 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$π$-Tuning: Transferring Multimodal Foundation Models with Optimal Multi-task Interpolation
Apr 28, 2023Foundation models have achieved great advances in multi-task learning with a unified interface of unimodal and multimodal tasks. However, the potential of such multi-task learners has not been exploited during transfer learning. In this work, we present a universal parameter-efficient transfer learning method, termed Predict-Interpolate Tuning ($\pi$-Tuning), for vision, language, and vision-language tasks. It aggregates the parameters of lightweight task-specific experts learned from similar tasks to aid the target downstream task. The task similarities are predicted in a unified modality-independent space, yielding a scalable graph to demonstrate task relationships. $\pi$-Tuning has several appealing benefits. First, it flexibly explores both intra- and inter-modal transferability between similar tasks to improve the accuracy and robustness of transfer learning, especially in data-scarce scenarios. Second, it offers a systematical solution for transfer learning with multi-task prediction-and-then-interpolation, compatible with diverse types of parameter-efficient experts, such as prompt and adapter. Third, an extensive study of task-level mutual benefits on 14 unimodal and 6 multimodal datasets shows that $\pi$-Tuning surpasses fine-tuning and other parameter-efficient transfer learning methods both in full-shot and low-shot regimes. The task graph also enables an in-depth interpretable analysis of task transferability across modalities.
Efficient Human Pose Estimation by Maximizing Fusion and High-Level Spatial Attention
Jul 29, 2021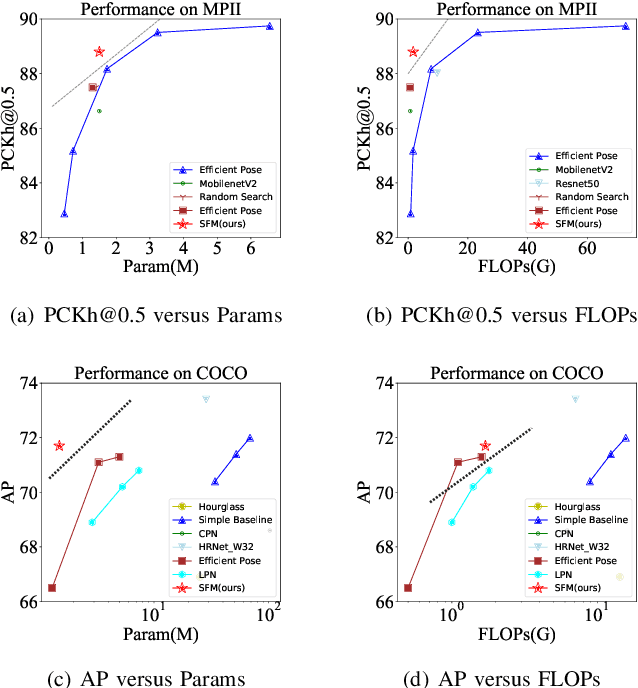
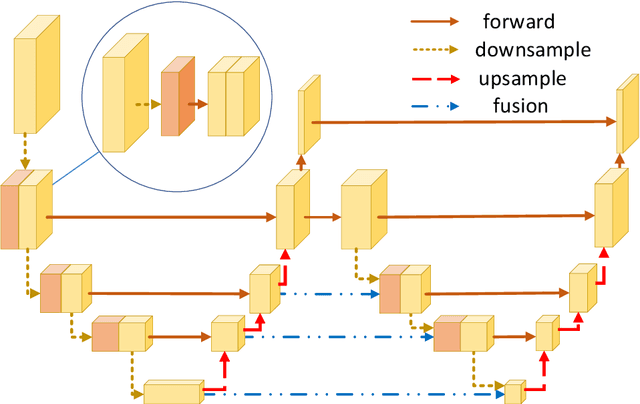
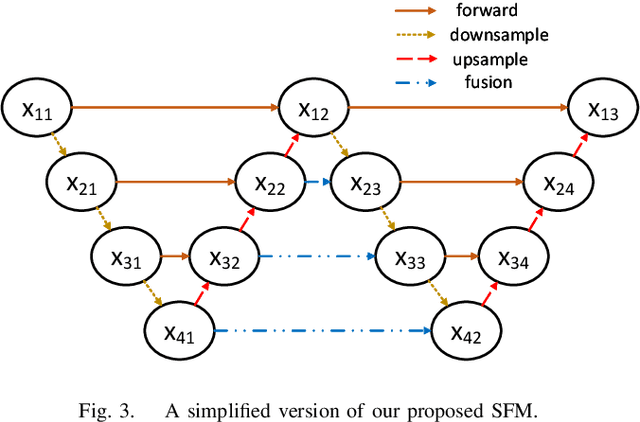
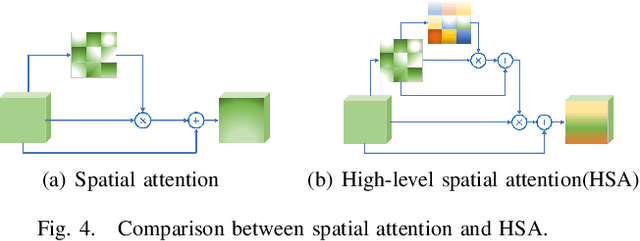
In this paper, we propose an efficient human pose estimation network -- SFM (slender fusion model) by fusing multi-level features and adding lightweight attention blocks -- HSA (High-Level Spatial Attention). Many existing methods on efficient network have already taken feature fusion into consideration, which largely boosts the performance. However, its performance is far inferior to large network such as ResNet and HRNet due to its limited fusion