 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss Function Discovery for Object Detection via Convergence-Simulation Driven Search
Feb 09, 2021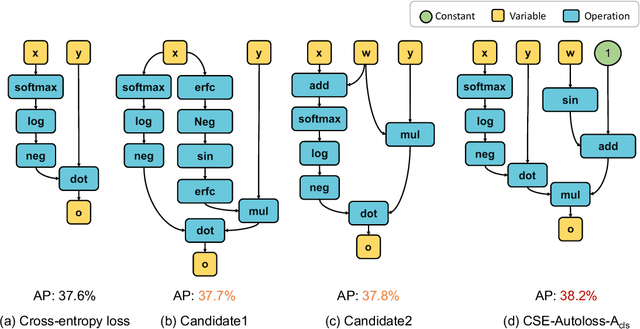
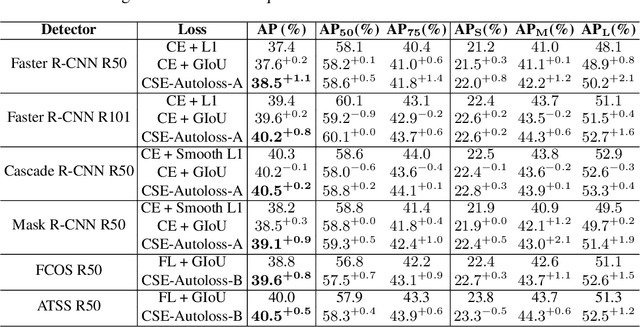
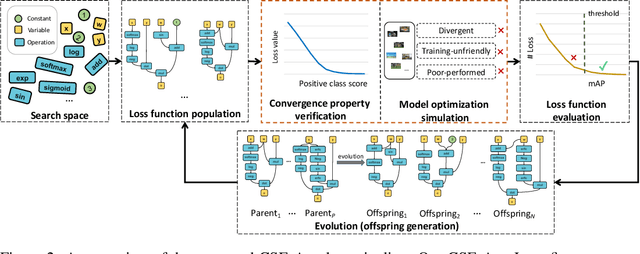

Designing proper loss functions for vision tasks has been a long-standing research direction to advance the capability of existing models. For object detection, the well-established classification and regression loss functions have been carefully designed by considering diverse learning challenges. Inspired by the recent progress in network architecture search, it is interesting to explore the possibility of discovering new loss function formulations via directly searching the primitive operation combinations. So that the learned losses not only fit for diverse object detection challenges to alleviate huge human efforts, but also have better alignment with evaluation metric and good mathematical convergence property. Beyond the previous auto-loss works on face recognition and image classification, our work makes the first attempt to discover new loss functions for the challenging object detection from primitive operation levels. We propose an effective convergence-simulation driven evolutionary search algorithm, called CSE-Autoloss, for speeding up the search progress by regularizing the mathematical rationality of loss candidates via convergence property verification and model optimization simulation. CSE-Autoloss involves the search space that cover a wide range of the possible variants of existing losses and discovers best-searched loss function combination within a short time (around 1.5 wall-clock days). We conduct extensive evaluations of loss function search on popular detectors and validate the good generalization capability of searched losses across diverse architectures and datasets. Our experiments show that the best-discovered loss function combinations outperform default combinations by 1.1% and 0.8% in terms of mAP for two-stage and one-stage detectors on COCO respectively. Our searched losses are available at https://github.com/PerdonLiu/CSE-Autoloss.
VEGA: Towards an End-to-End Configurable AutoML Pipeline
Nov 05, 2020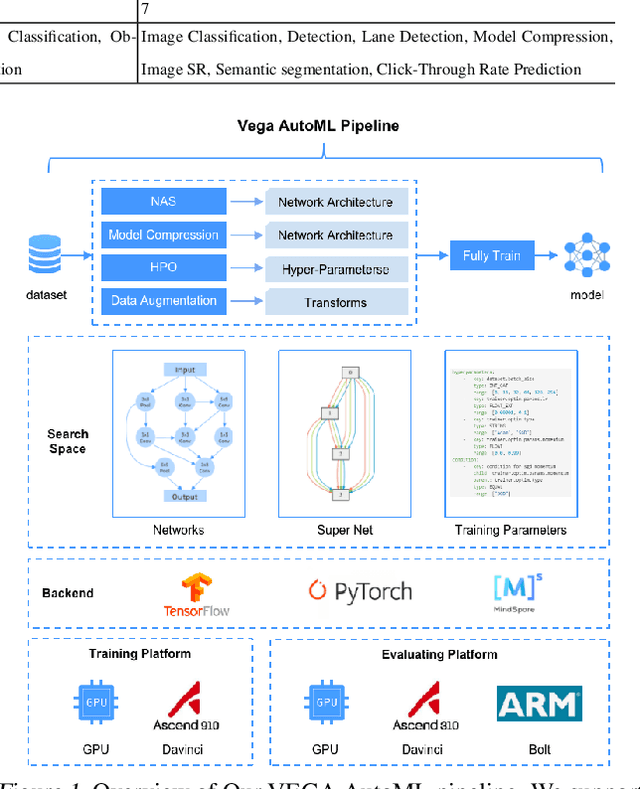

