 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural-Symbolic Knowledge Tracing: Injecting Educational Knowledge into Deep Learning for Responsible Learner Modelling
Apr 09, 2026The growing use of artificial intelligence (AI) in education, particularly large language models (LLMs), has increased interest in intelligent tutoring systems. However, LLMs often show limited adaptivity and struggle to model learners' evolving knowledge over time, highlighting the need for dedicated learner modelling approaches. Although deep knowledge tracing methods achieve strong predictive performance, their opacity and susceptibility to bias can limit alignment with pedagogical principles. To address this, we propose Responsible-DKT, a neural-symbolic deep knowledge tracing approach that integrates symbolic educational knowledge (e.g., mastery and non-mastery rules) into sequential neural models for responsible learner modelling. Experiments on a real-world dataset of students' math interactions show that Responsible-DKT outperforms both a neural-symbolic baseline and a fully data-driven PyTorch DKT model across training settings. The model achieves over 0.80 AUC with only 10% of training data and up to 0.90 AUC, improving performance by up to 13%. It also demonstrates improved temporal reliability, producing lower early- and mid-sequence prediction errors and the lowest prediction inconsistency rates across sequence lengths, indicating that prediction updates remain directionally aligned with observed student responses over time. Furthermore, the neural-symbolic approach offers intrinsic interpretability via a grounded computation graph that exposes the logic behind each prediction, enabling both local and global explanations. It also allows empirical evaluation of pedagogical assumptions, revealing that repeated incorrect responses (non-mastery) strongly influence prediction updates. These results indicate that neural-symbolic approaches enhance both performance and interpretability, mitigate data limitations, and support more responsible, human-centered AI in education.
Agentivism: a learning theory for the age of artificial intelligence
Apr 09, 2026Learning theories have historically changed when the conditions of learning evolved. Generative and agentic AI create a new condition by allowing learners to delegate explanation, writing, problem solving, and other cognitive work to systems that can generate, recommend, and sometimes act on the learner's behalf. This creates a fundamental challenge for learning theory: successful performance can no longer be assumed to indicate learning. Learners may complete tasks effectively with AI support while developing less understanding, weaker judgment, and limited transferable capability. We argue that this problem is not fully captured by existing learning theories. Behaviourism, cognitivism, constructivism, and connectivism remain important, but they do not directly explain when AI-assisted performance becomes durable human capability. We propose Agentivism, a learning theory for human-AI interaction. Agentivism defines learning as durable growth in human capability through selective delegation to AI, epistemic monitoring and verification of AI contributions, reconstructive internalization of AI-assisted outputs, and transfer under reduced support. The importance of Agentivism lies in explaining how learning remains possible when intelligent delegation is easy and human-AI interaction is becoming a persistent and expanding part of human learning.
Understanding Critical Thinking in Generative Artificial Intelligence Use: Development, Validation, and Correlates of the Critical Thinking in AI Use Scale
Dec 13, 2025Generative AI tools are increasingly embedded in everyday work and learning, yet their fluency, opacity, and propensity to hallucinate mean that users must critically evaluate AI outputs rather than accept them at face value. The present research conceptualises critical thinking in AI use as a dispositional tendency to verify the source and content of AI-generated information, to understand how models work and where they fail, and to reflect on the broader implications of relying on AI. Across six studies (N = 1365), we developed and validated the 13-item critical thinking in AI use scale and mapped its nomological network. Study 1 generated and content-validated scale items. Study 2 supported a three-factor structure (Verification, Motivation, and Reflection). Studies 3, 4, and 5 confirmed this higher-order model, demonstrated internal consistency and test-retest reliability, strong factor loadings, sex invariance, and convergent and discriminant validity. Studies 3 and 4 further revealed that critical thinking in AI use was positively associated with openness, extraversion, positive trait affect, and frequency of AI use. Lastly, Study 6 demonstrated criterion validity of the scale, with higher critical thinking in AI use scores predicting more frequent and diverse verification strategies, greater veracity-judgement accuracy in a novel and naturalistic ChatGPT-powered fact-checking task, and deeper reflection about responsible AI. Taken together, the current work clarifies why and how people exercise oversight over generative AI outputs and provides a validated scale and ecologically grounded task paradigm to support theory testing, cross-group, and longitudinal research on critical engagement with generative AI outputs.
Does the Prompt-based Large Language Model Recognize Students' Demographics and Introduce Bias in Essay Scoring?
