 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFUDOKI: Discrete Flow-based Unified Understanding and Generation via Kinetic-Optimal Velocities
May 26, 2025The rapid progress of large language models (LLMs) has catalyzed the emergence of multimodal large language models (MLLMs) that unify visual understanding and image generation within a single framework. However, most existing MLLMs rely on autoregressive (AR) architectures, which impose inherent limitations on future development, such as the raster-scan order in image generation and restricted reasoning abilities in causal context modeling. In this work, we challenge the dominance of AR-based approaches by introducing FUDOKI, a unified multimodal model purely based on discrete flow matching, as an alternative to conventional AR paradigms. By leveraging metric-induced probability paths with kinetic optimal velocities, our framework goes beyond the previous masking-based corruption process, enabling iterative refinement with self-correction capability and richer bidirectional context integration during generation. To mitigate the high cost of training from scratch, we initialize FUDOKI from pre-trained AR-based MLLMs and adaptively transition to the discrete flow matching paradigm. Experimental results show that FUDOKI achieves performance comparable to state-of-the-art AR-based MLLMs across both visual understanding and image generation tasks, highlighting its potential as a foundation for next-generation unified multimodal models. Furthermore, we show that applying test-time scaling techniques to FUDOKI yields significant performance gains, further underscoring its promise for future enhancement through reinforcement learning.
PILC: Practical Image Lossless Compression with an End-to-end GPU Oriented Neural Framework
Jun 10, 2022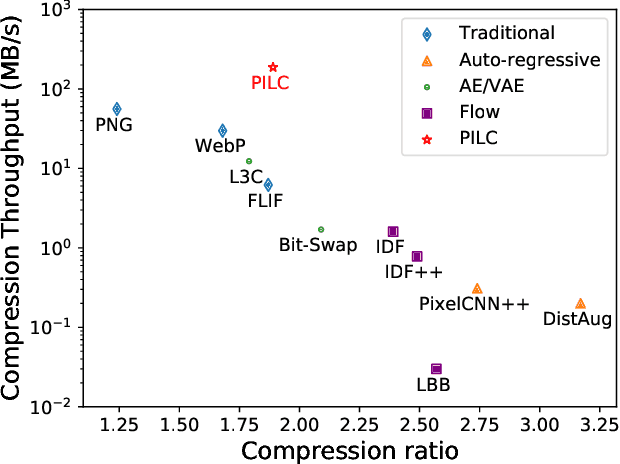

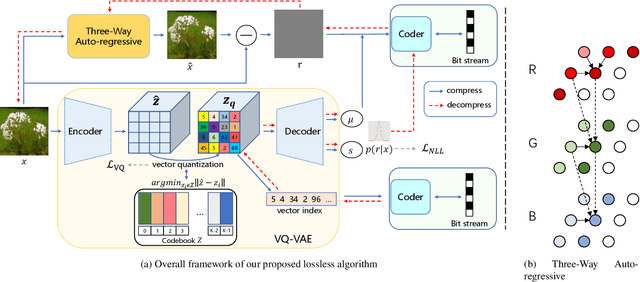

Generative model based image lossless compression algorithms have seen a great success in improving compression ratio. However, the throughput for most of them is less than 1 MB/s even with the most advanced AI accelerated chips, preventing them from most real-world applications, which often require 100 MB/s. In this paper, we propose PILC, an end-to-end image lossless compression framework that achieves 200 MB/s for both compression and decompression with a single NVIDIA Tesla V100 GPU, 10 times faster than the most efficient one before. To obtain this result, we first develop an AI codec that combines auto-regressive model and VQ-VAE which performs well in lightweight setting, then we design a low complexity entropy coder that works well with our codec. Experiments show that our framework compresses better than PNG by a margin of 30% in multiple datasets. We believe this is an important step to bring AI compression forward to commercial use.
