 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-dVLM: Efficient Block-Diffusion VLM via Direct Conversion from Autoregressive VLM
Apr 08, 2026Vision-language models (VLMs) predominantly rely on autoregressive decoding, which generates tokens one at a time and fundamentally limits inference throughput. This limitation is especially acute in physical AI scenarios such as robotics and autonomous driving, where VLMs are deployed on edge devices at batch size one, making AR decoding memory-bandwidth-bound and leaving hardware parallelism underutilized. While block-wise discrete diffusion has shown promise for parallel text generation, extending it to VLMs remains challenging due to the need to jointly handle continuous visual representations and discrete text tokens while preserving pretrained multimodal capabilities. We present Fast-dVLM, a block-diffusion-based VLM that enables KV-cache-compatible parallel decoding and speculative block decoding for inference acceleration. We systematically compare two AR-to-diffusion conversion strategies: a two-stage approach that first adapts the LLM backbone with text-only diffusion fine-tuning before multimodal training, and a direct approach that converts the full AR VLM in one stage. Under comparable training budgets, direct conversion proves substantially more efficient by leveraging the already multimodally aligned VLM; we therefore adopt it as our recommended recipe. We introduce a suite of multimodal diffusion adaptations, block size annealing, causal context attention, auto-truncation masking, and vision efficient concatenation, that collectively enable effective block diffusion in the VLM setting. Extensive experiments across 11 multimodal benchmarks show Fast-dVLM matches its autoregressive counterpart in generation quality. With SGLang integration and FP8 quantization, Fast-dVLM achieves over 6x end-to-end inference speedup over the AR baseline.
Efficient-DLM: From Autoregressive to Diffusion Language Models, and Beyond in Speed
Dec 16, 2025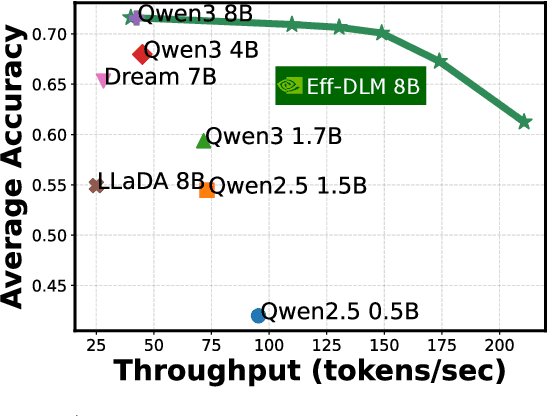
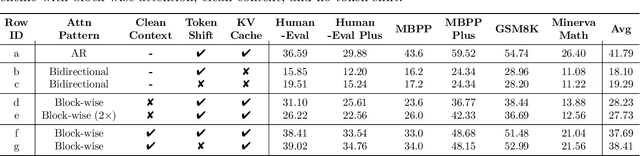
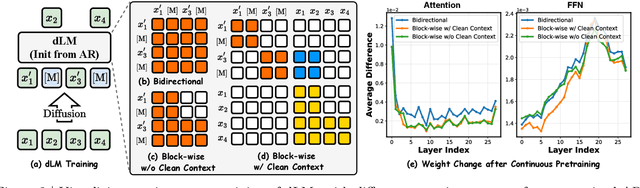
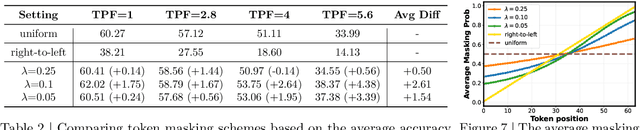
Diffusion language models (dLMs) have emerged as a promising paradigm that enables parallel, non-autoregressive generation, but their learning efficiency lags behind that of autoregressive (AR) language models when trained from scratch. To this end, we study AR-to-dLM conversion to transform pretrained AR models into efficient dLMs that excel in speed while preserving AR models' task accuracy. We achieve this by identifying limitations in the attention patterns and objectives of existing AR-to-dLM methods and then proposing principles and methodologies for more effective AR-to-dLM conversion. Specifically, we first systematically compare different attention patterns and find that maintaining pretrained AR weight distributions is critical for effective AR-to-dLM conversion. As such, we introduce a continuous pretraining scheme with a block-wise attention pattern, which remains causal across blocks while enabling bidirectional modeling within each block. We find that this approach can better preserve pretrained AR models' weight distributions than fully bidirectional modeling, in addition to its known benefit of enabling KV caching, and leads to a win-win in accuracy and efficiency. Second, to mitigate the training-test gap in mask token distributions (uniform vs. highly left-to-right), we propose a position-dependent token masking strategy that assigns higher masking probabilities to later tokens during training to better mimic test-time behavior. Leveraging this framework, we conduct extensive studies of dLMs' attention patterns, training dynamics, and other design choices, providing actionable insights into scalable AR-to-dLM conversion. These studies lead to the Efficient-DLM family, which outperforms state-of-the-art AR models and dLMs, e.g., our Efficient-DLM 8B achieves +5.4%/+2.7% higher accuracy with 4.5x/2.7x higher throughput compared to Dream 7B and Qwen3 4B, respectively.