Apr 30, 2025Large Language Models (LLMs) are widely used in Automated Essay Scoring (AES) due to their ability to capture semantic meaning. Traditional fine-tuning approaches required technical expertise, limiting accessibility for educators with limited technical backgrounds. However, prompt-based tools like ChatGPT have made AES more accessible, enabling educators to obtain machine-generated scores using natural-language prompts (i.e., the prompt-based paradigm). Despite advancements, prior studies have shown bias in fine-tuned LLMs, particularly against disadvantaged groups. It remains unclear whether such biases persist or are amplified in the prompt-based paradigm with cutting-edge tools. Since such biases are believed to stem from the demographic information embedded in pre-trained models (i.e., the ability of LLMs' text embeddings to predict demographic attributes), this study explores the relationship between the model's predictive power of students' demographic attributes based on their written works and its predictive bias in the scoring task in the prompt-based paradigm. Using a publicly available dataset of over 25,000 students' argumentative essays, we designed prompts to elicit demographic inferences (i.e., gender, first-language background) from GPT-4o and assessed fairness in automated scoring. Then we conducted multivariate regression analysis to explore the impact of the model's ability to predict demographics on its scoring outcomes. Our findings revealed that (i) prompt-based LLMs can somewhat infer students' demographics, particularly their first-language backgrounds, from their essays; (ii) scoring biases are more pronounced when the LLM correctly predicts students' first-language background than when it does not; and (iii) scoring error for non-native English speakers increases when the LLM correctly identifies them as non-native.
Towards responsible AI for education: Hybrid human-AI to confront the Elephant in the room
Apr 22, 2025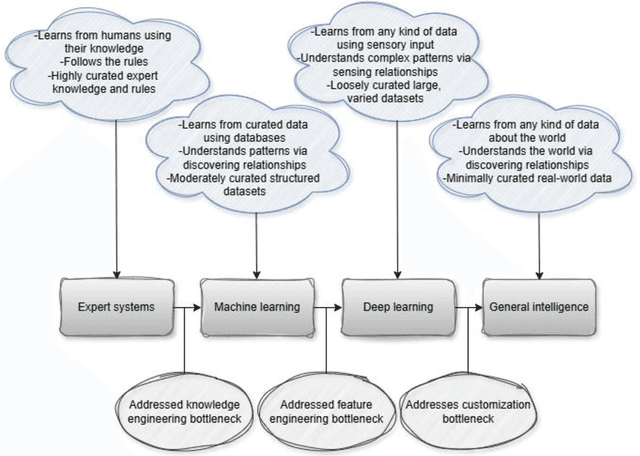
Despite significant advancements in AI-driven educational systems and ongoing calls for responsible AI for education, several critical issues remain unresolved -- acting as the elephant in the room within AI in education, learning analytics, educational data mining, learning sciences, and educational psychology communities. This critical analysis identifies and examines nine persistent challenges that continue to undermine the fairness, transparency, and effectiveness of current AI methods and applications in education. These include: (1) the lack of clarity around what AI for education truly means -- often ignoring the distinct purposes, strengths, and limitations of different AI families -- and the trend of equating it with domain-agnostic, company-driven large language models; (2) the widespread neglect of essential learning processes such as motivation, emotion, and (meta)cognition in AI-driven learner modelling and their contextual nature; (3) limited integration of domain knowledge and lack of stakeholder involvement in AI design and development; (4) continued use of non-sequential machine learning models on temporal educational data; (5) misuse of non-sequential metrics to evaluate sequential models; (6) use of unreliable explainable AI methods to provide explanations for black-box models; (7) ignoring ethical guidelines in addressing data inconsistencies during model training; (8) use of mainstream AI methods for pattern discovery and learning analytics without systematic benchmarking; and (9) overemphasis on global prescriptions while overlooking localised, student-specific recommendations. Supported by theoretical and empirical research, we demonstrate how hybrid AI methods -- specifically neural-symbolic AI -- can address the elephant in the room and serve as the foundation for responsible, trustworthy AI systems in education.