Split Hierarchical Variational Compression
Apr 05, 2022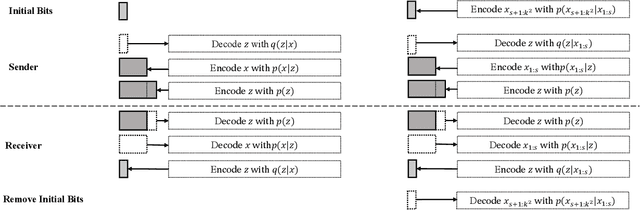
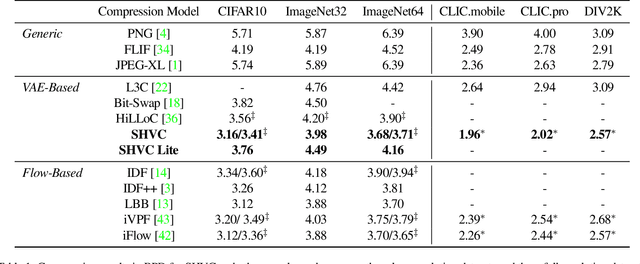
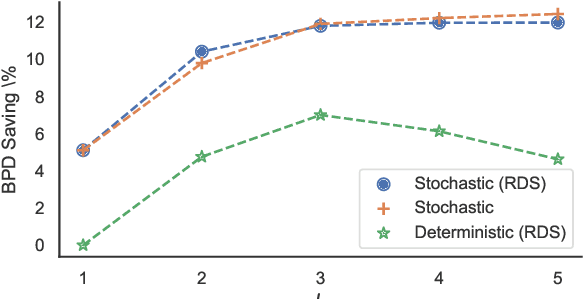
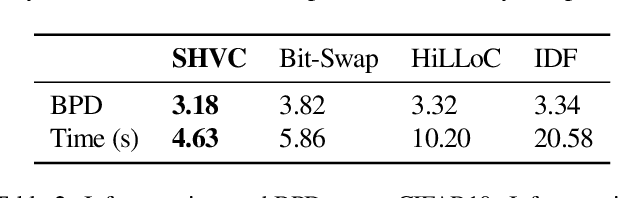
Variational autoencoders (VAEs) have witnessed great success in performing the compression of image datasets. This success, made possible by the bits-back coding framework, has produced competitive compression performance across many benchmarks. However, despite this, VAE architectures are currently limited by a combination of coding practicalities and compression ratios. That is, not only do state-of-the-art methods, such as normalizing flows, often demonstrate out-performance, but the initial bits required in coding makes single and parallel image compression challenging. To remedy this, we introduce Split Hierarchical Variational Compression (SHVC). SHVC introduces two novelties. Firstly, we propose an efficient autoregressive prior, the autoregressive sub-pixel convolution, that allows a generalisation between per-pixel autoregressions and fully factorised probability models. Secondly, we define our coding framework, the autoregressive initial bits, that flexibly supports parallel coding and avoids -- for the first time -- many of the practicalities commonly associated with bits-back coding. In our experiments, we demonstrate SHVC is able to achieve state-of-the-art compression performance across full-resolution lossless image compression tasks, with up to 100x fewer model parameters than competing VAE approaches.
Parallel Neural Local Lossless Compression
Jan 23, 2022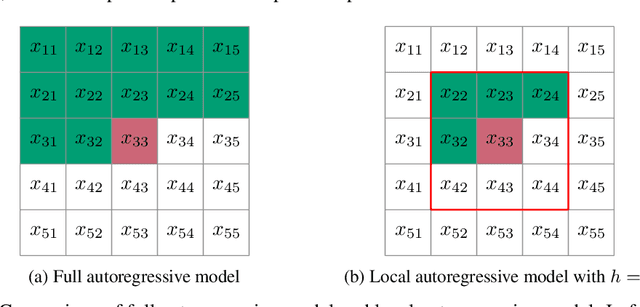


The recently proposed Neural Local Lossless Compression (NeLLoC), which is based on a local autoregressive model, has achieved state-of-the-art (SOTA) out-of-distribution (OOD) generalization performance in the image compression task. In addition to the encouragement of OOD generalization, the local model also allows parallel inference in the decoding stage. In this paper, we propose a parallelization scheme for local autoregressive models. We discuss the practicalities of implementing this scheme, and provide experimental evidence of significant gains in compression runtime compared to the previous, non-parallel implementation.
