 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Perceptual Artifacts: A Fine-Grained Benchmark for Interpretable AI-Generated Image Detection
Jan 27, 2026Current AI-Generated Image (AIGI) detection approaches predominantly rely on binary classification to distinguish real from synthetic images, often lacking interpretable or convincing evidence to substantiate their decisions. This limitation stems from existing AIGI detection benchmarks, which, despite featuring a broad collection of synthetic images, remain restricted in their coverage of artifact diversity and lack detailed, localized annotations. To bridge this gap, we introduce a fine-grained benchmark towards eXplainable AI-Generated image Detection, named X-AIGD, which provides pixel-level, categorized annotations of perceptual artifacts, spanning low-level distortions, high-level semantics, and cognitive-level counterfactuals. These comprehensive annotations facilitate fine-grained interpretability evaluation and deeper insight into model decision-making processes. Our extensive investigation using X-AIGD provides several key insights: (1) Existing AIGI detectors demonstrate negligible reliance on perceptual artifacts, even at the most basic distortion level. (2) While AIGI detectors can be trained to identify specific artifacts, they still substantially base their judgment on uninterpretable features. (3) Explicitly aligning model attention with artifact regions can increase the interpretability and generalization of detectors. The data and code are available at: https://github.com/Coxy7/X-AIGD.
Zippo: Zipping Color and Transparency Distributions into a Single Diffusion Model
Mar 19, 2024



Beyond the superiority of the text-to-image diffusion model in generating high-quality images, recent studies have attempted to uncover its potential for adapting the learned semantic knowledge to visual perception tasks. In this work, instead of translating a generative diffusion model into a visual perception model, we explore to retain the generative ability with the perceptive adaptation. To accomplish this, we present Zippo, a unified framework for zipping the color and transparency distributions into a single diffusion model by expanding the diffusion latent into a joint representation of RGB images and alpha mattes. By alternatively selecting one modality as the condition and then applying the diffusion process to the counterpart modality, Zippo is capable of generating RGB images from alpha mattes and predicting transparency from input images. In addition to single-modality prediction, we propose a modality-aware noise reassignment strategy to further empower Zippo with jointly generating RGB images and its corresponding alpha mattes under the text guidance. Our experiments showcase Zippo's ability of efficient text-conditioned transparent image generation and present plausible results of Matte-to-RGB and RGB-to-Matte translation.
DiffCloth: Diffusion Based Garment Synthesis and Manipulation via Structural Cross-modal Semantic Alignment
Aug 22, 2023Cross-modal garment synthesis and manipulation will significantly benefit the way fashion designers generate garments and modify their designs via flexible linguistic interfaces.Current approaches follow the general text-to-image paradigm and mine cross-modal relations via simple cross-attention modules, neglecting the structural correspondence between visual and textual representations in the fashion design domain. In this work, we instead introduce DiffCloth, a diffusion-based pipeline for cross-modal garment synthesis and manipulation, which empowers diffusion models with flexible compositionality in the fashion domain by structurally aligning the cross-modal semantics. Specifically, we formulate the part-level cross-modal alignment as a bipartite matching problem between the linguistic Attribute-Phrases (AP) and the visual garment parts which are obtained via constituency parsing and semantic segmentation, respectively. To mitigate the issue of attribute confusion, we further propose a semantic-bundled cross-attention to preserve the spatial structure similarities between the attention maps of attribute adjectives and part nouns in each AP. Moreover, DiffCloth allows for manipulation of the generated results by simply replacing APs in the text prompts. The manipulation-irrelevant regions are recognized by blended masks obtained from the bundled attention maps of the APs and kept unchanged. Extensive experiments on the CM-Fashion benchmark demonstrate that DiffCloth both yields state-of-the-art garment synthesis results by leveraging the inherent structural information and supports flexible manipulation with region consistency.