LoCoT2V-Bench: A Benchmark for Long-Form and Complex Text-to-Video Generation
Oct 30, 2025Recently text-to-video generation has made impressive progress in producing short, high-quality clips, but evaluating long-form outputs remains a major challenge especially when processing complex prompts. Existing benchmarks mostly rely on simplified prompts and focus on low-level metrics, overlooking fine-grained alignment with prompts and abstract dimensions such as narrative coherence and thematic expression. To address these gaps, we propose LoCoT2V-Bench, a benchmark specifically designed for long video generation (LVG) under complex input conditions. Based on various real-world videos, LoCoT2V-Bench introduces a suite of realistic and complex prompts incorporating elements like scene transitions and event dynamics. Moreover, it constructs a multi-dimensional evaluation framework that includes our newly proposed metrics such as event-level alignment, fine-grained temporal consistency, content clarity, and the Human Expectation Realization Degree (HERD) that focuses on more abstract attributes like narrative flow, emotional response, and character development. Using this framework, we conduct a comprehensive evaluation of nine representative LVG models, finding that while current methods perform well on basic visual and temporal aspects, they struggle with inter-event consistency, fine-grained alignment, and high-level thematic adherence, etc. Overall, LoCoT2V-Bench provides a comprehensive and reliable platform for evaluating long-form complex text-to-video generation and highlights critical directions for future method improvement.
Beyond Surface Reasoning: Unveiling the True Long Chain-of-Thought Capacity of Diffusion Large Language Models
Oct 10, 2025Recently, Diffusion Large Language Models (DLLMs) have offered high throughput and effective sequential reasoning, making them a competitive alternative to autoregressive LLMs (ALLMs). However, parallel decoding, which enables simultaneous token updates, conflicts with the causal order often required for rigorous reasoning. We first identify this conflict as the core Parallel-Sequential Contradiction (PSC). Behavioral analyses in both simple and complex reasoning tasks show that DLLMs exhibit genuine parallelism only for directly decidable outputs. As task difficulty increases, they revert to autoregressive-like behavior, a limitation exacerbated by autoregressive prompting, which nearly doubles the number of decoding steps with remasking without improving quality. Moreover, PSC restricts DLLMs' self-reflection, reasoning depth, and exploratory breadth. To further characterize PSC, we introduce three scaling dimensions for DLLMs: parallel, diffusion, and sequential. Empirically, while parallel scaling yields consistent improvements, diffusion and sequential scaling are constrained by PSC. Based on these findings, we propose several practical mitigations, parallel-oriented prompting, diffusion early stopping, and parallel scaling, to reduce PSC-induced ineffectiveness and inefficiencies.