iFlow: Numerically Invertible Flows for Efficient Lossless Compression via a Uniform Coder
Nov 01, 2021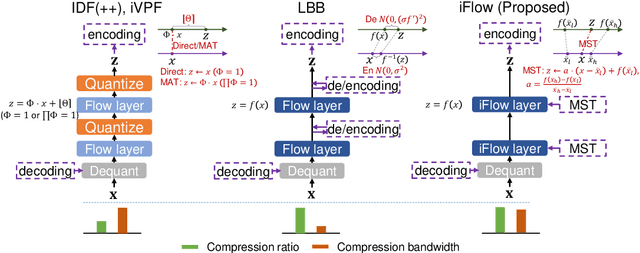

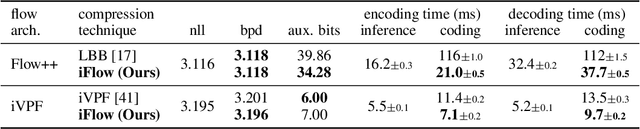
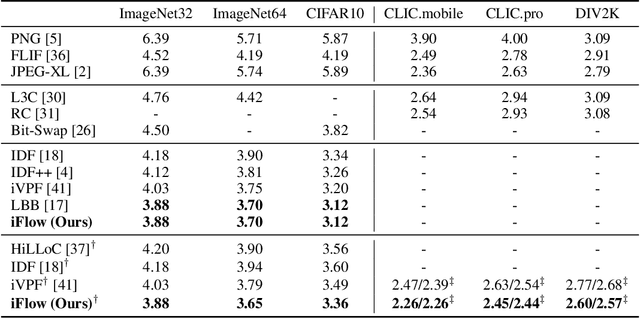
It was estimated that the world produced $59 ZB$ ($5.9 \times 10^{13} GB$) of data in 2020, resulting in the enormous costs of both data storage and transmission. Fortunately, recent advances in deep generative models have spearheaded a new class of so-called "neural compression" algorithms, which significantly outperform traditional codecs in terms of compression ratio. Unfortunately, the application of neural compression garners little commercial interest due to its limited bandwidth; therefore, developing highly efficient frameworks is of critical practical importance. In this paper, we discuss lossless compression using normalizing flows which have demonstrated a great capacity for achieving high compression ratios. As such, we introduce iFlow, a new method for achieving efficient lossless compression. We first propose Modular Scale Transform (MST) and a novel family of numerically invertible flow transformations based on MST. Then we introduce the Uniform Base Conversion System (UBCS), a fast uniform-distribution codec incorporated into iFlow, enabling efficient compression. iFlow achieves state-of-the-art compression ratios and is $5\times$ quicker than other high-performance schemes. Furthermore, the techniques presented in this paper can be used to accelerate coding time for a broad class of flow-based algorithms.
NASOA: Towards Faster Task-oriented Online Fine-tuning with a Zoo of Models
Aug 07, 2021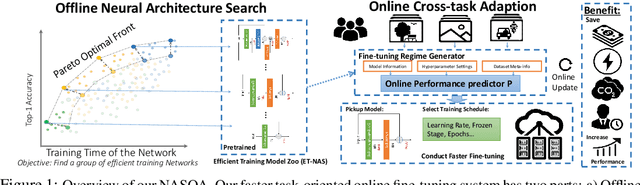

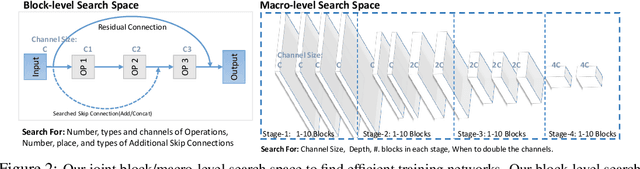
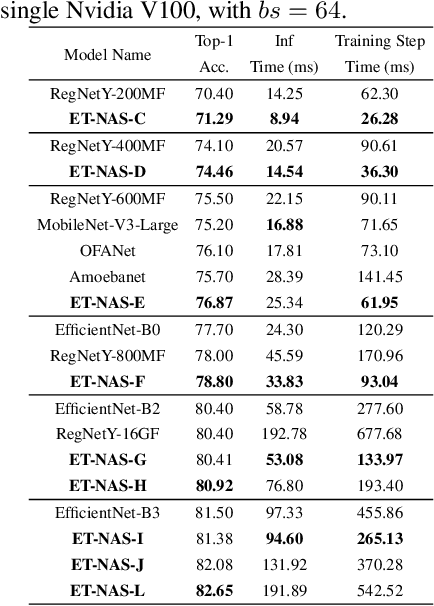
Fine-tuning from pre-trained ImageNet models has been a simple, effective, and popular approach for various computer vision tasks. The common practice of fine-tuning is to adopt a default hyperparameter setting with a fixed pre-trained model, while both of them are not optimized for specific tasks and time constraints. Moreover, in cloud computing or GPU clusters where the tasks arrive sequentially in a stream, faster online fine-tuning is a more desired and realistic strategy for saving money, energy consumption, and CO2 emission. In this paper, we propose a joint Neural Architecture Search and Online Adaption framework