 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry- and Relation-Aware Diffusion for EEG Super-Resolution
Feb 02, 2026Recent electroencephalography (EEG) spatial super-resolution (SR) methods, while showing improved quality by either directly predicting missing signals from visible channels or adapting latent diffusion-based generative modeling to temporal data, often lack awareness of physiological spatial structure, thereby constraining spatial generation performance. To address this issue, we introduce TopoDiff, a geometry- and relation-aware diffusion model for EEG spatial super-resolution. Inspired by how human experts interpret spatial EEG patterns, TopoDiff incorporates topology-aware image embeddings derived from EEG topographic representations to provide global geometric context for spatial generation, together with a dynamic channel-relation graph that encodes inter-electrode relationships and evolves with temporal dynamics. This design yields a spatially grounded EEG spatial super-resolution framework with consistent performance improvements. Across multiple EEG datasets spanning diverse applications, including SEED/SEED-IV for emotion recognition, PhysioNet motor imagery (MI/MM), and TUSZ for seizure detection, our method achieves substantial gains in generation fidelity and leads to notable improvements in downstream EEG task performance.
M4V: Multi-Modal Mamba for Text-to-Video Generation
Jun 12, 2025Text-to-video generation has significantly enriched content creation and holds the potential to evolve into powerful world simulators. However, modeling the vast spatiotemporal space remains computationally demanding, particularly when employing Transformers, which incur quadratic complexity in sequence processing and thus limit practical applications. Recent advancements in linear-time sequence modeling, particularly the Mamba architecture, offer a more efficient alternative. Nevertheless, its plain design limits its direct applicability to multi-modal and spatiotemporal video generation tasks. To address these challenges, we introduce M4V, a Multi-Modal Mamba framework for text-to-video generation. Specifically, we propose a multi-modal diffusion Mamba (MM-DiM) block that enables seamless integration of multi-modal information and spatiotemporal modeling through a multi-modal token re-composition design. As a result, the Mamba blocks in M4V reduce FLOPs by 45% compared to the attention-based alternative when generating videos at 768$\times$1280 resolution. Additionally, to mitigate the visual quality degradation in long-context autoregressive generation processes, we introduce a reward learning strategy that further enhances per-frame visual realism. Extensive experiments on text-to-video benchmarks demonstrate M4V's ability to produce high-quality videos while significantly lowering computational costs. Code and models will be publicly available at https://huangjch526.github.io/M4V_project.
FlexVAR: Flexible Visual Autoregressive Modeling without Residual Prediction
Feb 27, 2025This work challenges the residual prediction paradigm in visual autoregressive modeling and presents FlexVAR, a new Flexible Visual AutoRegressive image generation paradigm. FlexVAR facilitates autoregressive learning with ground-truth prediction, enabling each step to independently produce plausible images. This simple, intuitive approach swiftly learns visual distributions and makes the generation process more flexible and adaptable. Trained solely on low-resolution images ($\leq$ 256px), FlexVAR can: (1) Generate images of various resolutions and aspect ratios, even exceeding the resolution of the training images. (2) Support various image-to-image tasks, including image refinement, in/out-painting, and image expansion. (3) Adapt to various autoregressive steps, allowing for faster inference with fewer steps or enhancing image quality with more steps. Our 1.0B model outperforms its VAR counterpart on the ImageNet 256$\times$256 benchmark. Moreover, when zero-shot transfer the image generation process with 13 steps, the performance further improves to 2.08 FID, outperforming state-of-the-art autoregressive models AiM/VAR by 0.25/0.28 FID and popular diffusion models LDM/DiT by 1.52/0.19 FID, respectively. When transferring our 1.0B model to the ImageNet 512$\times$512 benchmark in a zero-shot manner, FlexVAR achieves competitive results compared to the VAR 2.3B model, which is a fully supervised model trained at 512$\times$512 resolution.
