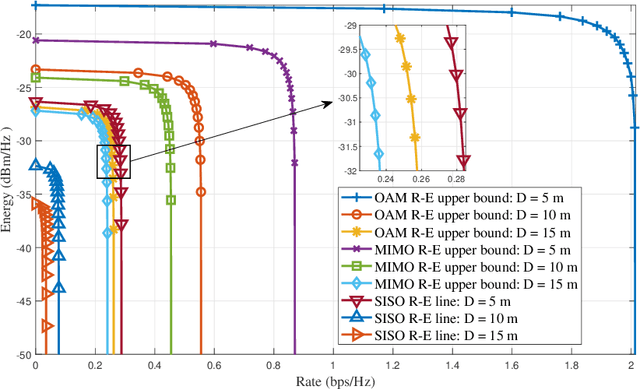
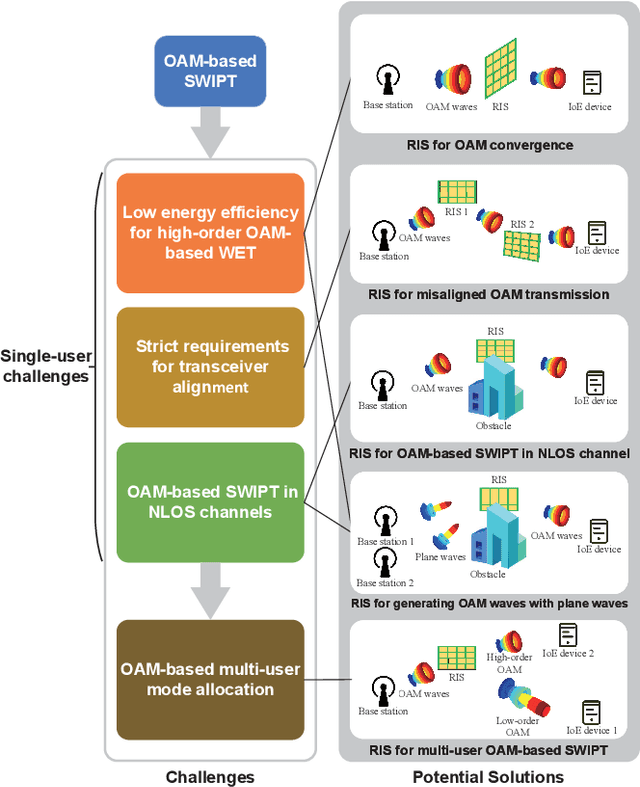
Simultaneous wireless information and power transfer (SWIPT), which achieves both wireless energy transfer (WET) and information transfer, is an attractive technique for future Internet of Everything (IoE) in the sixth-generation (6G) mobile communications. With SWIPT, battery-less IoE devices can be powered while communicating with other devices. Line-of-sight (LOS) RF transmission and near-field inductive coupling based transmission are typical SWIPT scenarios, which are both LOS channels and without enough degree of freedom for high spectrum efficiency as well as high energy efficiency. Due to the orthogonal wavefronts, orbital angular momentum (OAM) can facilitate the SWIPT in LOS channels. In this article, we introduce the OAM-based SWIPT as well as discuss some basic advantages and challenges for it. After introducing the OAM-based SWIPT for IoE, we first propose an OAM-based SWIPT system model with the OAM-modes assisted dynamic power splitting (DPS). Then, four basic advantages regarding the OAM-based SWIPT are reviewed with some numerical analyses for further demonstrating the advantages. Next, four challenges regarding integrating OAM into SWIPT and possible solutions are discussed. OAM technology provides multiple orthogonal streams to increase both spectrum and energy efficiencies for SWIPT, thus creating many opportunities for future WET and SWIPT researches.