named NASOA towards a faster task-oriented fine-tuning upon the request of users. Specifically, NASOA first adopts an offline NAS to identify a group of training-efficient networks to form a pretrained model zoo. We propose a novel joint block and macro-level search space to enable a flexible and efficient search. Then, by estimating fine-tuning performance via an adaptive model by accumulating experience from the past tasks, an online schedule generator is proposed to pick up the most suitable model and generate a personalized training regime with respect to each desired task in a one-shot fashion. The resulting model zoo is more training efficient than SOTA models, e.g. 6x faster than RegNetY-16GF, and 1.7x faster than EfficientNetB3. Experiments on multiple datasets also show that NASOA achieves much better fine-tuning results, i.e. improving around 2.1% accuracy than the best performance in RegNet series under various constraints and tasks; 40x faster compared to the BOHB.
iVPF: Numerical Invertible Volume Preserving Flow for Efficient Lossless Compression
Mar 30, 2021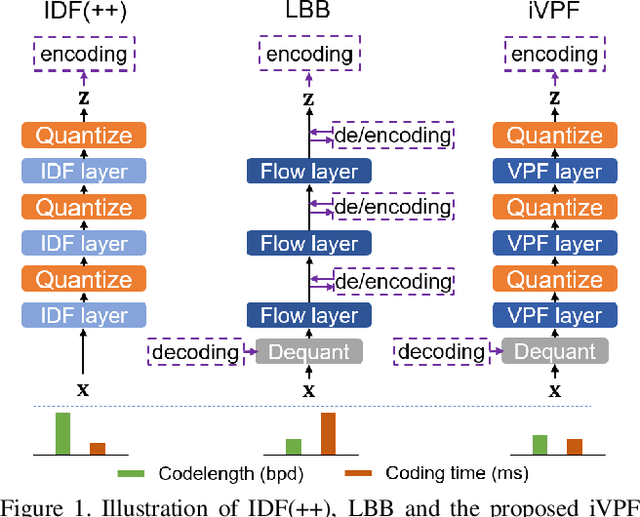
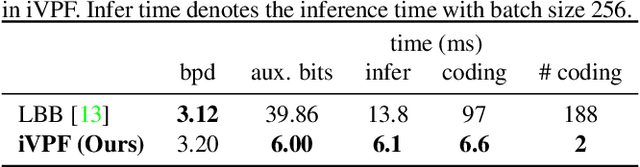

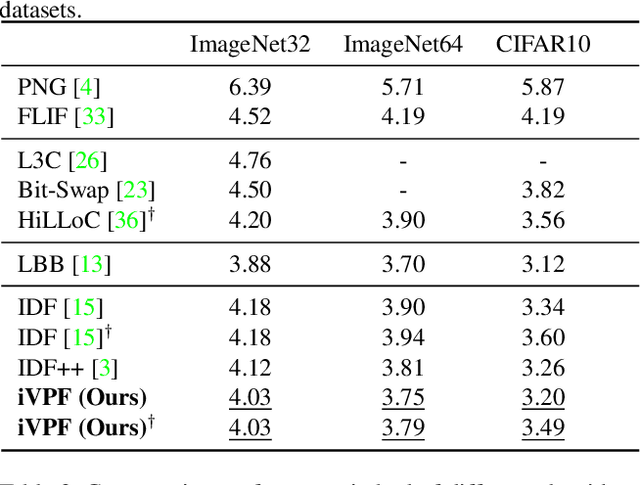
It is nontrivial to store rapidly growing big data nowadays, which demands high-performance lossless compression techniques. Likelihood-based generative models have witnessed their success on lossless compression, where flow based models are desirable in allowing exact data likelihood optimisation with bijective mappings. However, common continuous flows are in contradiction with the discreteness of coding schemes, which requires either 1) imposing strict constraints on flow models that degrades the performance or 2) coding numerous bijective mapping errors which reduces the efficiency. In this paper, we investigate volume preserving flows for lossless compression and show that a bijective mapping without error is possible. We propose Numerical Invertible Volume Preserving Flow (iVPF) which is derived from the general volume preserving flows. By introducing novel computation algorithms on flow models, an exact bijective mapping is achieved without any numerical error. We also propose a lossless compression algorithm based on iVPF. Experiments on various datasets show that the algorithm based on iVPF achieves state-of-the-art compression ratio over lightweight compression algorithms.