Beware of Metacognitive Laziness: Effects of Generative Artificial Intelligence on Learning Motivation, Processes, and Performance
Dec 12, 2024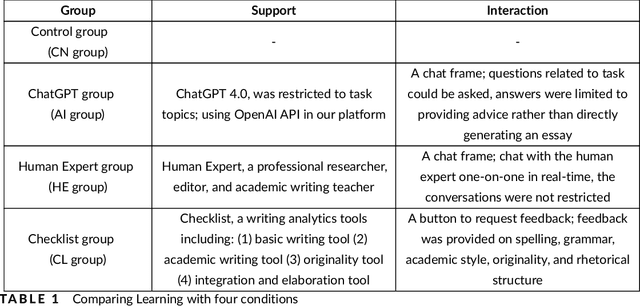
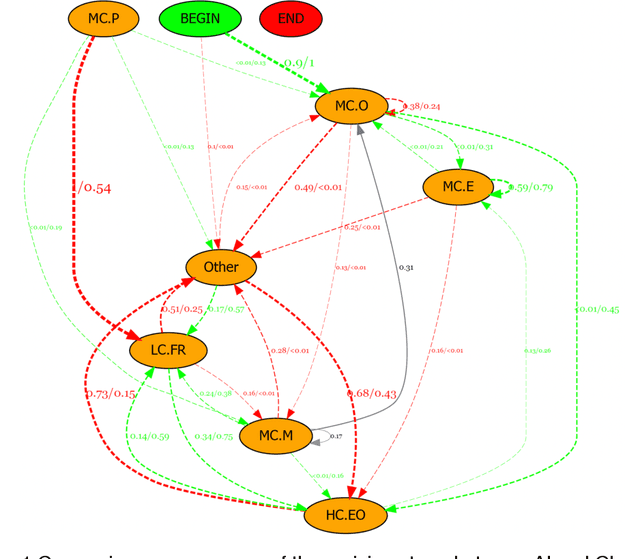
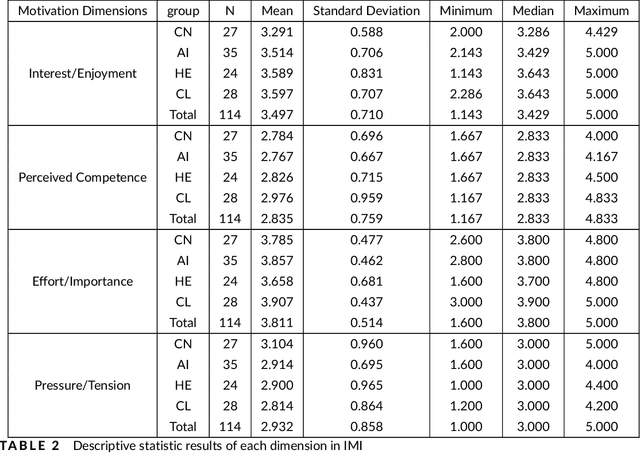
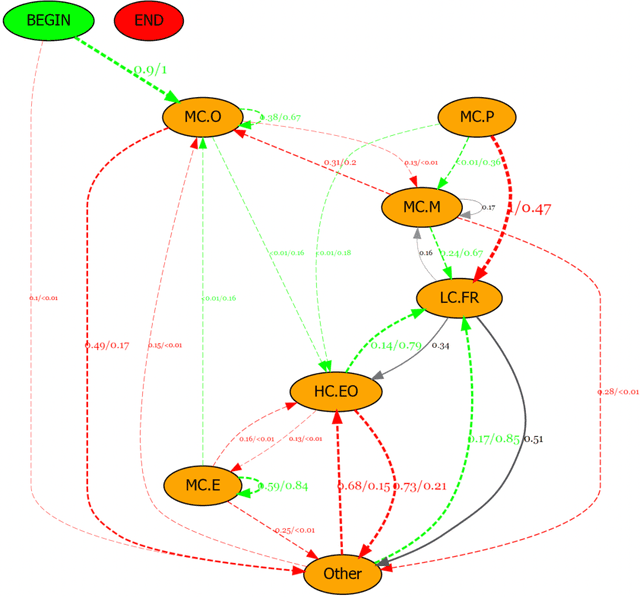
With the continuous development of technological and educational innovation, learners nowadays can obtain a variety of support from agents such as teachers, peers, education technologies, and recently, generative artificial intelligence such as ChatGPT. The concept of hybrid intelligence is still at a nascent stage, and how learners can benefit from a symbiotic relationship with various agents such as AI, human experts and intelligent learning systems is still unknown. The emerging concept of hybrid intelligence also lacks deep insights and understanding of the mechanisms and consequences of hybrid human-AI learning based on strong empirical research. In order to address this gap, we conducted a randomised experimental study and compared learners' motivations, self-regulated learning processes and learning performances on a writing task among different groups who had support from different agents (ChatGPT, human expert, writing analytics tools, and no extra tool). A total of 117 university students were recruited, and their multi-channel learning, performance and motivation data were collected and analysed. The results revealed that: learners who received different learning support showed no difference in post-task intrinsic motivation; there were significant differences in the frequency and sequences of the self-regulated learning processes among groups; ChatGPT group outperformed in the essay score improvement but their knowledge gain and transfer were not significantly different. Our research found that in the absence of differences in motivation, learners with different supports still exhibited different self-regulated learning processes, ultimately leading to differentiated performance. What is particularly noteworthy is that AI technologies such as ChatGPT may promote learners' dependence on technology and potentially trigger metacognitive laziness.