* 7 pages, 6 figures
INFAMOUS-NeRF: ImproviNg FAce MOdeling Using Semantically-Aligned Hypernetworks with Neural Radiance Fields
Dec 23, 2023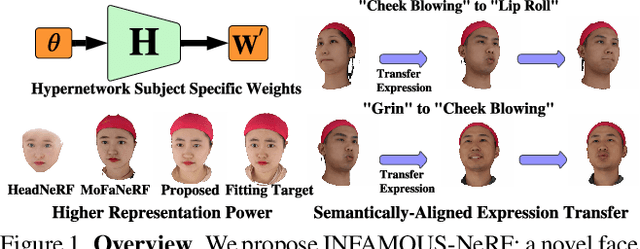
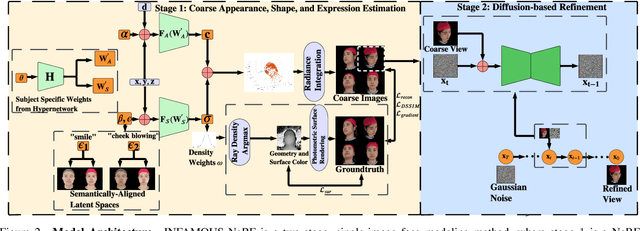


We propose INFAMOUS-NeRF, an implicit morphable face model that introduces hypernetworks to NeRF to improve the representation power in the presence of many training subjects. At the same time, INFAMOUS-NeRF resolves the classic hypernetwork tradeoff of representation power and editability by learning semantically-aligned latent spaces despite the subject-specific models, all without requiring a large pretrained model. INFAMOUS-NeRF further introduces a novel constraint to improve NeRF rendering along the face boundary. Our constraint can leverage photometric surface rendering and multi-view supervision to guide surface color prediction and improve rendering near the surface. Finally, we introduce a novel, loss-guided adaptive sampling method for more effective NeRF training by reducing the sampling redundancy. We show quantitatively and qualitatively that our method achieves higher representation power than prior face modeling methods in both controlled and in-the-wild settings. Code and models will be released upon publication.
ChatGPT-Powered Hierarchical Comparisons for Image Classification
Nov 01, 2023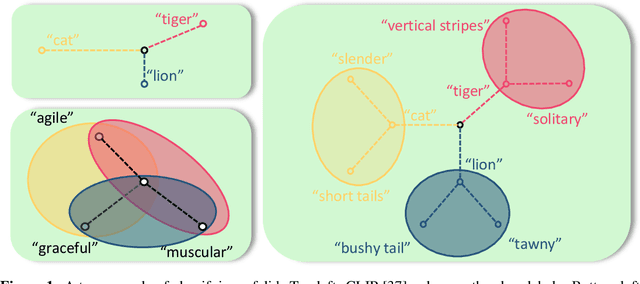
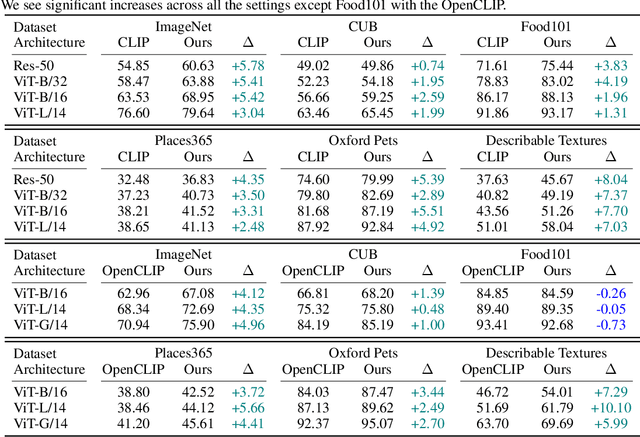
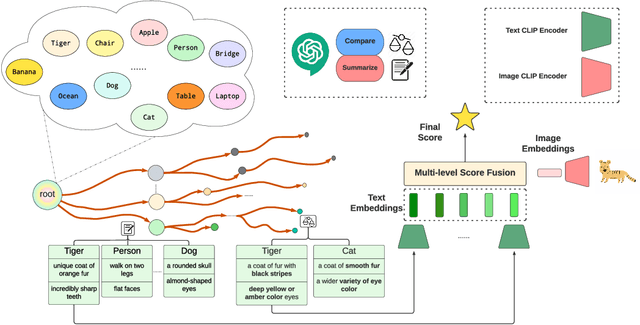
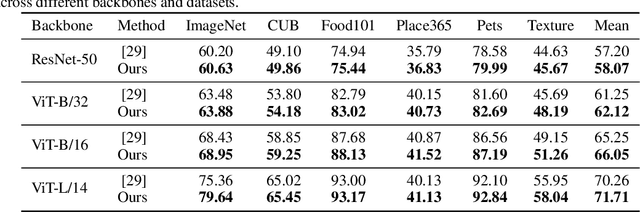