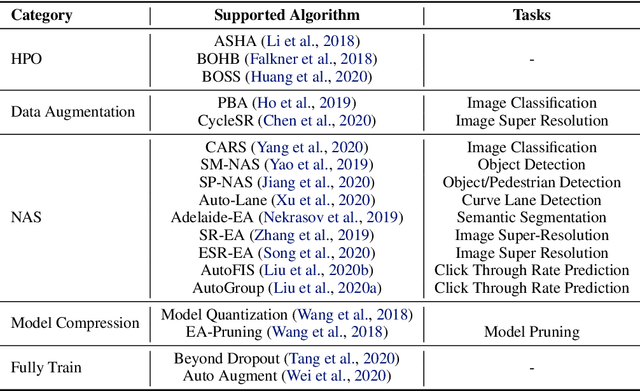
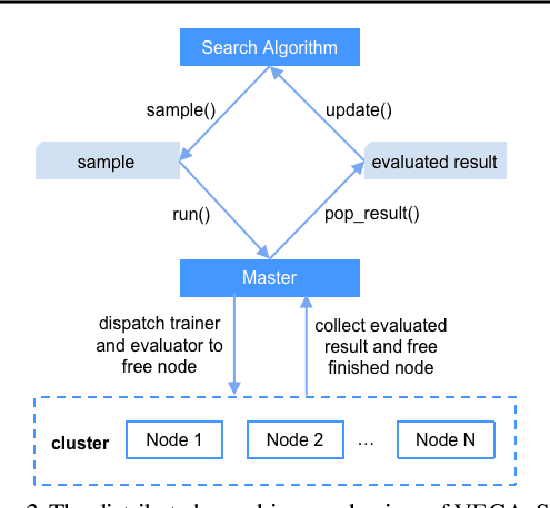
Automated Machine Learning (AutoML) is an important industrial solution for automatic discovery and deployment of the machine learning models. However, designing an integrated AutoML system faces four great challenges of configurability, scalability, integrability, and platform diversity. In this work, we present VEGA, an efficient and comprehensive AutoML framework that is compatible and optimized for multiple hardware platforms. a) The VEGA pipeline integrates various modules of AutoML, including Neural Architecture Search (NAS), Hyperparameter Optimization (HPO), Auto Data Augmentation, Model Compression, and Fully Train. b) To support a variety of search algorithms and tasks, we design a novel fine-grained search space and its description language to enable easy adaptation to different search algorithms and tasks. c) We abstract the common components of deep learning frameworks into a unified interface. VEGA can be executed with multiple back-ends and hardwares. Extensive benchmark experiments on multiple tasks demonstrate that VEGA can improve the existing AutoML algorithms and discover new high-performance models against SOTA methods, e.g. the searched DNet model zoo for Ascend 10x faster than EfficientNet-B5 and 9.2x faster than RegNetX-32GF on ImageNet. VEGA is open-sourced at https://github.com/huawei-noah/vega.
Towards Multi-pose Guided Virtual Try-on Network
Feb 28, 2019
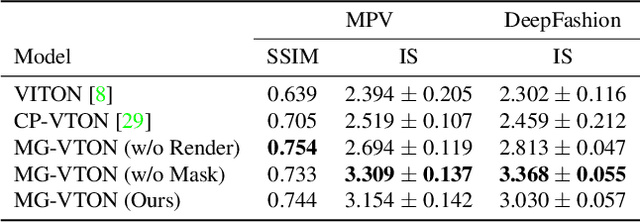
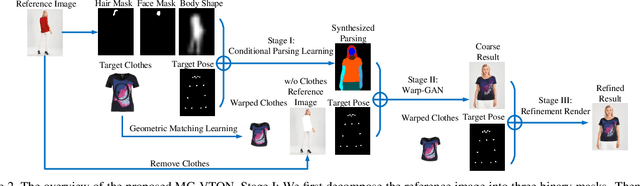

Virtual try-on system under arbitrary human poses has huge application potential, yet raises quite a lot of challenges, e.g. self-occlusions, heavy misalignment among diverse poses, and diverse clothes textures. Existing methods aim at fitting new clothes into a person can only transfer clothes on the fixed human pose, but still show unsatisfactory performances which often fail to preserve the identity, lose the texture details, and decrease the diversity of poses. In this paper, we make the first attempt towards multi-pose guided virtual try-on system, which enables transfer clothes on a person image under diverse poses. Given an input person image, a desired clothes image, and a desired pose, the proposed Multi-pose Guided Virtual Try-on Network (MG-VTON) can generate a new person image after fitting the desired clothes into the input image and manipulating human poses. Our MG-VTON is constructed in three stages: 1) a desired human parsing map of the target image is synthesized to match both the desired pose and the desired clothes shape; 2) a deep Warping Generative Adversarial Network (Warp-GAN) warps the desired clothes appearance into the synthesized human parsing map and alleviates the misalignment problem between the input human pose and desired human pose; 3) a refinement render utilizing multi-pose composition masks recovers the texture details of clothes and removes some artifacts. Extensive experiments on well-known datasets and our newly collected largest virtual try-on benchmark demonstrate that our MG-VTON significantly outperforms all state-of-the-art methods both qualitatively and quantitatively with promising multi-pose virtual try-on performances.
Toward Characteristic-Preserving Image-based Virtual Try-On Network
Sep 12, 2018