LAW-Diffusion: Complex Scene Generation by Diffusion with Layouts
Aug 13, 2023



Thanks to the rapid development of diffusion models, unprecedented progress has been witnessed in image synthesis. Prior works mostly rely on pre-trained linguistic models, but a text is often too abstract to properly specify all the spatial properties of an image, e.g., the layout configuration of a scene, leading to the sub-optimal results of complex scene generation. In this paper, we achieve accurate complex scene generation by proposing a semantically controllable Layout-AWare diffusion model, termed LAW-Diffusion. Distinct from the previous Layout-to-Image generation (L2I) methods that only explore category-aware relationships, LAW-Diffusion introduces a spatial dependency parser to encode the location-aware semantic coherence across objects as a layout embedding and produces a scene with perceptually harmonious object styles and contextual relations. To be specific, we delicately instantiate each object's regional semantics as an object region map and leverage a location-aware cross-object attention module to capture the spatial dependencies among those disentangled representations. We further propose an adaptive guidance schedule for our layout guidance to mitigate the trade-off between the regional semantic alignment and the texture fidelity of generated objects. Moreover, LAW-Diffusion allows for instance reconfiguration while maintaining the other regions in a synthesized image by introducing a layout-aware latent grafting mechanism to recompose its local regional semantics. To better verify the plausibility of generated scenes, we propose a new evaluation metric for the L2I task, dubbed Scene Relation Score (SRS) to measure how the images preserve the rational and harmonious relations among contextual objects. Comprehensive experiments demonstrate that our LAW-Diffusion yields the state-of-the-art generative performance, especially with coherent object relations.