The zero-shot open-vocabulary challenge in image classification is tackled by pretrained vision-language models like CLIP, which benefit from incorporating class-specific knowledge from large language models (LLMs) like ChatGPT. However, biases in CLIP lead to similar descriptions for distinct but related classes, prompting our novel image classification framework via hierarchical comparisons: using LLMs to recursively group classes into hierarchies and classifying images by comparing image-text embeddings at each hierarchy level, resulting in an intuitive, effective, and explainable approach.
FarSight: A Physics-Driven Whole-Body Biometric System at Large Distance and Altitude
Jun 29, 2023



Whole-body biometric recognition is an important area of research due to its vast applications in law enforcement, border security, and surveillance. This paper presents the end-to-end design, development and evaluation of FarSight, an innovative software system designed for whole-body (fusion of face, gait and body shape) biometric recognition. FarSight accepts videos from elevated platforms and drones as input and outputs a candidate list of identities from a gallery. The system is designed to address several challenges, including (i) low-quality imagery, (ii) large yaw and pitch angles, (iii) robust feature extraction to accommodate large intra-person variabilities and large inter-person similarities, and (iv) the large domain gap between training and test sets. FarSight combines the physics of imaging and deep learning models to enhance image restoration and biometric feature encoding. We test FarSight's effectiveness using the newly acquired IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) dataset. Notably, FarSight demonstrated a substantial performance increase on the BRIAR dataset, with gains of +11.82% Rank-20 identification and +11.3% TAR@1% FAR.
