 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Tracking Improves World Action Models
May 22, 2026Robot policy learning benefits from world-action models that capture environment dynamics, but pixel-level prediction entangles dynamics with nuisance factors such as lighting and texture, making learned representations vulnerable to task-irrelevant visual variation. We propose JOPAT, a JOint Pixel-And-Track World-Action Model that predicts latent visual observations, 2D point tracks with visibility, and actions in a single denoising diffusion transformer. The key insight is that tracks provide an explicit representation of motion that captures long-horizon dynamics and remains robust under occlusion or partial out-of-frame motion, offering greater utility than modeling pixel appearance alone. On LIBERO and real-world LeRobot tasks, JOPAT improves over pixel-based baselines, with the largest gains on long-horizon tasks involving occlusion, object interaction, and off-screen motion.
Why Keep Your Doubts to Yourself? Trading Visual Uncertainties in Multi-Agent Bandit Systems
Jan 26, 2026Vision-Language Models (VLMs) enable powerful multi-agent systems, but scaling them is economically unsustainable: coordinating heterogeneous agents under information asymmetry often spirals costs. Existing paradigms, such as Mixture-of-Agents and knowledge-based routers, rely on heuristic proxies that ignore costs and collapse uncertainty structure, leading to provably suboptimal coordination. We introduce Agora, a framework that reframes coordination as a decentralized market for uncertainty. Agora formalizes epistemic uncertainty into a structured, tradable asset (perceptual, semantic, inferential), and enforces profitability-driven trading among agents based on rational economic rules. A market-aware broker, extending Thompson Sampling, initiates collaboration and guides the system toward cost-efficient equilibria. Experiments on five multimodal benchmarks (MMMU, MMBench, MathVision, InfoVQA, CC-OCR) show that Agora outperforms strong VLMs and heuristic multi-agent strategies, e.g., achieving +8.5% accuracy over the best baseline on MMMU while reducing cost by over 3x. These results establish market-based coordination as a principled and scalable paradigm for building economically viable multi-agent visual intelligence systems.
Self-Rewarded Multimodal Coherent Reasoning Across Diverse Visual Domains
Dec 27, 2025Multimodal LLMs often produce fluent yet unreliable reasoning, exhibiting weak step-to-step coherence and insufficient visual grounding, largely because existing alignment approaches supervise only the final answer while ignoring the reliability of the intermediate reasoning process. We introduce SR-MCR, a lightweight and label-free framework that aligns reasoning by exploiting intrinsic process signals derived directly from model outputs. Five self-referential cues -- semantic alignment, lexical fidelity, non-redundancy, visual grounding, and step consistency -- are integrated into a normalized, reliability-weighted reward that provides fine-grained process-level guidance. A critic-free GRPO objective, enhanced with a confidence-aware cooling mechanism, further stabilizes training and suppresses trivial or overly confident generations. Built on Qwen2.5-VL, SR-MCR improves both answer accuracy and reasoning coherence across a broad set of visual benchmarks; among open-source models of comparable size, SR-MCR-7B achieves state-of-the-art performance with an average accuracy of 81.4%. Ablation studies confirm the independent contributions of each reward term and the cooling module.
MM-CoT:A Benchmark for Probing Visual Chain-of-Thought Reasoning in Multimodal Models
Dec 09, 2025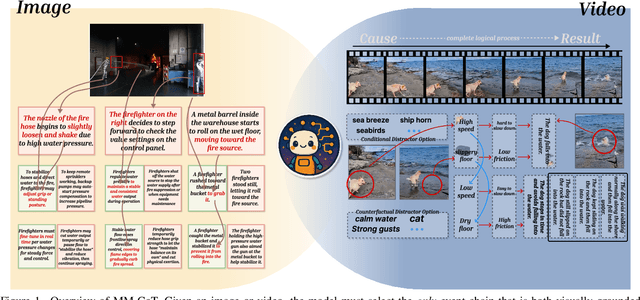
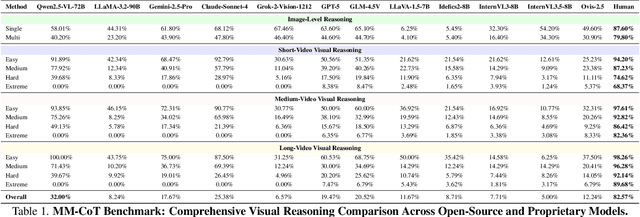
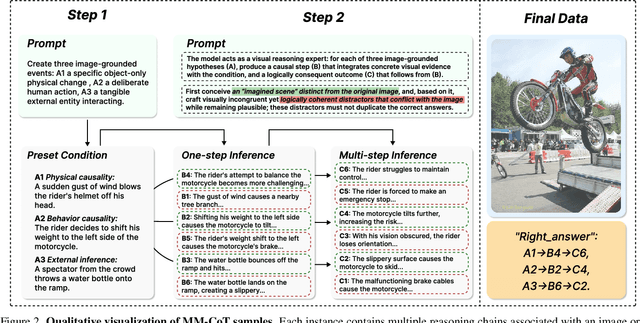
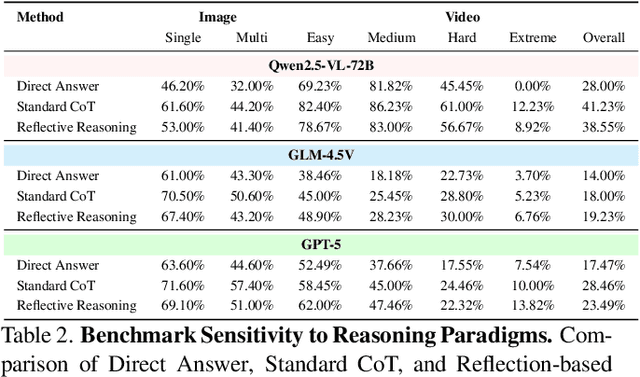