Modifying AI, Enhancing Essays: How Active Engagement with Generative AI Boosts Writing Quality
Dec 10, 2024Students are increasingly relying on Generative AI (GAI) to support their writing-a key pedagogical practice in education. In GAI-assisted writing, students can delegate core cognitive tasks (e.g., generating ideas and turning them into sentences) to GAI while still producing high-quality essays. This creates new challenges for teachers in assessing and supporting student learning, as they often lack insight into whether students are engaging in meaningful cognitive processes during writing or how much of the essay's quality can be attributed to those processes. This study aimed to help teachers better assess and support student learning in GAI-assisted writing by examining how different writing behaviors, especially those indicative of meaningful learning versus those that are not, impact essay quality. Using a dataset of 1,445 GAI-assisted writing sessions, we applied the cutting-edge method, X-Learner, to quantify the causal impact of three GAI-assisted writing behavioral patterns (i.e., seeking suggestions but not accepting them, seeking suggestions and accepting them as they are, and seeking suggestions and accepting them with modification) on four measures of essay quality (i.e., lexical sophistication, syntactic complexity, text cohesion, and linguistic bias). Our analysis showed that writers who frequently modified GAI-generated text-suggesting active engagement in higher-order cognitive processes-consistently improved the quality of their essays in terms of lexical sophistication, syntactic complexity, and text cohesion. In contrast, those who often accepted GAI-generated text without changes, primarily engaging in lower-order processes, saw a decrease in essay quality. Additionally, while human writers tend to introduce linguistic bias when writing independently, incorporating GAI-generated text-even without modification-can help mitigate this bias.
From Complexity to Parsimony: Integrating Latent Class Analysis to Uncover Multimodal Learning Patterns in Collaborative Learning
Nov 23, 2024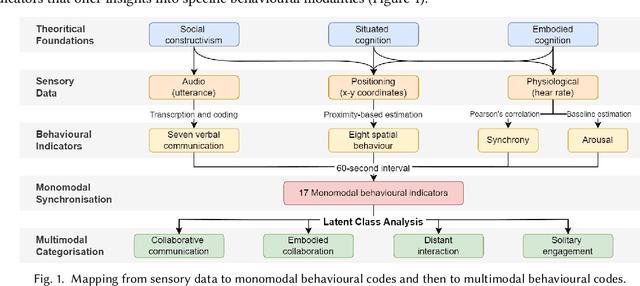
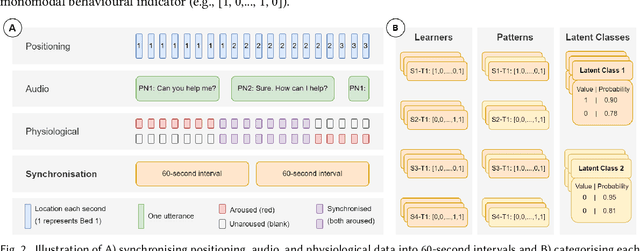
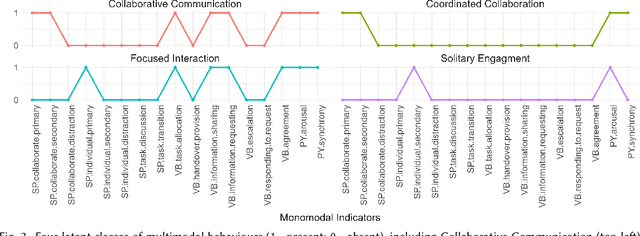

Multimodal Learning Analytics (MMLA) leverages advanced sensing technologies and artificial intelligence to capture complex learning processes, but integrating diverse data sources into cohesive insights remains challenging. This study introduces a novel methodology for integrating latent class analysis (LCA) within MMLA to map monomodal behavioural indicators into parsimonious multimodal ones. Using a high-fidelity healthcare simulation context, we collected positional, audio, and physiological data, deriving 17 monomodal indicators. LCA identified four distinct latent classes: Collaborative Communication, Embodied Collaboration, Distant Interaction, and Solitary Engagement, each capturing unique monomodal patterns. Epistemic network analysis compared these multimodal indicators with the original monomodal indicators and found that the multimodal approach was more parsimonious while offering higher explanatory power regarding students' task and collaboration performances. The findings highlight the potential of LCA in simplifying the analysis of complex multimodal data while capturing nuanced, cross-modality behaviours, offering actionable insights for educators and enhancing the design of collaborative learning interventions. This study proposes a pathway for advancing MMLA, making it more parsimonious and manageable, and aligning with the principles of learner-centred education.
