 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes the Prompt-based Large Language Model Recognize Students' Demographics and Introduce Bias in Essay Scoring?
Apr 30, 2025Large Language Models (LLMs) are widely used in Automated Essay Scoring (AES) due to their ability to capture semantic meaning. Traditional fine-tuning approaches required technical expertise, limiting accessibility for educators with limited technical backgrounds. However, prompt-based tools like ChatGPT have made AES more accessible, enabling educators to obtain machine-generated scores using natural-language prompts (i.e., the prompt-based paradigm). Despite advancements, prior studies have shown bias in fine-tuned LLMs, particularly against disadvantaged groups. It remains unclear whether such biases persist or are amplified in the prompt-based paradigm with cutting-edge tools. Since such biases are believed to stem from the demographic information embedded in pre-trained models (i.e., the ability of LLMs' text embeddings to predict demographic attributes), this study explores the relationship between the model's predictive power of students' demographic attributes based on their written works and its predictive bias in the scoring task in the prompt-based paradigm. Using a publicly available dataset of over 25,000 students' argumentative essays, we designed prompts to elicit demographic inferences (i.e., gender, first-language background) from GPT-4o and assessed fairness in automated scoring. Then we conducted multivariate regression analysis to explore the impact of the model's ability to predict demographics on its scoring outcomes. Our findings revealed that (i) prompt-based LLMs can somewhat infer students' demographics, particularly their first-language backgrounds, from their essays; (ii) scoring biases are more pronounced when the LLM correctly predicts students' first-language background than when it does not; and (iii) scoring error for non-native English speakers increases when the LLM correctly identifies them as non-native.
Modifying AI, Enhancing Essays: How Active Engagement with Generative AI Boosts Writing Quality
Dec 10, 2024Students are increasingly relying on Generative AI (GAI) to support their writing-a key pedagogical practice in education. In GAI-assisted writing, students can delegate core cognitive tasks (e.g., generating ideas and turning them into sentences) to GAI while still producing high-quality essays. This creates new challenges for teachers in assessing and supporting student learning, as they often lack insight into whether students are engaging in meaningful cognitive processes during writing or how much of the essay's quality can be attributed to those processes. This study aimed to help teachers better assess and support student learning in GAI-assisted writing by examining how different writing behaviors, especially those indicative of meaningful learning versus those that are not, impact essay quality. Using a dataset of 1,445 GAI-assisted writing sessions, we applied the cutting-edge method, X-Learner, to quantify the causal impact of three GAI-assisted writing behavioral patterns (i.e., seeking suggestions but not accepting them, seeking suggestions and accepting them as they are, and seeking suggestions and accepting them with modification) on four measures of essay quality (i.e., lexical sophistication, syntactic complexity, text cohesion, and linguistic bias). Our analysis showed that writers who frequently modified GAI-generated text-suggesting active engagement in higher-order cognitive processes-consistently improved the quality of their essays in terms of lexical sophistication, syntactic complexity, and text cohesion. In contrast, those who often accepted GAI-generated text without changes, primarily engaging in lower-order processes, saw a decrease in essay quality. Additionally, while human writers tend to introduce linguistic bias when writing independently, incorporating GAI-generated text-even without modification-can help mitigate this bias.
Towards Detecting AI-Generated Text within Human-AI Collaborative Hybrid Texts
Mar 06, 2024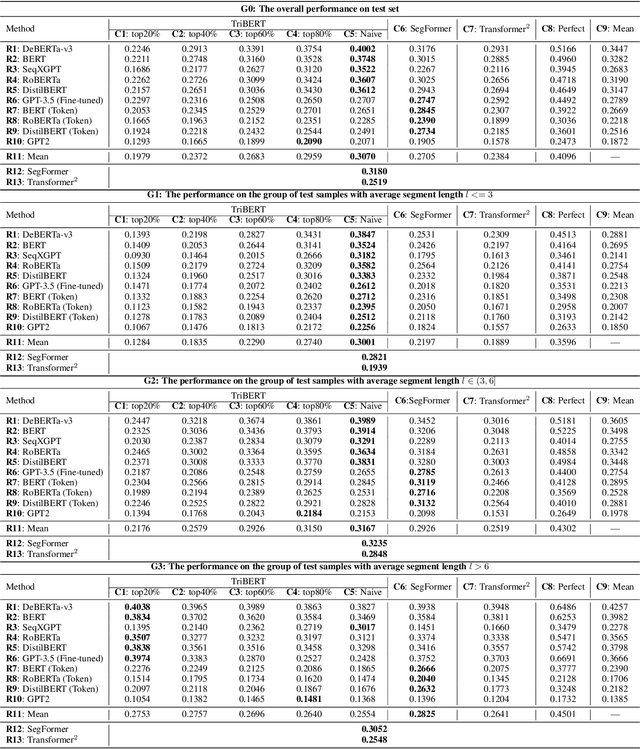
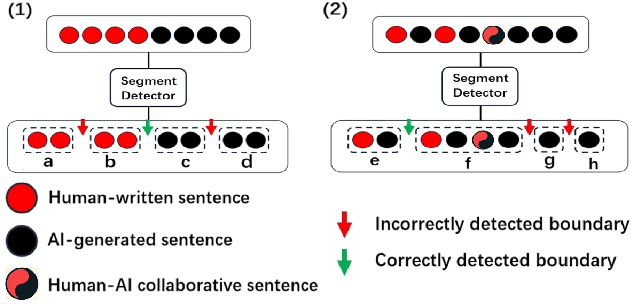
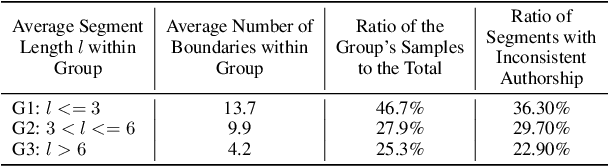
This study explores the challenge of sentence-level AI-generated text detection within human-AI collaborative hybrid texts. Existing studies of AI-generated text detection for hybrid texts often rely on synthetic datasets. These typically involve hybrid texts with a limited number of boundaries. We contend that studies of detecting AI-generated content within hybrid texts should cover different types of hybrid texts generated in realistic settings to better inform real-world applications. Therefore, our study utilizes the CoAuthor dataset, which includes diverse, realistic hybrid texts generated through the collaboration between human writers and an intelligent writing system in multi-turn interactions. We adopt a two-step, segmentation-based pipeline: (i) detect segments within a given hybrid text where each segment contains sentences