 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parallel Approach to Counting Exact Covers Based on Decomposability Property
Apr 16, 2026The exact cover problem is a classical NP-hard problem with broad applications in the area of AI. Algorithm DXZ is a method to count exact covers representing by zero-suppressed binary decision diagrams (ZBDDs). In this paper, we propose a zero-suppressed variant of decision decomposable negation normal form (in short, decision-ZDNNF), which is strictly more succinct than ZBDDs. We then design a novel parallel algorithm, namely DXD, which constructs a decision-ZDNNF representing the set of all exact covers. Furthermore, we improve DXD by dynamically updating connected components. The experimental results demonstrate that the improved DXD algorithm outperforms all of state-of-the-art methods.
AgentSentry: Mitigating Indirect Prompt Injection in LLM Agents via Temporal Causal Diagnostics and Context Purification
Feb 26, 2026Large language model (LLM) agents increasingly rely on external tools and retrieval systems to autonomously complete complex tasks. However, this design exposes agents to indirect prompt injection (IPI), where attacker-controlled context embedded in tool outputs or retrieved content silently steers agent actions away from user intent. Unlike prompt-based attacks, IPI unfolds over multi-turn trajectories, making malicious control difficult to disentangle from legitimate task execution. Existing inference-time defenses primarily rely on heuristic detection and conservative blocking of high-risk actions, which can prematurely terminate workflows or broadly suppress tool usage under ambiguous multi-turn scenarios. We propose AgentSentry, a novel inference-time detection and mitigation framework for tool-augmented LLM agents. To the best of our knowledge, AgentSentry is the first inference-time defense to model multi-turn IPI as a temporal causal takeover. It localizes takeover points via controlled counterfactual re-executions at tool-return boundaries and enables safe continuation through causally guided context purification that removes attack-induced deviations while preserving task-relevant evidence. We evaluate AgentSentry on the \textsc{AgentDojo} benchmark across four task suites, three IPI attack families, and multiple black-box LLMs. AgentSentry eliminates successful attacks and maintains strong utility under attack, achieving an average Utility Under Attack (UA) of 74.55 %, improving UA by 20.8 to 33.6 percentage points over the strongest baselines without degrading benign performance.
An Exhaustive DPLL Approach to Model Counting over Integer Linear Constraints with Simplification Techniques
Sep 17, 2025Linear constraints are one of the most fundamental constraints in fields such as computer science, operations research and optimization. Many applications reduce to the task of model counting over integer linear constraints (MCILC). In this paper, we design an exact approach to MCILC based on an exhaustive DPLL architecture. To improve the efficiency, we integrate several effective simplification techniques from mixed integer programming into the architecture. We compare our approach to state-of-the-art MCILC counters and propositional model counters on 2840 random and 4131 application benchmarks. Experimental results show that our approach significantly outperforms all exact methods in random benchmarks solving 1718 instances while the state-of-the-art approach only computes 1470 instances. In addition, our approach is the only approach to solve all 4131 application instances.
Unveiling the Tapestry of Automated Essay Scoring: A Comprehensive Investigation of Accuracy, Fairness, and Generalizability
Jan 11, 2024



Automatic Essay Scoring (AES) is a well-established educational pursuit that employs machine learning to evaluate student-authored essays. While much effort has been made in this area, current research primarily focuses on either (i) boosting the predictive accuracy of an AES model for a specific prompt (i.e., developing prompt-specific models), which often heavily relies on the use of the labeled data from the same target prompt; or (ii) assessing the applicability of AES models developed on non-target prompts to the intended target prompt (i.e., developing the AES models in a cross-prompt setting). Given the inherent bias in machine learning and its potential impact on marginalized groups, it is imperative to investigate whether such bias exists in current AES methods and, if identified, how it intervenes with an AES model's accuracy and generalizability. Thus, our study aimed to uncover the intricate relationship between an AES model's accuracy, fairness, and generalizability, contributing practical insights for developing effective AES models in real-world education. To this end, we meticulously selected nine prominent AES methods and evaluated their performance using seven metrics on an open-sourced dataset, which contains over 25,000 essays and various demographic information about students such as gender, English language learner status, and economic status. Through extensive evaluations, we demonstrated that: (1) prompt-specific models tend to outperform their cross-prompt counterparts in terms of predictive accuracy; (2) prompt-specific models frequently exhibit a greater bias towards students of different economic statuses compared to cross-prompt models; (3) in the pursuit of generalizability, traditional machine learning models coupled with carefully engineered features hold greater potential for achieving both high accuracy and fairness than complex neural network models.
Diagnosing and Rectifying Fake OOD Invariance: A Restructured Causal Approach
Dec 15, 2023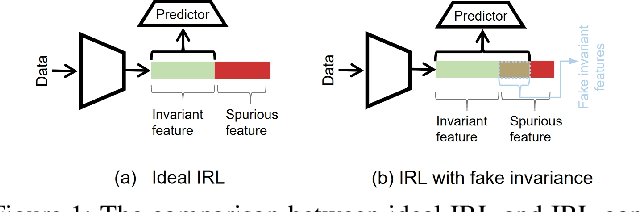