SLCA++: Unleash the Power of Sequential Fine-tuning for Continual Learning with Pre-training
Aug 15, 2024In recent years, continual learning with pre-training (CLPT) has received widespread interest, instead of its traditional focus of training from scratch. The use of strong pre-trained models (PTMs) can greatly facilitate knowledge transfer and alleviate catastrophic forgetting, but also suffers from progressive overfitting of pre-trained knowledge into specific downstream tasks. A majority of current efforts often keep the PTMs frozen and incorporate task-specific prompts to instruct representation learning, coupled with a prompt selection process for inference. However, due to the limited capacity of prompt parameters, this strategy demonstrates only sub-optimal performance in continual learning. In comparison, tuning all parameters of PTMs often provides the greatest potential for representation learning, making sequential fine-tuning (Seq FT) a fundamental baseline that has been overlooked in CLPT. To this end, we present an in-depth analysis of the progressive overfitting problem from the lens of Seq FT. Considering that the overly fast representation learning and the biased classification layer constitute this particular problem, we introduce the advanced Slow Learner with Classifier Alignment (SLCA++) framework to unleash the power of Seq FT, serving as a strong baseline approach for CLPT. Our approach involves a Slow Learner to selectively reduce the learning rate of backbone parameters, and a Classifier Alignment to align the disjoint classification layers in a post-hoc fashion. We further enhance the efficacy of SL with a symmetric cross-entropy loss, as well as employ a parameter-efficient strategy to implement Seq FT with SLCA++. Across a variety of continual learning scenarios on image classification benchmarks, our approach provides substantial improvements and outperforms state-of-the-art methods by a large margin. Code: https://github.com/GengDavid/SLCA.
SLCA: Slow Learner with Classifier Alignment for Continual Learning on a Pre-trained Model
Mar 09, 2023The goal of continual learning is to improve the performance of recognition models in learning sequentially arrived data. Although most existing works are established on the premise of learning from scratch, growing efforts have been devoted to incorporating the benefits of pre-training. However, how to adaptively exploit the pre-trained knowledge for each incremental task while maintaining its generalizability remains an open question. In this work, we present an extensive analysis for continual learning on a pre-trained model (CLPM), and attribute the key challenge to a progressive overfitting problem. Observing that selectively reducing the learning rate can almost resolve this issue in the representation layer, we propose a simple but extremely effective approach named Slow Learner with Classifier Alignment (SLCA), which further improves the classification layer by modeling the class-wise distributions and aligning the classification layers in a post-hoc fashion. Across a variety of scenarios, our proposal provides substantial improvements for CLPM (e.g., up to 49.76%, 50.05%, 44.69% and 40.16% on Split CIFAR-100, Split ImageNet-R, Split CUB-200 and Split Cars-196, respectively), and thus outperforms state-of-the-art approaches by a large margin. Based on such a strong baseline, critical factors and promising directions are analyzed in-depth to facilitate subsequent research.
Continual Object Detection via Prototypical Task Correlation Guided Gating Mechanism
May 06, 2022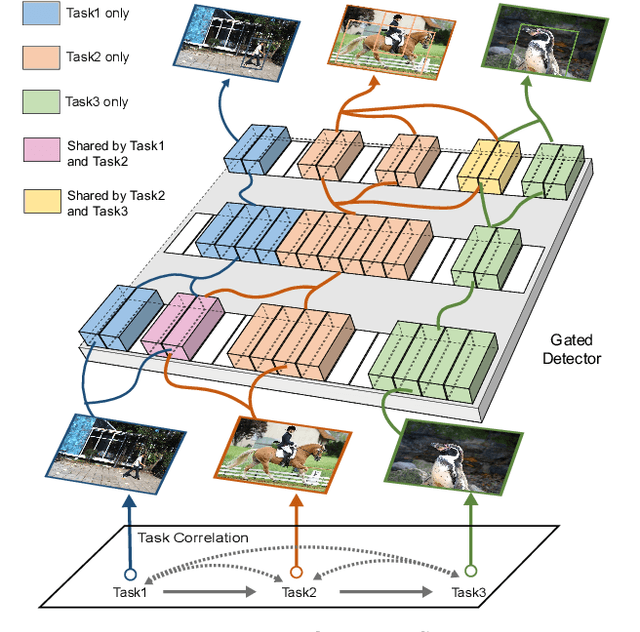
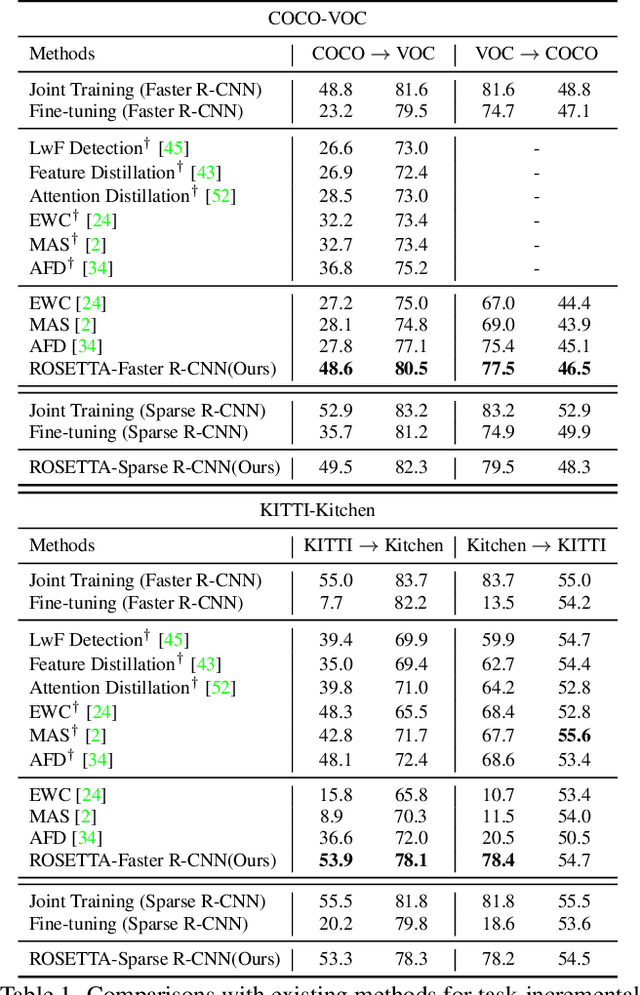
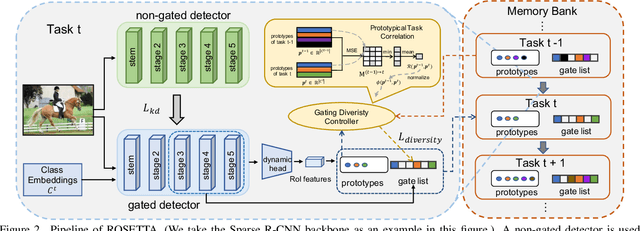
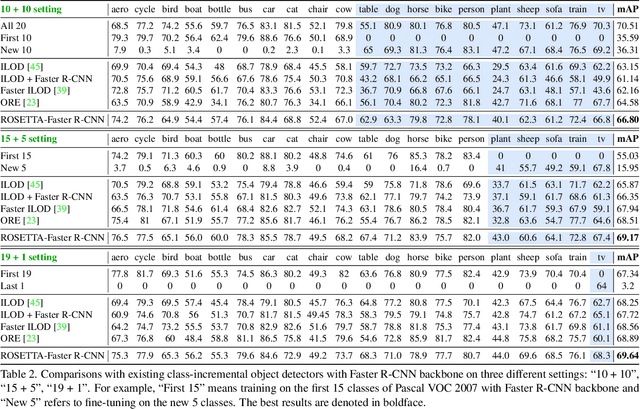
Continual learning is a challenging real-world problem for constructing a mature AI system when data are provided in a streaming fashion. Despite recent progress in continual classification, the researches of continual object detection are impeded by the diverse sizes and numbers of objects in each image. Different from previous works that tune the whole network for all tasks, in this work, we present a simple and flexible framework for continual object detection via pRotOtypical taSk corrElaTion guided gaTing mechAnism (ROSETTA). Concretely, a unified framework is shared by all tasks while task-aware gates are introduced to automatically select sub-models for specific tasks. In this way, various knowledge can be successively memorized by storing their corresponding sub-model weights in this system. To make ROSETTA automatically determine which experience is available and useful, a prototypical task correlation guided Gating Diversity Controller(GDC) is introduced to adaptively adjust the diversity of gates for the new task based on class-specific prototypes. GDC module computes class-to-class correlation matrix to depict the cross-task correlation, and hereby activates more exclusive gates for the new task if a significant domain gap is observed. Comprehensive experiments on COCO-VOC, KITTI-Kitchen, class-incremental detection on VOC and sequential learning of four tasks show that ROSETTA yields state-of-the-art performance on both task-based and class-based continual object detection.