Discrete Diffusion VLA: Bringing Discrete Diffusion to Action Decoding in Vision-Language-Action Policies
Aug 27, 2025Vision-Language-Action (VLA) models adapt large vision-language backbones to map images and instructions to robot actions. However, prevailing VLA decoders either generate actions autoregressively in a fixed left-to-right order or attach continuous diffusion or flow matching heads outside the backbone, demanding specialized training and iterative sampling that hinder a unified, scalable architecture. We present Discrete Diffusion VLA, a single-transformer policy that models discretized action chunks with discrete diffusion and is trained with the same cross-entropy objective as the VLM backbone. The design retains diffusion's progressive refinement paradigm while remaining natively compatible with the discrete token interface of VLMs. Our method achieves an adaptive decoding order that resolves easy action elements before harder ones and uses secondary remasking to revisit uncertain predictions across refinement rounds, which improves consistency and enables robust error correction. This unified decoder preserves pretrained vision language priors, supports parallel decoding, breaks the autoregressive bottleneck, and reduces the number of function evaluations. Discrete Diffusion VLA achieves 96.3% avg. SR on LIBERO, 71.2% visual matching on SimplerEnv Fractal and 49.3% overall on SimplerEnv Bridge, improving over both autoregressive and continuous diffusion baselines. These findings indicate that discrete-diffusion action decoder supports precise action modeling and consistent training, laying groundwork for scaling VLA to larger models and datasets.
Locality-aware Parallel Decoding for Efficient Autoregressive Image Generation
Jul 02, 2025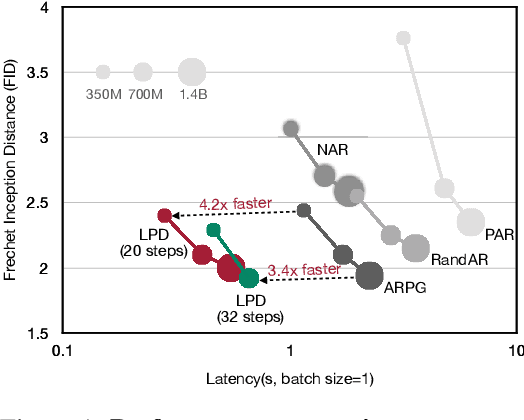



We present Locality-aware Parallel Decoding (LPD) to accelerate autoregressive image generation. Traditional autoregressive image generation relies on next-patch prediction, a memory-bound process that leads to high latency. Existing works have tried to parallelize next-patch prediction by shifting to multi-patch prediction to accelerate the process, but only achieved limited parallelization. To achieve high parallelization while maintaining generation quality, we introduce two key techniques: (1) Flexible Parallelized Autoregressive Modeling, a novel architecture that enables arbitrary generation ordering and degrees of parallelization. It uses learnable position query tokens to guide generation at target positions while ensuring mutual visibility among concurrently generated tokens for consistent parallel decoding. (2) Locality-aware Generation Ordering, a novel schedule that forms groups to minimize intra-group dependencies and maximize contextual support, enhancing generation quality. With these designs, we reduce the generation steps from 256 to 20 (256$\times$256 res.) and 1024 to 48 (512$\times$512 res.) without compromising quality on the ImageNet class-conditional generation, and achieving at least 3.4$\times$ lower latency than previous parallelized autoregressive models.
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
May 28, 2025Diffusion-based large language models (Diffusion LLMs) have shown promise for non-autoregressive text generation with parallel decoding capabilities. However, the practical inference speed of open-sourced Diffusion LLMs often lags behind autoregressive models due to the lack of Key-Value (KV) Cache and quality degradation when decoding multiple tokens simultaneously. To bridge this gap, we introduce a novel block-wise approximate KV Cache mechanism tailored for bidirectional diffusion models, enabling cache reuse with negligible performance drop. Additionally, we identify the root cause of generation quality degradation in parallel decoding as the disruption of token dependencies under the conditional independence assumption. To address this, we propose a confidence-aware parallel decoding strategy that selectively decodes tokens exceeding a confidence threshold, mitigating dependency violations and maintaining generation quality. Experimental results on LLaDA and Dream models across multiple LLM benchmarks demonstrate up to \textbf{27.6$\times$ throughput} improvement with minimal accuracy loss, closing the performance gap with autoregressive models and paving the way for practical deployment of Diffusion LLMs.