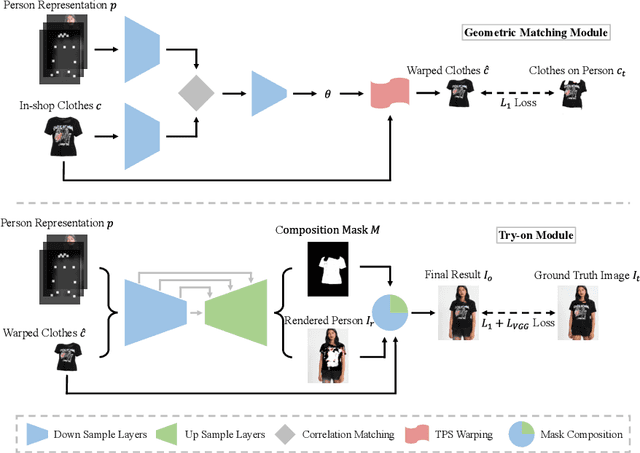

Image-based virtual try-on systems for fitting new in-shop clothes into a person image have attracted increasing research attention, yet is still challenging. A desirable pipeline should not only transform the target clothes into the most fitting shape seamlessly but also preserve well the clothes identity in the generated image, that is, the key characteristics (e.g. texture, logo, embroidery) that depict the original clothes. However, previous image-conditioned generation works fail to meet these critical requirements towards the plausible virtual try-on performance since they fail to handle large spatial misalignment between the input image and target clothes. Prior work explicitly tackled spatial deformation using shape context matching, but failed to preserve clothing details due to its coarse-to-fine strategy. In this work, we propose a new fully-learnable Characteristic-Preserving Virtual Try-On Network(CP-VTON) for addressing all real-world challenges in this task. First, CP-VTON learns a thin-plate spline transformation for transforming the in-shop clothes into fitting the body shape of the target person via a new Geometric Matching Module (GMM) rather than computing correspondences of interest points as prior works did. Second, to alleviate boundary artifacts of warped clothes and make the results more realistic, we employ a Try-On Module that learns a composition mask to integrate the warped clothes and the rendered image to ensure smoothness. Extensive experiments on a fashion dataset demonstrate our CP-VTON achieves the state-of-the-art virtual try-on performance both qualitatively and quantitatively.
Joint Detection and Identification Feature Learning for Person Search
Apr 06, 2017


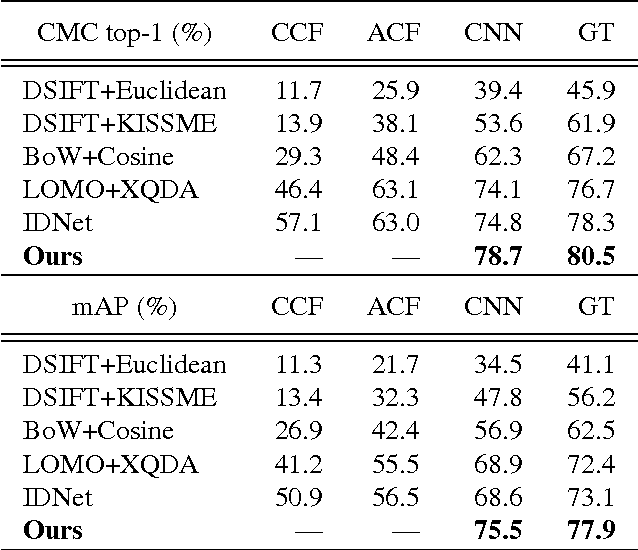
Existing person re-identification benchmarks and methods mainly focus on matching cropped pedestrian images between queries and candidates. However, it is different from real-world scenarios where the annotations of pedestrian bounding boxes are unavailable and the target person needs to be searched from a gallery of whole scene images. To close the gap, we propose a new deep learning framework for person search. Instead of breaking it down into two separate tasks---pedestrian detection and person re-identification, we jointly handle both aspects in a single convolutional neural network. An Online Instance Matching (OIM) loss function is proposed to train the network effectively, which is scalable to datasets with numerous identities. To validate our approach, we collect and annotate a large-scale benchmark dataset for person search. It contains 18,184 images, 8,432 identities, and 96,143 pedestrian bounding boxes. Experiments show that our framework outperforms other separate approaches, and the proposed OIM loss function converges much faster and better than the conventional Softmax loss.