of consistent authorship, and (ii) classify the authorship of each identified segment. Our empirical findings highlight (1) detecting AI-generated sentences in hybrid texts is overall a challenging task because (1.1) human writers' selecting and even editing AI-generated sentences based on personal preferences adds difficulty in identifying the authorship of segments; (1.2) the frequent change of authorship between neighboring sentences within the hybrid text creates difficulties for segment detectors in identifying authorship-consistent segments; (1.3) the short length of text segments within hybrid texts provides limited stylistic cues for reliable authorship determination; (2) before embarking on the detection process, it is beneficial to assess the average length of segments within the hybrid text. This assessment aids in deciding whether (2.1) to employ a text segmentation-based strategy for hybrid texts with longer segments, or (2.2) to adopt a direct sentence-by-sentence classification strategy for those with shorter segments.
Unveiling the Tapestry of Automated Essay Scoring: A Comprehensive Investigation of Accuracy, Fairness, and Generalizability
Jan 11, 2024



Automatic Essay Scoring (AES) is a well-established educational pursuit that employs machine learning to evaluate student-authored essays. While much effort has been made in this area, current research primarily focuses on either (i) boosting the predictive accuracy of an AES model for a specific prompt (i.e., developing prompt-specific models), which often heavily relies on the use of the labeled data from the same target prompt; or (ii) assessing the applicability of AES models developed on non-target prompts to the intended target prompt (i.e., developing the AES models in a cross-prompt setting). Given the inherent bias in machine learning and its potential impact on marginalized groups, it is imperative to investigate whether such bias exists in current AES methods and, if identified, how it intervenes with an AES model's accuracy and generalizability. Thus, our study aimed to uncover the intricate relationship between an AES model's accuracy, fairness, and generalizability, contributing practical insights for developing effective AES models in real-world education. To this end, we meticulously selected nine prominent AES methods and evaluated their performance using seven metrics on an open-sourced dataset, which contains over 25,000 essays and various demographic information about students such as gender, English language learner status, and economic status. Through extensive evaluations, we demonstrated that: (1) prompt-specific models tend to outperform their cross-prompt counterparts in terms of predictive accuracy; (2) prompt-specific models frequently exhibit a greater bias towards students of different economic statuses compared to cross-prompt models; (3) in the pursuit of generalizability, traditional machine learning models coupled with carefully engineered features hold greater potential for achieving both high accuracy and fairness than complex neural network models.
Towards Automatic Boundary Detection for Human-AI Collaborative Hybrid Essay in Education
Aug 16, 2023



The recent large language models (LLMs), e.g., ChatGPT, have been able to generate human-like and fluent responses when provided with specific instructions. While admitting the convenience brought by technological advancement, educators also have concerns that students might leverage LLMs to complete their writing assignments and pass them off as their original work. Although many AI content detection studies have been conducted as a result of such concerns, most of these prior studies modeled AI content detection as a classification problem, assuming that a text is either entirely human-written or entirely AI-generated. In this study, we investigated AI content detection in a rarely explored yet realistic setting where the text to be detected is collaboratively written by human and generative LLMs (i.e., hybrid text). We first formalized the detection task as identifying the transition points between human-written content and AI-generated content from a given hybrid text (boundary detection). Then we proposed a two-step approach where we (1) separated AI-generated content from human-written content during the encoder training process; and (2) calculated the distances between every two adjacent prototypes and assumed that the boundaries exist between the two adjacent prototypes that have the furthest distance from each other. Through extensive experiments, we observed the following main findings: (1) the proposed approach consistently outperformed the baseline methods across different experiment settings; (2) the encoder training process can significantly boost the performance of the proposed approach; (3) when detecting boundaries for single-boundary hybrid essays, the proposed approach could be enhanced by adopting a relatively large prototype size, leading to a 22% improvement in the In-Domain evaluation and an 18% improvement in the Out-of-Domain evaluation.