Hierarchical Fine-Grained Image Forgery Detection and Localization
Mar 30, 2023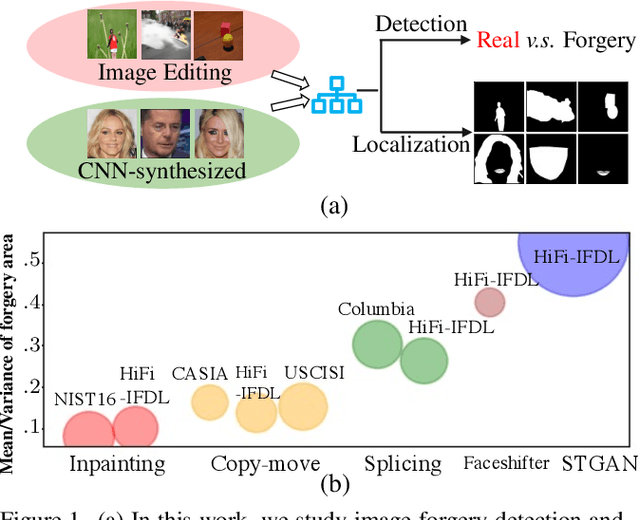
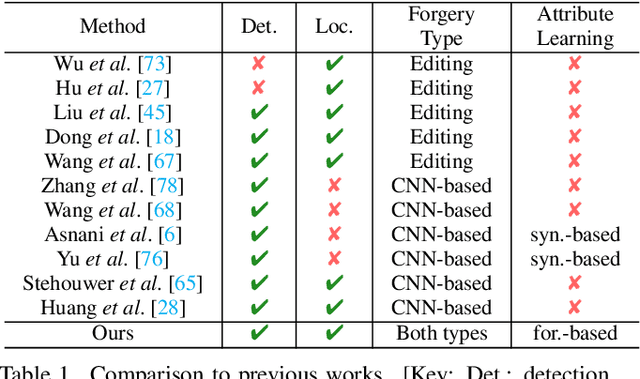
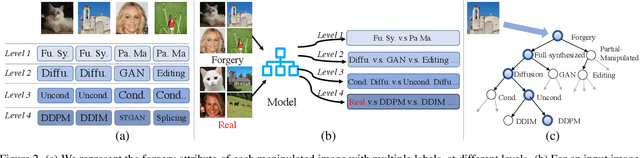
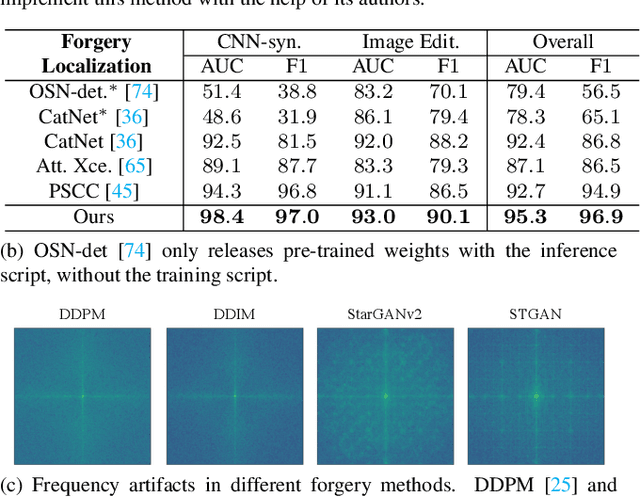
Differences in forgery attributes of images generated in CNN-synthesized and image-editing domains are large, and such differences make a unified image forgery detection and localization (IFDL) challenging. To this end, we present a hierarchical fine-grained formulation for IFDL representation learning. Specifically, we first represent forgery attributes of a manipulated image with multiple labels at different levels. Then we perform fine-grained classification at these levels using the hierarchical dependency between them. As a result, the algorithm is encouraged to learn both comprehensive features and inherent hierarchical nature of different forgery attributes, thereby improving the IFDL representation. Our proposed IFDL framework contains three components: multi-branch feature extractor, localization and classification modules. Each branch of the feature extractor learns to classify forgery attributes at one level, while localization and classification modules segment the pixel-level forgery region and detect image-level forgery, respectively. Lastly, we construct a hierarchical fine-grained dataset to facilitate our study. We demonstrate the effectiveness of our method on $7$ different benchmarks, for both tasks of IFDL and forgery attribute classification. Our source code and dataset can be found: \href{https://github.com/CHELSEA234/HiFi_IFDL}{github.com/CHELSEA234/HiFi-IFDL}.