NASOA: Towards Faster Task-oriented Online Fine-tuning with a Zoo of Models
Aug 07, 2021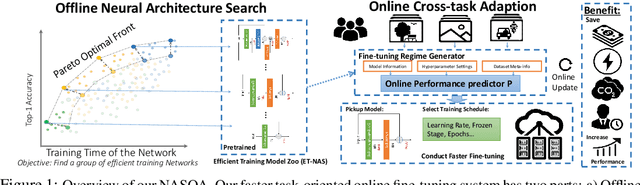

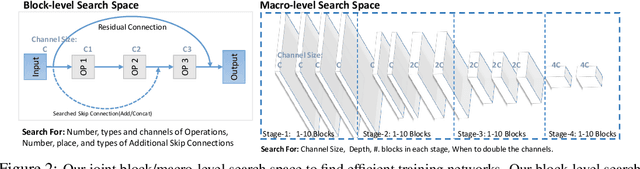
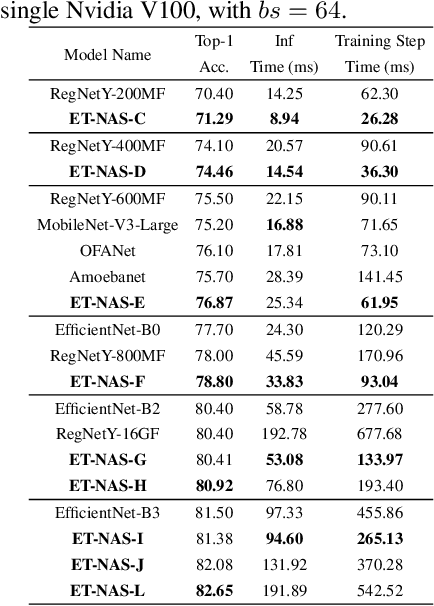
Fine-tuning from pre-trained ImageNet models has been a simple, effective, and popular approach for various computer vision tasks. The common practice of fine-tuning is to adopt a default hyperparameter setting with a fixed pre-trained model, while both of them are not optimized for specific tasks and time constraints. Moreover, in cloud computing or GPU clusters where the tasks arrive sequentially in a stream, faster online fine-tuning is a more desired and realistic strategy for saving money, energy consumption, and CO2 emission. In this paper, we propose a joint Neural Architecture Search and Online Adaption framework named NASOA towards a faster task-oriented fine-tuning upon the request of users. Specifically, NASOA first adopts an offline NAS to identify a group of training-efficient networks to form a pretrained model zoo. We propose a novel joint block and macro-level search space to enable a flexible and efficient search. Then, by estimating fine-tuning performance via an adaptive model by accumulating experience from the past tasks, an online schedule generator is proposed to pick up the most suitable model and generate a personalized training regime with respect to each desired task in a one-shot fashion. The resulting model zoo is more training efficient than SOTA models, e.g. 6x faster than RegNetY-16GF, and 1.7x faster than EfficientNetB3. Experiments on multiple datasets also show that NASOA achieves much better fine-tuning results, i.e. improving around 2.1% accuracy than the best performance in RegNet series under various constraints and tasks; 40x faster compared to the BOHB.
Few-Shot Segmentation via Cycle-Consistent Transformer
Jun 04, 2021

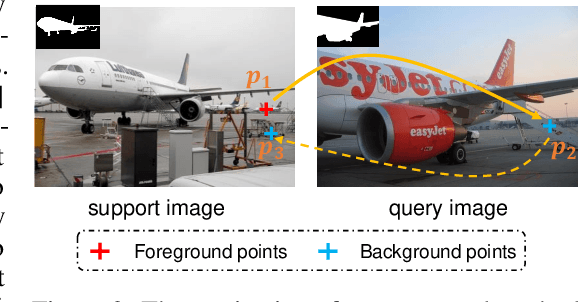
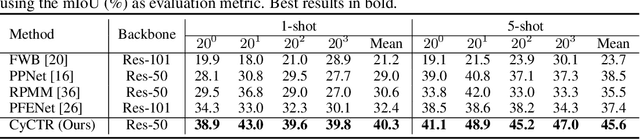
Few-shot segmentation aims to train a segmentation model that can fast adapt to novel classes with few exemplars. The conventional training paradigm is to learn to make predictions on query images conditioned on the features from support images. Previous methods only utilized the semantic-level prototypes of support images as the conditional information. These methods cannot utilize all pixel-wise support information for the query predictions, which is however critical for the segmentation task. In this paper, we focus on utilizing pixel-wise relationships between support and target images to facilitate the few-shot semantic segmentation task. We design a novel Cycle-Consistent Transformer (CyCTR) module to aggregate pixel-wise support features into query ones. CyCTR performs cross-attention between features from different images, i.e. support and query images. We observe that there may exist unexpected irrelevant pixel-level support features. Directly performing cross-attention may aggregate these features from support to query and bias the query features. Thus, we propose using a novel cycle-consistent attention mechanism to filter out possible harmful support features and encourage query features to attend to the most informative pixels from support images. Experiments on all few-shot segmentation benchmarks demonstrate that our proposed CyCTR leads to remarkable improvement compared to previous state-of-the-art methods. Specifically, on Pascal-$5^i$ and COCO-$20^i$ datasets, we achieve 66.6% and 45.6% mIoU for 5-shot segmentation, outperforming previous state-of-the-art by 4.6% and 7.1% respectively.