VEGA: Towards an End-to-End Configurable AutoML Pipeline
Nov 05, 2020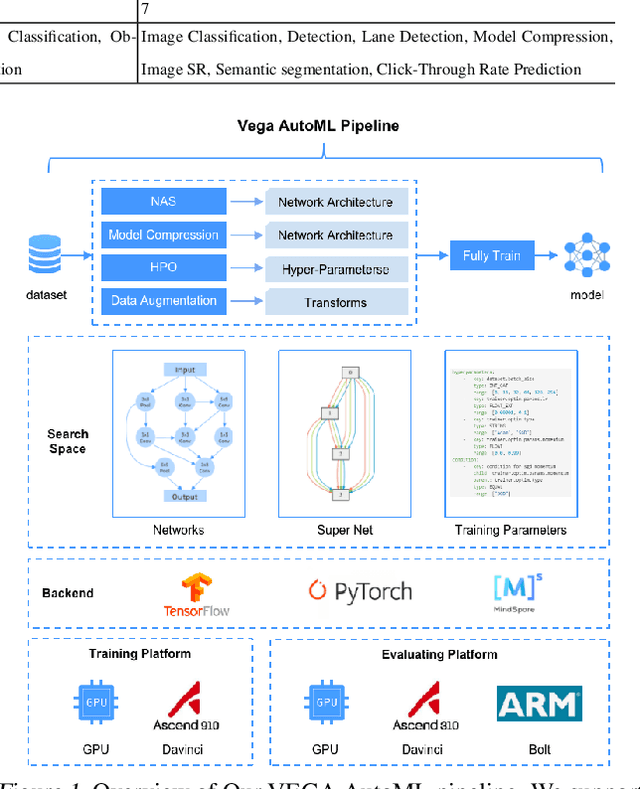

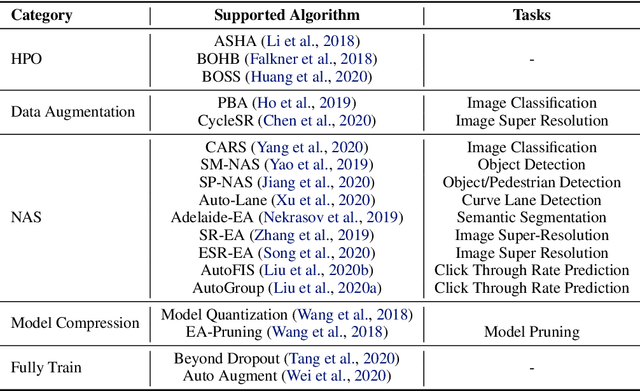
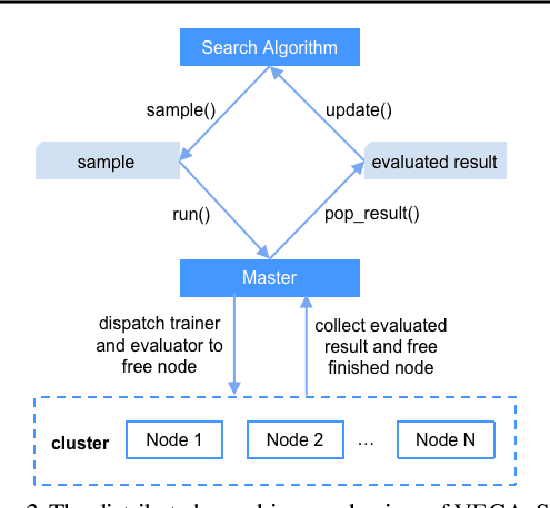
Automated Machine Learning (AutoML) is an important industrial solution for automatic discovery and deployment of the machine learning models. However, designing an integrated AutoML system faces four great challenges of configurability, scalability, integrability, and platform diversity. In this work, we present VEGA, an efficient and comprehensive AutoML framework that is compatible and optimized for multiple hardware platforms. a) The VEGA pipeline integrates various modules of AutoML, including Neural Architecture Search (NAS), Hyperparameter Optimization (HPO), Auto Data Augmentation, Model Compression, and Fully Train. b) To support a variety of search algorithms and tasks, we design a novel fine-grained search space and its description language to enable easy adaptation to different search algorithms and tasks. c) We abstract the common components of deep learning frameworks into a unified interface. VEGA can be executed with multiple back-ends and hardwares. Extensive benchmark experiments on multiple tasks demonstrate that VEGA can improve the existing AutoML algorithms and discover new high-performance models against SOTA methods, e.g. the searched DNet model zoo for Ascend 10x faster than EfficientNet-B5 and 9.2x faster than RegNetX-32GF on ImageNet. VEGA is open-sourced at https://github.com/huawei-noah/vega.