Generative AI in Higher Education: A Global Perspective of Institutional Adoption Policies and Guidelines
May 20, 2024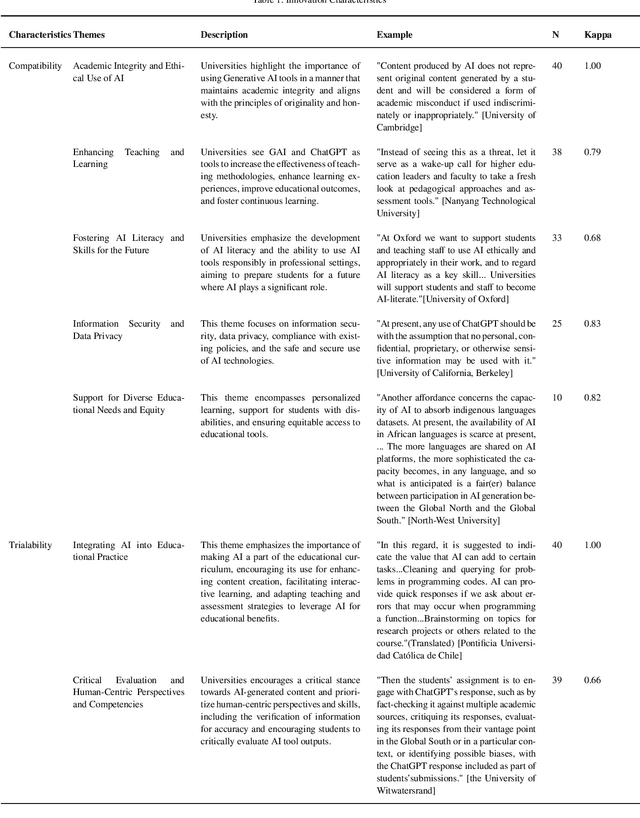
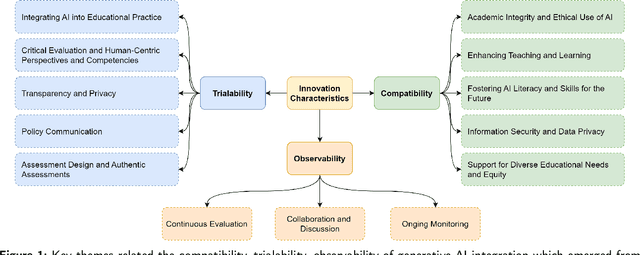

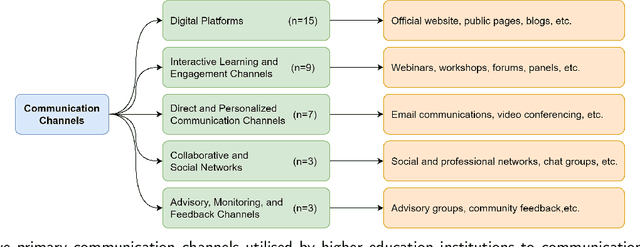
Integrating generative AI (GAI) into higher education is crucial for preparing a future generation of GAI-literate students. Yet a thorough understanding of the global institutional adoption policy remains absent, with most of the prior studies focused on the Global North and the promises and challenges of GAI, lacking a theoretical lens. This study utilizes the Diffusion of Innovations Theory to examine GAI adoption strategies in higher education across 40 universities from six global regions. It explores the characteristics of GAI innovation, including compatibility, trialability, and observability, and analyses the communication channels and roles and responsibilities outlined in university policies and guidelines. The findings reveal a proactive approach by universities towards GAI integration, emphasizing academic integrity, teaching and learning enhancement, and equity. Despite a cautious yet optimistic stance, a comprehensive policy framework is needed to evaluate the impacts of GAI integration and establish effective communication strategies that foster broader stakeholder engagement. The study highlights the importance of clear roles and responsibilities among faculty, students, and administrators for successful GAI integration, supporting a collaborative model for navigating the complexities of GAI in education. This study contributes insights for policymakers in crafting detailed strategies for its integration.