Loss Function Discovery for Object Detection via Convergence-Simulation Driven Search
Feb 09, 2021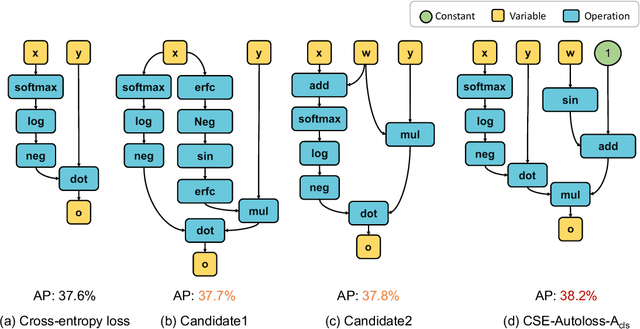
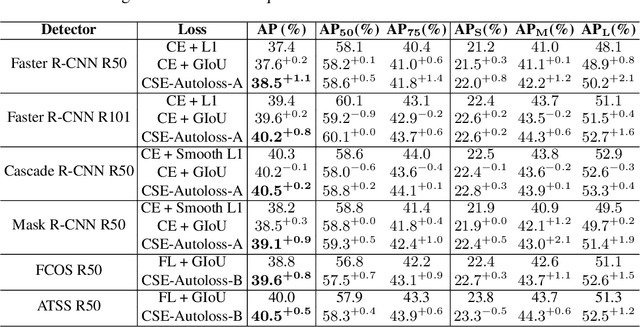
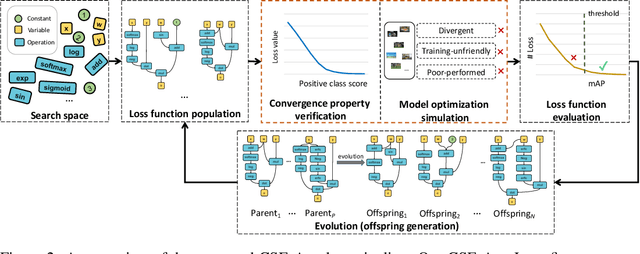

Designing proper loss functions for vision tasks has been a long-standing research direction to advance the capability of existing models. For object detection, the well-established classification and regression loss functions have been carefully designed by considering diverse learning challenges. Inspired by the recent progress in network architecture search, it is interesting to explore the possibility of discovering new loss function formulations via directly searching the primitive operation combinations. So that the learned losses not only fit for diverse object detection challenges to alleviate huge human efforts, but also have better alignment with evaluation metric and good mathematical convergence property. Beyond the previous auto-loss works on face recognition and image classification, our work makes the first attempt to discover new loss functions for the challenging object detection from primitive operation levels. We propose an effective convergence-simulation driven evolutionary search algorithm, called CSE-Autoloss, for speeding up the search progress by regularizing the mathematical rationality of loss candidates via convergence property verification and model optimization simulation. CSE-Autoloss involves the search space that cover a wide range of the possible variants of existing losses and discovers best-searched loss function combination within a short time (around 1.5 wall-clock days). We conduct extensive evaluations of loss function search on popular detectors and validate the good generalization capability of searched losses across diverse architectures and datasets. Our experiments show that the best-discovered loss function combinations outperform default combinations by 1.1% and 0.8% in terms of mAP for two-stage and one-stage detectors on COCO respectively. Our searched losses are available at https://github.com/PerdonLiu/CSE-Autoloss.
Ada-Segment: Automated Multi-loss Adaptation for Panoptic Segmentation
Dec 07, 2020



Panoptic segmentation that unifies instance segmentation and semantic segmentation has recently attracted increasing attention. While most existing methods focus on designing novel architectures, we steer toward a different perspective: performing automated multi-loss adaptation (named Ada-Segment) on the fly to flexibly adjust multiple training losses over the course of training using a controller trained to capture the learning dynamics. This offers a few advantages: it bypasses manual tuning of the sensitive loss combination, a decisive factor for panoptic segmentation; it allows to explicitly model the learning dynamics, and reconcile the learning of multiple objectives (up to ten in our experiments); with an end-to-end architecture, it generalizes to different datasets without the need of re-tuning hyperparameters or re-adjusting the training process laboriously. Our Ada-Segment brings 2.7% panoptic quality (PQ) improvement on COCO val split from the vanilla baseline, achieving the state-of-the-art 48.5% PQ on COCO test-dev split and 32.9% PQ on ADE20K dataset. The extensive ablation studies reveal the ever-changing dynamics throughout the training process, necessitating the incorporation of an automated and adaptive learning strategy as presented in this paper.