Continual Object Detection via Prototypical Task Correlation Guided Gating Mechanism
May 06, 2022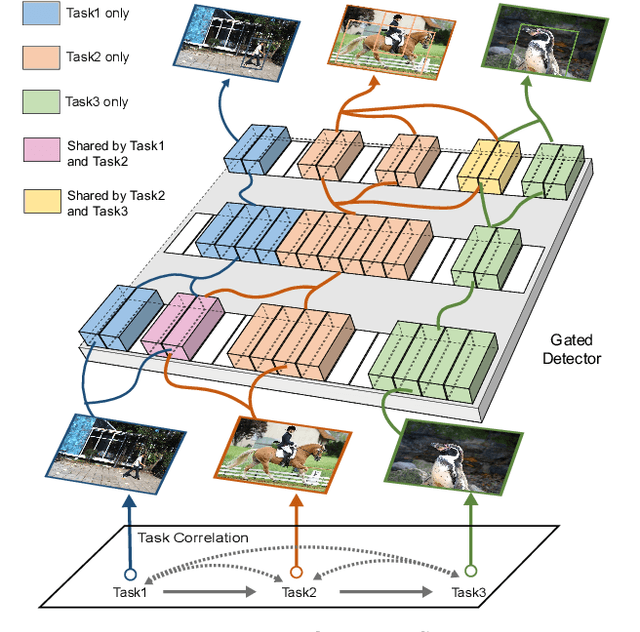
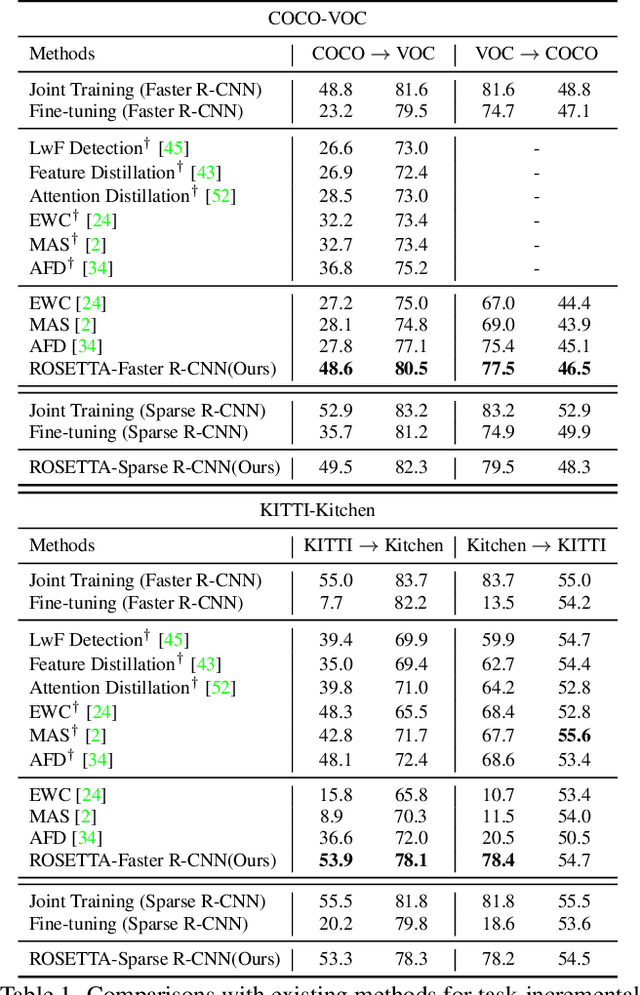
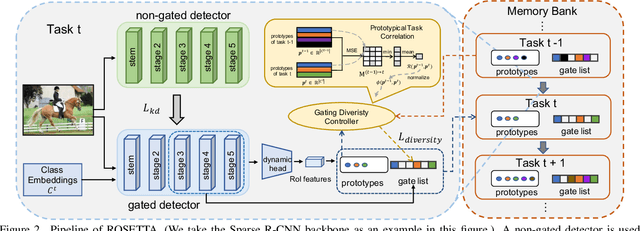
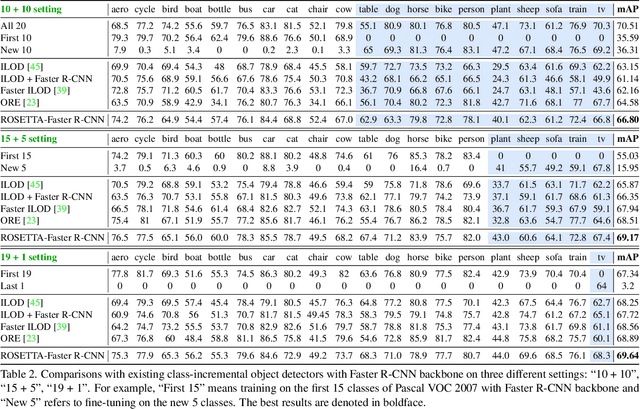
Continual learning is a challenging real-world problem for constructing a mature AI system when data are provided in a streaming fashion. Despite recent progress in continual classification, the researches of continual object detection are impeded by the diverse sizes and numbers of objects in each image. Different from previous works that tune the whole network for all tasks, in this work, we present a simple and flexible framework for continual object detection via pRotOtypical taSk corrElaTion guided gaTing mechAnism (ROSETTA). Concretely, a unified framework is shared by all tasks while task-aware gates are introduced to automatically select sub-models for specific tasks. In this way, various knowledge can be successively memorized by storing their corresponding sub-model weights in this system. To make ROSETTA automatically determine which experience is available and useful, a prototypical task correlation guided Gating Diversity Controller(GDC) is introduced to adaptively adjust the diversity of gates for the new task based on class-specific prototypes. GDC module computes class-to-class correlation matrix to depict the cross-task correlation, and hereby activates more exclusive gates for the new task if a significant domain gap is observed. Comprehensive experiments on COCO-VOC, KITTI-Kitchen, class-incremental detection on VOC and sequential learning of four tasks show that ROSETTA yields state-of-the-art performance on both task-based and class-based continual object detection.