AIM 2019 Challenge on Constrained Super-Resolution: Methods and Results
Nov 04, 2019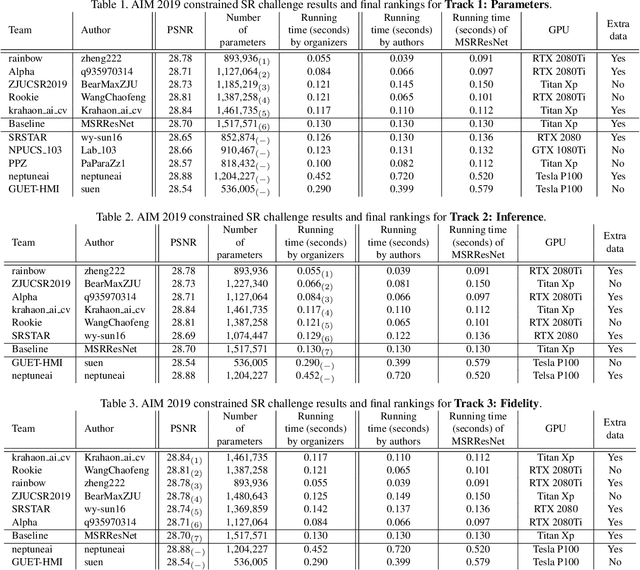
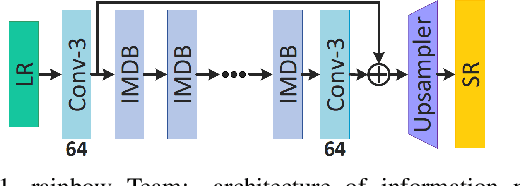
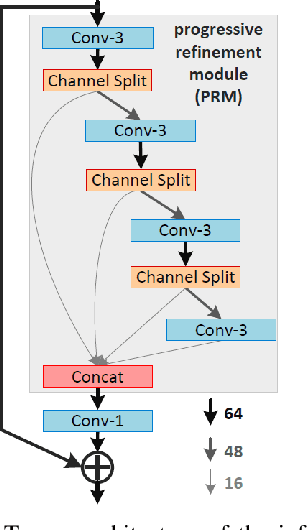
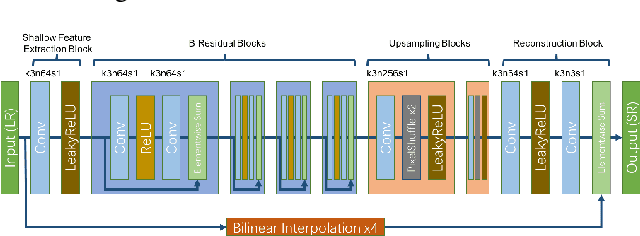
This paper reviews the AIM 2019 challenge on constrained example-based single image super-resolution with focus on proposed solutions and results. The challenge had 3 tracks. Taking the three main aspects (i.e., number of parameters, inference/running time, fidelity (PSNR)) of MSRResNet as the baseline, Track 1 aims to reduce the amount of parameters while being constrained to maintain or improve the running time and the PSNR result, Tracks 2 and 3 aim to optimize running time and PSNR result with constrain of the other two aspects, respectively. Each track had an average of 64 registered participants, and 12 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.