 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Human Pose Estimation by Maximizing Fusion and High-Level Spatial Attention
Jul 29, 2021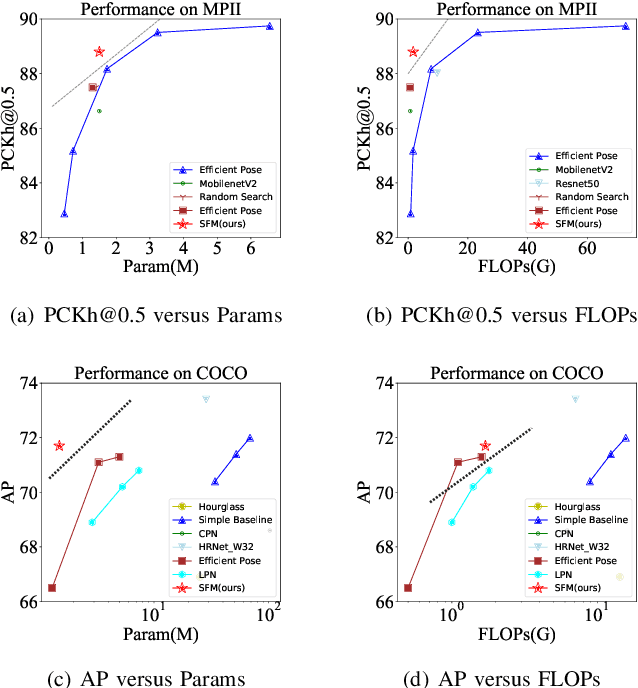
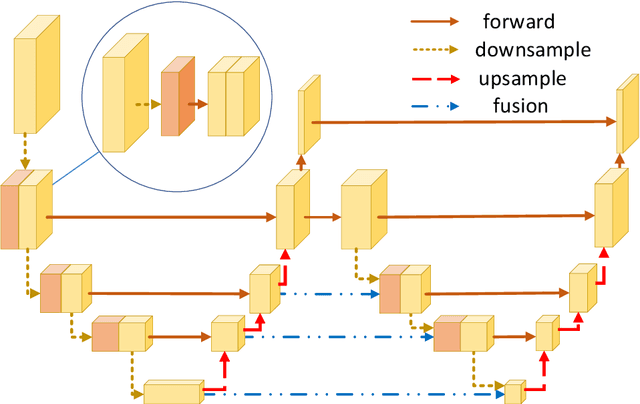
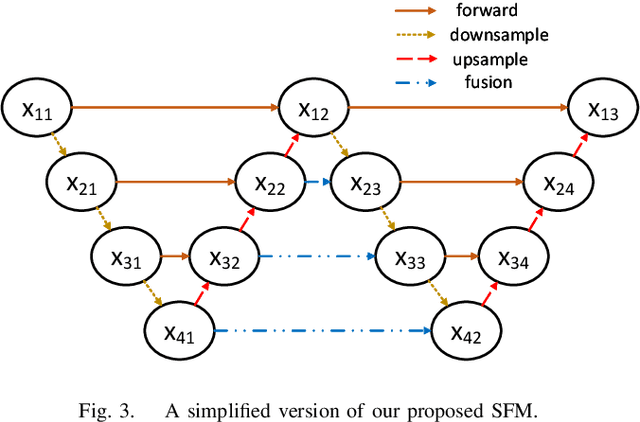
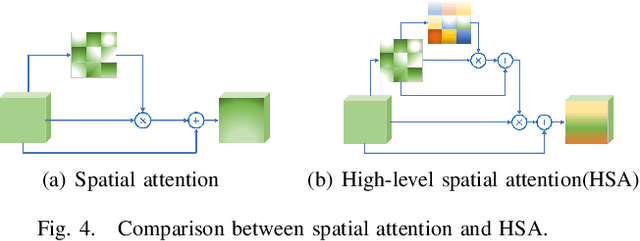
In this paper, we propose an efficient human pose estimation network -- SFM (slender fusion model) by fusing multi-level features and adding lightweight attention blocks -- HSA (High-Level Spatial Attention). Many existing methods on efficient network have already taken feature fusion into consideration, which largely boosts the performance. However, its performance is far inferior to large network such as ResNet and HRNet due to its limited fusion operation in the network. Specifically, we expand the number of fusion operation by building bridges between two pyramid frameworks without adding layers. Meanwhile, to capture long-range dependency, we propose a lightweight attention block -- HSA, which computes second-order attention map. In summary, SFM maximizes the number of feature fusion in a limited number of layers. HSA learns high precise spatial information by computing the attention of spatial attention map. With the help of SFM and HSA, our network is able to generate multi-level feature and extract precise global spatial information with little computing resource. Thus, our method achieve comparable or even better accuracy with less parameters and computational cost. Our SFM achieve 89.0 in PCKh@0.5, 42.0 in PCKh@0.1 on MPII validation set and 71.7 in AP, 90.7 in AP@0.5 on COCO validation with only 1.7G FLOPs and 1.5M parameters. The source code will be public soon.