The ability to perform Chain-of-Thought (CoT) reasoning marks a major milestone for multimodal models (MMs), enabling them to solve complex visual reasoning problems. Yet a critical question remains: is such reasoning genuinely grounded in visual evidence and logically coherent? Existing benchmarks emphasize generation but neglect verification, i.e., the capacity to assess whether a reasoning chain is both visually consistent and logically valid. To fill this gap, we introduce MM-CoT, a diagnostic benchmark specifically designed to probe the visual grounding and logical coherence of CoT reasoning in MMs. Instead of generating free-form explanations, models must select the sole event chain that satisfies two orthogonal constraints: (i) visual consistency, ensuring all steps are anchored in observable evidence, and (ii) logical coherence, ensuring causal and commonsense validity. Adversarial distractors are engineered to violate one of these constraints, exposing distinct reasoning failures. We evaluate leading vision-language models on MM-CoT and find that even the most advanced systems struggle, revealing a sharp discrepancy between generative fluency and true reasoning fidelity. MM-CoT shows low correlation with existing benchmarks, confirming that it measures a unique combination of visual grounding and logical reasoning. This benchmark provides a foundation for developing future models that reason not just plausibly, but faithfully and coherently within the visual world.
Understanding Hardness of Vision-Language Compositionality from A Token-level Causal Lens
Oct 30, 2025Contrastive Language-Image Pre-training (CLIP) delivers strong cross modal generalization by aligning images and texts in a shared embedding space, yet it persistently fails at compositional reasoning over objects, attributes, and relations often behaving like a bag-of-words matcher. Prior causal accounts typically model text as a single vector, obscuring token-level structure and leaving core phenomena-such as prompt sensitivity and failures on hard negatives unexplained. We address this gap with a token-aware causal representation learning (CRL) framework grounded in a sequential, language-token SCM. Our theory extends block identifiability to tokenized text, proving that CLIP's contrastive objective can recover the modal-invariant latent variable under both sentence-level and token-level SCMs. Crucially, token granularity yields the first principled explanation of CLIP's compositional brittleness: composition nonidentifiability. We show the existence of pseudo-optimal text encoders that achieve perfect modal-invariant alignment yet are provably insensitive to SWAP, REPLACE, and ADD operations over atomic concepts, thereby failing to distinguish correct captions from hard negatives despite optimizing the same training objective as true-optimal encoders. The analysis further links language-side nonidentifiability to visual-side failures via the modality gap and shows how iterated composition operators compound hardness, motivating improved negative mining strategies.
MM-OPERA: Benchmarking Open-ended Association Reasoning for Large Vision-Language Models
Oct 30, 2025Large Vision-Language Models (LVLMs) have exhibited remarkable progress. However, deficiencies remain compared to human intelligence, such as hallucination and shallow pattern matching. In this work, we aim to evaluate a fundamental yet underexplored intelligence: association, a cornerstone of human cognition for creative thinking and knowledge integration. Current benchmarks, often limited to closed-ended tasks, fail to capture the complexity of open-ended association reasoning vital for real-world applications. To address this, we present MM-OPERA, a systematic benchmark with 11,497 instances across two open-ended tasks: Remote-Item Association (RIA) and In-Context Association (ICA), aligning association intelligence evaluation with human psychometric principles. It challenges LVLMs to resemble the spirit of divergent thinking and convergent associative reasoning through free-form responses and explicit reasoning paths. We deploy tailored LLM-as-a-Judge strategies to evaluate open-ended outputs, applying process-reward-informed judgment to dissect reasoning with precision. Extensive empirical studies on state-of-the-art LVLMs, including sensitivity analysis of task instances, validity analysis of LLM-as-a-Judge strategies, and diversity analysis across abilities, domains, languages, cultures, etc., provide a comprehensive and nuanced understanding of the limitations of current LVLMs in associative reasoning, paving the way for more human-like and general-purpose AI. The dataset and code are available at https://github.com/MM-OPERA-Bench/MM-OPERA.