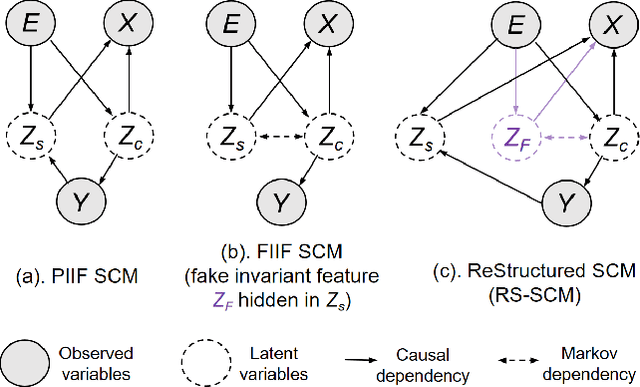
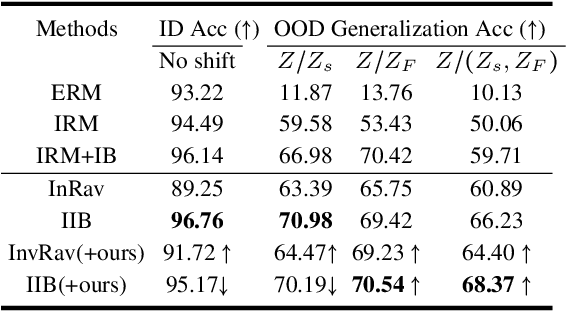
Invariant representation learning (IRL) encourages the prediction from invariant causal features to labels de-confounded from the environments, advancing the technical roadmap of out-of-distribution (OOD) generalization. Despite spotlights around, recent theoretical results verified that some causal features recovered by IRLs merely pretend domain-invariantly in the training environments but fail in unseen domains. The \emph{fake invariance} severely endangers OOD generalization since the trustful objective can not be diagnosed and existing causal surgeries are invalid to rectify. In this paper, we review a IRL family (InvRat) under the Partially and Fully Informative Invariant Feature Structural Causal Models (PIIF SCM /FIIF SCM) respectively, to certify their weaknesses in representing fake invariant features, then, unify their causal diagrams to propose ReStructured SCM (RS-SCM). RS-SCM can ideally rebuild the spurious and the fake invariant features simultaneously. Given this, we further develop an approach based on conditional mutual information with respect to RS-SCM, then rigorously rectify the spurious and fake invariant effects. It can be easily implemented by a small feature selection subnet introduced in the IRL family, which is alternatively optimized to achieve our goal. Experiments verified the superiority of our approach to fight against the fake invariant issue across a variety of OOD generalization benchmarks.
Variants of Tagged Sentential Decision Diagrams
Nov 16, 2023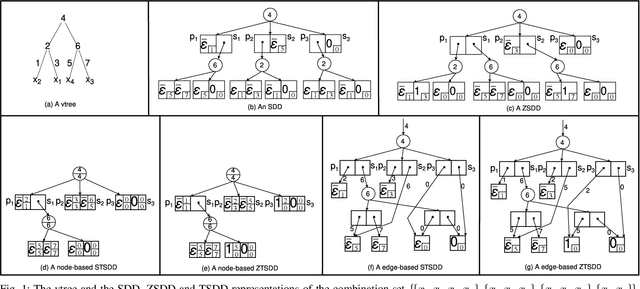