Efficient Human Pose Estimation by Maximizing Fusion and High-Level Spatial Attention
Jul 29, 2021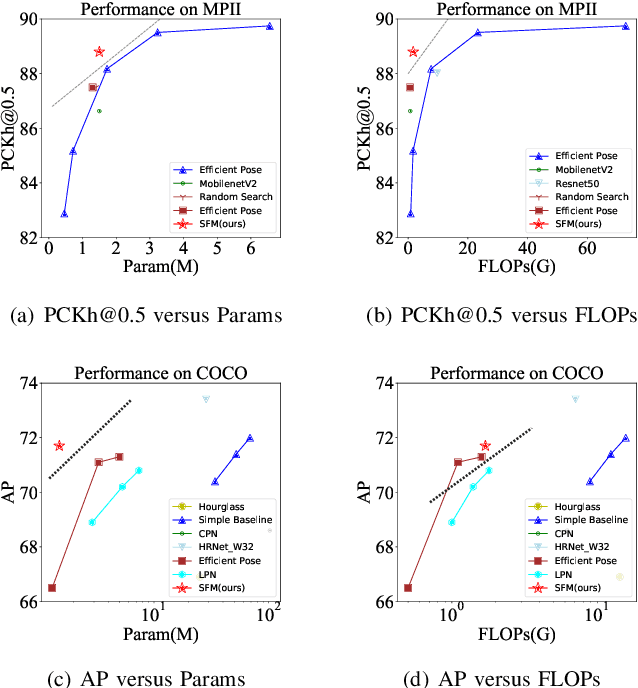
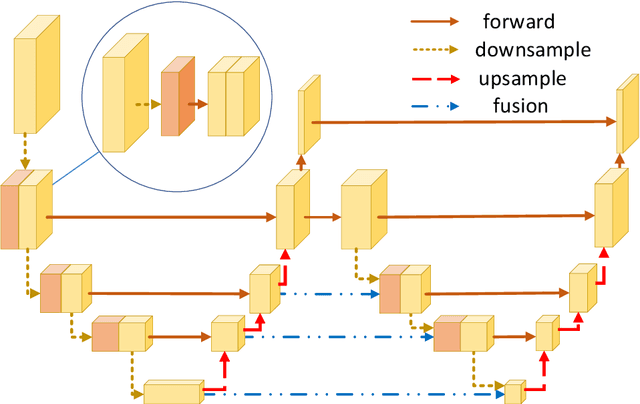
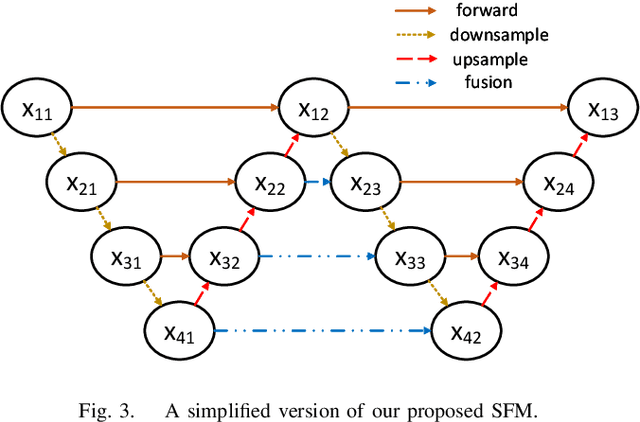
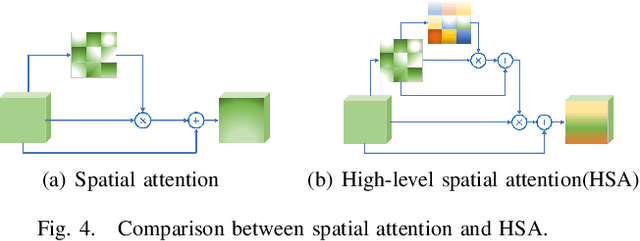
In this paper, we propose an efficient human pose estimation network -- SFM (slender fusion model) by fusing multi-level features and adding lightweight attention blocks -- HSA (High-Level Spatial Attention). Many existing methods on efficient network have already taken feature fusion into consideration, which largely boosts the performance. However, its performance is far inferior to large network such as ResNet and HRNet due to its limited fusion operation in the network. Specifically, we expand the number of fusion operation by building bridges between two pyramid frameworks without adding layers. Meanwhile, to capture long-range dependency, we propose a lightweight attention block -- HSA, which computes second-order attention map. In summary, SFM maximizes the number of feature fusion in a limited number of layers. HSA learns high precise spatial information by computing the attention of spatial attention map. With the help of SFM and HSA, our network is able to generate multi-level feature and extract precise global spatial information with little computing resource. Thus, our method achieve comparable or even better accuracy with less parameters and computational cost. Our SFM achieve 89.0 in PCKh@0.5, 42.0 in PCKh@0.1 on MPII validation set and 71.7 in AP, 90.7 in AP@0.5 on COCO validation with only 1.7G FLOPs and 1.5M parameters. The source code will be public soon.