Towards Detecting AI-Generated Text within Human-AI Collaborative Hybrid Texts
Mar 06, 2024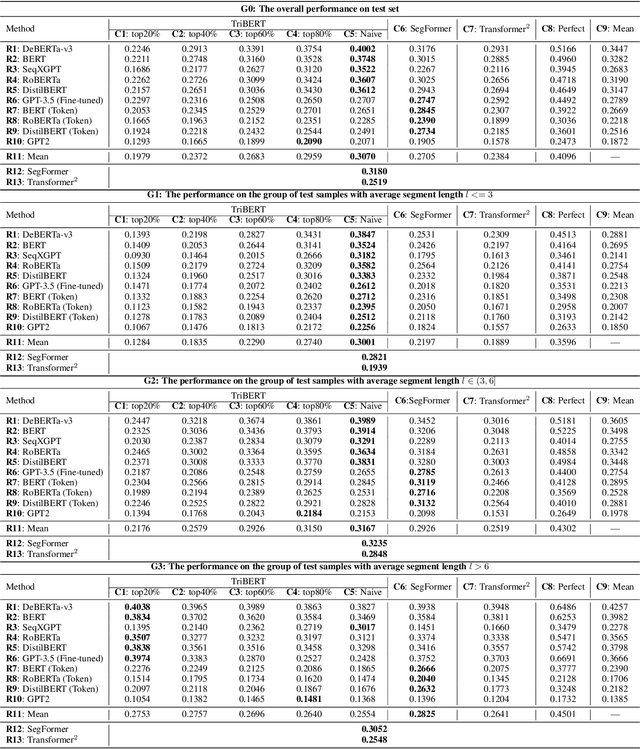
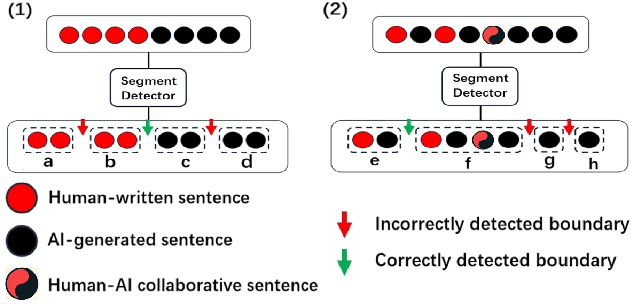
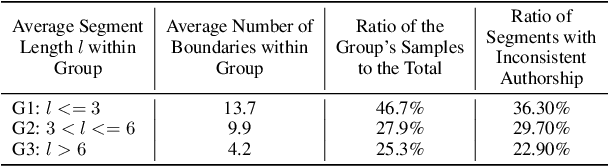
This study explores the challenge of sentence-level AI-generated text detection within human-AI collaborative hybrid texts. Existing studies of AI-generated text detection for hybrid texts often rely on synthetic datasets. These typically involve hybrid texts with a limited number of boundaries. We contend that studies of detecting AI-generated content within hybrid texts should cover different types of hybrid texts generated in realistic settings to better inform real-world applications. Therefore, our study utilizes the CoAuthor dataset, which includes diverse, realistic hybrid texts generated through the collaboration between human writers and an intelligent writing system in multi-turn interactions. We adopt a two-step, segmentation-based pipeline: (i) detect segments within a given hybrid text where each segment contains sentences of consistent authorship, and (ii) classify the authorship of each identified segment. Our empirical findings highlight (1) detecting AI-generated sentences in hybrid texts is overall a challenging task because (1.1) human writers' selecting and even editing AI-generated sentences based on personal preferences adds difficulty in identifying the authorship of segments; (1.2) the frequent change of authorship between neighboring sentences within the hybrid text creates difficulties for segment detectors in identifying authorship-consistent segments; (1.3) the short length of text segments within hybrid texts provides limited stylistic cues for reliable authorship determination; (2) before embarking on the detection process, it is beneficial to assess the average length of segments within the hybrid text. This assessment aids in deciding whether (2.1) to employ a text segmentation-based strategy for hybrid texts with longer segments, or (2.2) to adopt a direct sentence-by-sentence classification strategy for those with shorter segments.