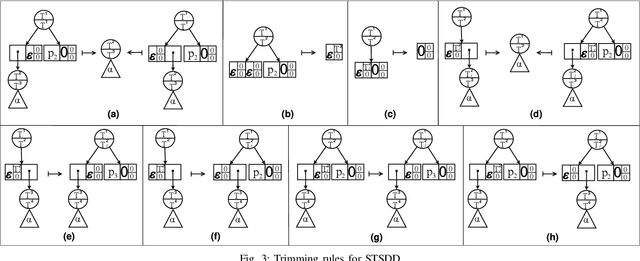
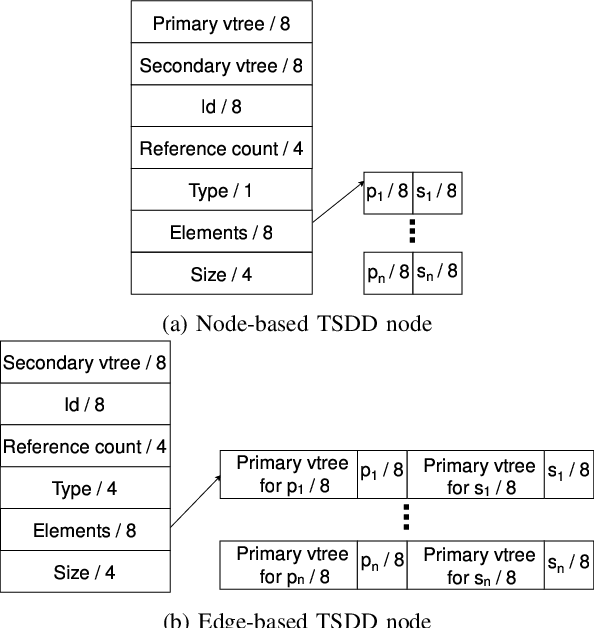
A recently proposed canonical form of Boolean functions, namely tagged sentential decision diagrams (TSDDs), exploits both the standard and zero-suppressed trimming rules. The standard ones minimize the size of sentential decision diagrams (SDDs) while the zero-suppressed trimming rules have the same objective as the standard ones but for zero-suppressed sentential decision diagrams (ZSDDs). The original TSDDs, which we call zero-suppressed TSDDs (ZTSDDs), firstly fully utilize the zero-suppressed trimming rules, and then the standard ones. In this paper, we present a variant of TSDDs which we call standard TSDDs (STSDDs) by reversing the order of trimming rules. We then prove the canonicity of STSDDs and present the algorithms for binary operations on TSDDs. In addition, we offer two kinds of implementations of STSDDs and ZTSDDs and acquire three variations of the original TSDDs. Experimental evaluations demonstrate that the four versions of TSDDs have the size advantage over SDDs and ZSDDs.
An Investigation of Darwiche and Pearl's Postulates for Iterated Belief Update
Oct 28, 2023


Belief revision and update, two significant types of belief change, both focus on how an agent modify her beliefs in presence of new information. The most striking difference between them is that the former studies the change of beliefs in a static world while the latter concentrates on a dynamically-changing world. The famous AGM and KM postulates were proposed to capture rational belief revision and update, respectively. However, both of them are too permissive to exclude some unreasonable changes in the iteration. In response to this weakness, the DP postulates and its extensions for iterated belief revision were presented. Furthermore, Rodrigues integrated these postulates in belief update. Unfortunately, his approach does not meet the basic requirement of iterated belief update. This paper is intended to solve this problem of Rodrigues's approach. Firstly, we present a modification of the original KM postulates based on belief states. Subsequently, we migrate several well-known postulates for iterated belief revision to iterated belief update. Moreover, we provide the exact semantic characterizations based on partial preorders for each of the proposed postulates. Finally, we analyze the compatibility between the above iterated postulates and the KM postulates for belief update.
VSRQ: Quantitative Assessment Method for Safety Risk of Vehicle Intelligent Connected System
May 03, 2023



The field of intelligent connected in modern vehicles continues to expand, and the functions of vehicles become more and more complex with the development of the times. This has also led to an increasing number of vehicle vulnerabilities and many safety issues. Therefore, it is particularly important to identify high-risk vehicle intelligent connected systems, because it can inform security personnel which systems are most vulnerable to attacks, allowing them to conduct more thorough inspections and tests. In this paper, we develop a new model for vehicle risk assessment by combining I-FAHP with FCA clustering: VSRQ model. We extract important indicators related to vehicle safety, use fuzzy cluster analys (FCA) combined with fuzzy analytic hierarchy process (FAHP) to mine the vulnerable components of the vehicle intelligent connected system, and conduct priority testing on vulnerable components to reduce risks and ensure vehicle safety. We evaluate the model on OpenPilot and experimentally demonstrate the effectiveness of the VSRQ model in identifying the safety of vehicle intelligent connected systems. The experiment fully complies with ISO 26262 and ISO/SAE 21434 standards, and our model has a higher accuracy rate than other models. These results provide a promising new research direction for predicting the security risks of vehicle intelligent connected systems and provide typical application tasks for VSRQ. The experimental results show that the accuracy rate is 94.36%, and the recall rate is 73.43%, which is at least 14.63% higher than all other known indicators.