Depthwise Non-local Module for Fast Salient Object Detection Using a Single Thread
Jan 22, 2020
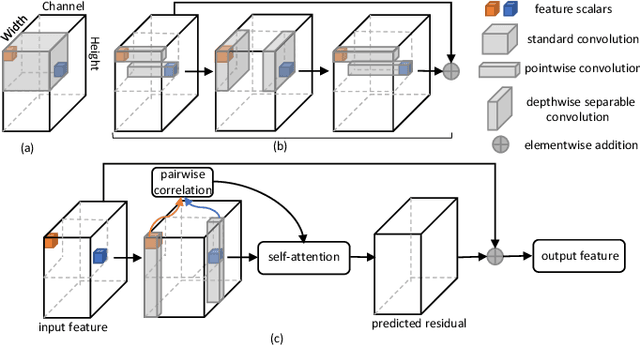
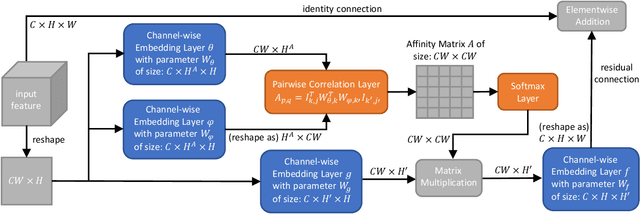
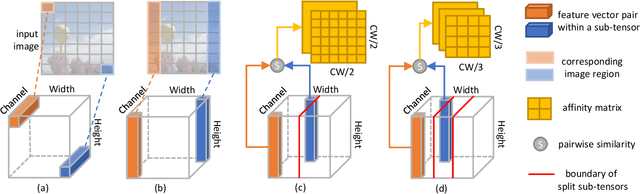
Recently deep convolutional neural networks have achieved significant success in salient object detection. However, existing state-of-the-art methods require high-end GPUs to achieve real-time performance, which makes them hard to adapt to low-cost or portable devices. Although generic network architectures have been proposed to speed up inference on mobile devices, they are tailored to the task of image classification or semantic segmentation, and struggle to capture intra-channel and inter-channel correlations that are essential for contrast modeling in salient object detection. Motivated by the above observations, we design a new deep learning algorithm for fast salient object detection. The proposed algorithm for the first time achieves competitive accuracy and high inference efficiency simultaneously with a single CPU thread. Specifically, we propose a novel depthwise non-local moudule (DNL), which implicitly models contrast via harvesting intra-channel and inter-channel correlations in a self-attention manner. In addition, we introduce a depthwise non-local network architecture that incorporates both depthwise non-local modules and inverted residual blocks. Experimental results show that our proposed network attains very competitive accuracy on a wide range of salient object detection datasets while achieving state-of-the-art efficiency among all existing deep learning based algorithms.
FD-FCN: 3D Fully Dense and Fully Convolutional Network for Semantic Segmentation of Brain Anatomy
Jul 22, 2019

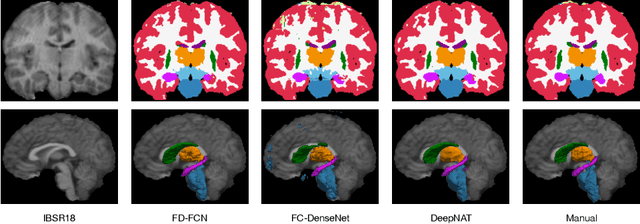
In this paper, a 3D patch-based fully dense and fully convolutional network (FD-FCN) is proposed for fast and accurate segmentation of subcortical structures in T1-weighted magnetic resonance images. Developed from the seminal FCN with an end-to-end learning-based approach and constructed by newly designed dense blocks including a dense fully-connected layer, the proposed FD-FCN is different from other FCN-based methods and leads to an outperformance in the perspective of both efficiency and accuracy. Compared with the U-shaped architecture, FD-FCN discards the upsampling path for model fitness. To alleviate the problem of parameter explosion, the inputs of dense blocks are no longer directly passed to subsequent layers. This architecture of FD-FCN brings a great reduction on both memory and time consumption in training process. Although FD-FCN is slimmed down, in model competence it gains better capability of dense inference than other conventional networks. This benefits from the construction of network architecture and the incorporation of redesigned dense blocks. The multi-scale FD-FCN models both local and global context by embedding intermediate-layer outputs in the final prediction, which encourages consistency between features extracted at different scales and embeds fine-grained information directly in the segmentation process. In addition, dense blocks are rebuilt to enlarge the receptive fields without significantly increasing parameters, and spectral coordinates are exploited for spatial context of the original input patch. The experiments were performed over the IBSR dataset, and FD-FCN produced an accurate segmentation result of overall Dice overlap value of 89.81% for 11 brain structures in 53 seconds, with at least 3.66% absolute improvement of dice accuracy than state-of-the-art 3D FCN-based methods.