An Exhaustive DPLL Approach to Model Counting over Integer Linear Constraints with Simplification Techniques
Sep 17, 2025Linear constraints are one of the most fundamental constraints in fields such as computer science, operations research and optimization. Many applications reduce to the task of model counting over integer linear constraints (MCILC). In this paper, we design an exact approach to MCILC based on an exhaustive DPLL architecture. To improve the efficiency, we integrate several effective simplification techniques from mixed integer programming into the architecture. We compare our approach to state-of-the-art MCILC counters and propositional model counters on 2840 random and 4131 application benchmarks. Experimental results show that our approach significantly outperforms all exact methods in random benchmarks solving 1718 instances while the state-of-the-art approach only computes 1470 instances. In addition, our approach is the only approach to solve all 4131 application instances.
Learning to See and Act: Task-Aware View Planning for Robotic Manipulation
Aug 07, 2025Recent vision-language-action (VLA) models for multi-task robotic manipulation commonly rely on static viewpoints and shared visual encoders, which limit 3D perception and cause task interference, hindering robustness and generalization. In this work, we propose Task-Aware View Planning (TAVP), a framework designed to overcome these challenges by integrating active view planning with task-specific representation learning. TAVP employs an efficient exploration policy, accelerated by a novel pseudo-environment, to actively acquire informative views. Furthermore, we introduce a Mixture-of-Experts (MoE) visual encoder to disentangle features across different tasks, boosting both representation fidelity and task generalization. By learning to see the world in a task-aware way, TAVP generates more complete and discriminative visual representations, demonstrating significantly enhanced action prediction across a wide array of manipulation challenges. Extensive experiments on RLBench tasks show that our proposed TAVP model achieves superior performance over state-of-the-art fixed-view approaches. Visual results and code are provided at: https://hcplab-sysu.github.io/TAVP.
Beyond the Destination: A Novel Benchmark for Exploration-Aware Embodied Question Answering
Mar 14, 2025



Embodied Question Answering (EQA) is a challenging task in embodied intelligence that requires agents to dynamically explore 3D environments, actively gather visual information, and perform multi-step reasoning to answer questions. However, current EQA approaches suffer from critical limitations in exploration efficiency, dataset design, and evaluation metrics. Moreover, existing datasets often introduce biases or prior knowledge, leading to disembodied reasoning, while frontier-based exploration strategies struggle in cluttered environments and fail to ensure fine-grained exploration of task-relevant areas. To address these challenges, we construct the EXPloration-awaRe Embodied queStion anSwering Benchmark (EXPRESS-Bench), the largest dataset designed specifically to evaluate both exploration and reasoning capabilities. EXPRESS-Bench consists of 777 exploration trajectories and 2,044 question-trajectory pairs. To improve exploration efficiency, we propose Fine-EQA, a hybrid exploration model that integrates frontier-based and goal-oriented navigation to guide agents toward task-relevant regions more effectively. Additionally, we introduce a novel evaluation metric, Exploration-Answer Consistency (EAC), which ensures faithful assessment by measuring the alignment between answer grounding and exploration reliability. Extensive experimental comparisons with state-of-the-art EQA models demonstrate the effectiveness of our EXPRESS-Bench in advancing embodied exploration and question reasoning.
De-singularity Subgradient for the $q$-th-Powered $\ell_p$-Norm Weber Location Problem
Dec 20, 2024The Weber location problem is widely used in several artificial intelligence scenarios. However, the gradient of the objective does not exist at a considerable set of singular points. Recently, a de-singularity subgradient method has been proposed to fix this problem, but it can only handle the $q$-th-powered $\ell_2$-norm case ($1\leqslant q<2$), which has only finite singular points. In this paper, we further establish the de-singularity subgradient for the $q$-th-powered $\ell_p$-norm case with $1\leqslant q\leqslant p$ and $1\leqslant p<2$, which includes all the rest unsolved situations in this problem. This is a challenging task because the singular set is a continuum. The geometry of the objective function is also complicated so that the characterizations of the subgradients, minimum and descent direction are very difficult. We develop a $q$-th-powered $\ell_p$-norm Weiszfeld Algorithm without Singularity ($q$P$p$NWAWS) for this problem, which ensures convergence and the descent property of the objective function. Extensive experiments on six real-world data sets demonstrate that $q$P$p$NWAWS successfully solves the singularity problem and achieves a linear computational convergence rate in practical scenarios.