FUDOKI: Discrete Flow-based Unified Understanding and Generation via Kinetic-Optimal Velocities
May 26, 2025The rapid progress of large language models (LLMs) has catalyzed the emergence of multimodal large language models (MLLMs) that unify visual understanding and image generation within a single framework. However, most existing MLLMs rely on autoregressive (AR) architectures, which impose inherent limitations on future development, such as the raster-scan order in image generation and restricted reasoning abilities in causal context modeling. In this work, we challenge the dominance of AR-based approaches by introducing FUDOKI, a unified multimodal model purely based on discrete flow matching, as an alternative to conventional AR paradigms. By leveraging metric-induced probability paths with kinetic optimal velocities, our framework goes beyond the previous masking-based corruption process, enabling iterative refinement with self-correction capability and richer bidirectional context integration during generation. To mitigate the high cost of training from scratch, we initialize FUDOKI from pre-trained AR-based MLLMs and adaptively transition to the discrete flow matching paradigm. Experimental results show that FUDOKI achieves performance comparable to state-of-the-art AR-based MLLMs across both visual understanding and image generation tasks, highlighting its potential as a foundation for next-generation unified multimodal models. Furthermore, we show that applying test-time scaling techniques to FUDOKI yields significant performance gains, further underscoring its promise for future enhancement through reinforcement learning.
Towards Self-Improving Systematic Cognition for Next-Generation Foundation MLLMs
Mar 16, 2025Despite their impressive capabilities, Multimodal Large Language Models (MLLMs) face challenges with fine-grained perception and complex reasoning. Prevalent pre-training approaches focus on enhancing perception by training on high-quality image captions due to the extremely high cost of collecting chain-of-thought (CoT) reasoning data for improving reasoning. While leveraging advanced MLLMs for caption generation enhances scalability, the outputs often lack comprehensiveness and accuracy. In this paper, we introduce Self-Improving Cognition (SIcog), a self-learning framework designed to construct next-generation foundation MLLMs by enhancing their systematic cognitive capabilities through multimodal pre-training with self-generated data. Specifically, we propose chain-of-description, an approach that improves an MLLM's systematic perception by enabling step-by-step visual understanding, ensuring greater comprehensiveness and accuracy. Additionally, we adopt a structured CoT reasoning technique to enable MLLMs to integrate in-depth multimodal reasoning. To construct a next-generation foundation MLLM with self-improved cognition, SIcog first equips an MLLM with systematic perception and reasoning abilities using minimal external annotations. The enhanced models then generate detailed captions and CoT reasoning data, which are further curated through self-consistency. This curated data is ultimately used to refine the MLLM during multimodal pre-training, facilitating next-generation foundation MLLM construction. Extensive experiments on both low- and high-resolution MLLMs across diverse benchmarks demonstrate that, with merely 213K self-generated pre-training samples, SIcog produces next-generation foundation MLLMs with significantly improved cognition, achieving benchmark-leading performance compared to prevalent pre-training approaches.
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Dec 13, 2024



We present DeepSeek-VL2, an advanced series of large Mixture-of-Experts (MoE) Vision-Language Models that significantly improves upon its predecessor, DeepSeek-VL, through two key major upgrades. For the vision component, we incorporate a dynamic tiling vision encoding strategy designed for processing high-resolution images with different aspect ratios. For the language component, we leverage DeepSeekMoE models with the Multi-head Latent Attention mechanism, which compresses Key-Value cache into latent vectors, to enable efficient inference and high throughput. Trained on an improved vision-language dataset, DeepSeek-VL2 demonstrates superior capabilities across various tasks, including but not limited to visual question answering, optical character recognition, document/table/chart understanding, and visual grounding. Our model series is composed of three variants: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small and DeepSeek-VL2, with 1.0B, 2.8B and 4.5B activated parameters respectively. DeepSeek-VL2 achieves competitive or state-of-the-art performance with similar or fewer activated parameters compared to existing open-source dense and MoE-based models. Codes and pre-trained models are publicly accessible at https://github.com/deepseek-ai/DeepSeek-VL2.