operation in the network. Specifically, we expand the number of fusion operation by building bridges between two pyramid frameworks without adding layers. Meanwhile, to capture long-range dependency, we propose a lightweight attention block -- HSA, which computes second-order attention map. In summary, SFM maximizes the number of feature fusion in a limited number of layers. HSA learns high precise spatial information by computing the attention of spatial attention map. With the help of SFM and HSA, our network is able to generate multi-level feature and extract precise global spatial information with little computing resource. Thus, our method achieve comparable or even better accuracy with less parameters and computational cost. Our SFM achieve 89.0 in PCKh@0.5, 42.0 in PCKh@0.1 on MPII validation set and 71.7 in AP, 90.7 in AP@0.5 on COCO validation with only 1.7G FLOPs and 1.5M parameters. The source code will be public soon.
Multi-Modal Active Learning for Automatic Liver Fibrosis Diagnosis based on Ultrasound Shear Wave Elastography
Nov 02, 2020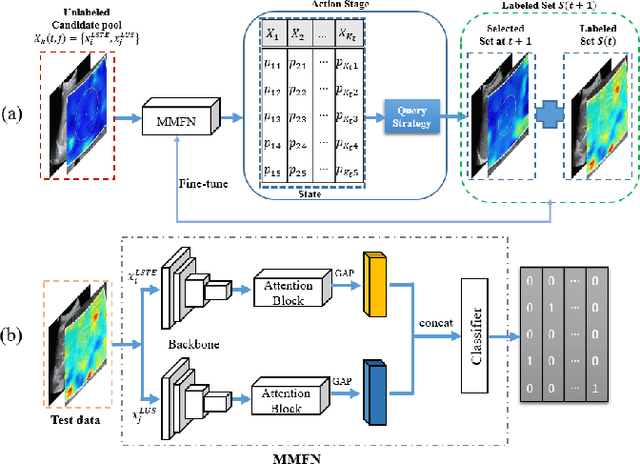
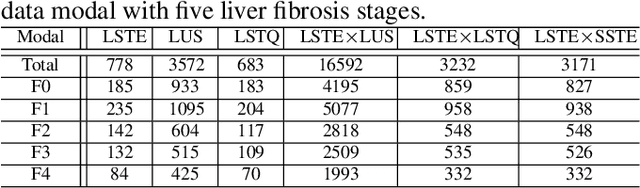
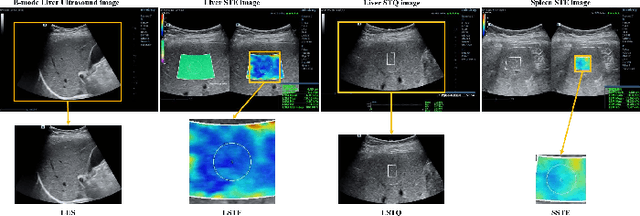
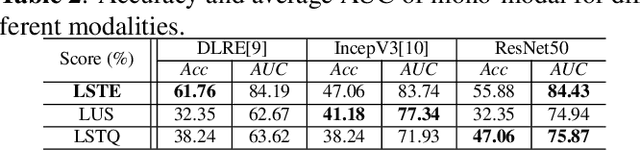
With the development of radiomics, noninvasive diagnosis like ultrasound (US) imaging plays a very important role in automatic liver fibrosis diagnosis (ALFD). Due to the noisy data, expensive annotations of US images, the application of Artificial Intelligence (AI) assisting approaches encounters a bottleneck. Besides, the use of mono-modal US data limits the further improve of the classification results. In this work, we innovatively propose a multi-modal fusion network with active learning (MMFN-AL) for ALFD to exploit the information of multiple modalities, eliminate the noisy data and reduce the annotation cost. Four image modalities including US and three types of shear wave elastography (SWEs) are exploited. A new dataset containing these modalities from 214 candidates is well-collected and pre-processed, with the labels obtained from the liver biopsy results. Experimental results show that our proposed method outperforms the state-of-the-art performance using less than 30% data, and by using only around 80% data, the proposed fusion network achieves high AUC 89.27% and accuracy 70.59%.