 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Encoders for Modular Relational Deep Learning
Jun 19, 2026Relational Deep Learning (RDL) models multi-tabular databases as temporal heterogeneous graphs for end-to-end representation learning. While RDL is evolving rapidly, existing approaches face significant generalization obstacles. They are either schema-specific, requiring training from scratch for every new database, or they rely on monolithic architectures that entangle feature encoding with graph message-passing. Analyzing these limitations, we establish four core pillars for building foundational relational models: semantic granularity, structural topology, temporal causality, and unified optimization. Addressing these pillars, we propose a modular approach that decouples row encoding from graph message-passing. We introduce the Universal Row Encoder, a transformer-based module that integrates raw cell data with schema metadata$-$including column semantics, table names, and global distribution statistics$-$to produce table-width invariant row embeddings. By explicitly feeding global statistics to an intra-row self-attention mechanism, the encoder natively contextualizes unseen features and handles sparse data. Serving as a flexible "backend" for any downstream graph architecture, our pretrained encoder enhances cross-database knowledge transfer on the established RelBench benchmarks while improving learning convergence and memory footprint.
Neural-Symbolic Knowledge Tracing: Injecting Educational Knowledge into Deep Learning for Responsible Learner Modelling
Apr 09, 2026The growing use of artificial intelligence (AI) in education, particularly large language models (LLMs), has increased interest in intelligent tutoring systems. However, LLMs often show limited adaptivity and struggle to model learners' evolving knowledge over time, highlighting the need for dedicated learner modelling approaches. Although deep knowledge tracing methods achieve strong predictive performance, their opacity and susceptibility to bias can limit alignment with pedagogical principles. To address this, we propose Responsible-DKT, a neural-symbolic deep knowledge tracing approach that integrates symbolic educational knowledge (e.g., mastery and non-mastery rules) into sequential neural models for responsible learner modelling. Experiments on a real-world dataset of students' math interactions show that Responsible-DKT outperforms both a neural-symbolic baseline and a fully data-driven PyTorch DKT model across training settings. The model achieves over 0.80 AUC with only 10% of training data and up to 0.90 AUC, improving performance by up to 13%. It also demonstrates improved temporal reliability, producing lower early- and mid-sequence prediction errors and the lowest prediction inconsistency rates across sequence lengths, indicating that prediction updates remain directionally aligned with observed student responses over time. Furthermore, the neural-symbolic approach offers intrinsic interpretability via a grounded computation graph that exposes the logic behind each prediction, enabling both local and global explanations. It also allows empirical evaluation of pedagogical assumptions, revealing that repeated incorrect responses (non-mastery) strongly influence prediction updates. These results indicate that neural-symbolic approaches enhance both performance and interpretability, mitigate data limitations, and support more responsible, human-centered AI in education.
Towards responsible AI for education: Hybrid human-AI to confront the Elephant in the room
Apr 22, 2025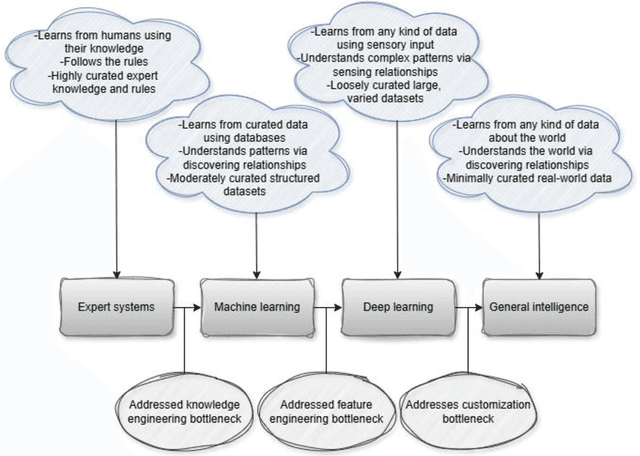
Despite significant advancements in AI-driven educational systems and ongoing calls for responsible AI for education, several critical issues remain unresolved -- acting as the elephant in the room within AI in education, learning analytics, educational data mining, learning sciences, and educational psychology communities. This critical analysis identifies and examines nine persistent challenges that continue to undermine the fairness, transparency, and effectiveness of current AI methods and applications in education. These include: (1) the lack of clarity around what AI for education truly means -- often ignoring the distinct purposes, strengths, and limitations of different AI families -- and the trend of equating it with domain-agnostic, company-driven large language models; (2) the widespread neglect of essential learning processes such as motivation, emotion, and (meta)cognition in AI-driven learner modelling and their contextual nature; (3) limited integration of domain knowledge and lack of stakeholder involvement in AI design and development; (4) continued use of non-sequential machine learning models on temporal educational data; (5) misuse of non-sequential metrics to evaluate sequential models; (6) use of unreliable explainable AI methods to provide explanations for black-box models; (7) ignoring ethical guidelines in addressing data inconsistencies during model training; (8) use of mainstream AI methods for pattern discovery and learning analytics without systematic benchmarking; and (9) overemphasis on global prescriptions while overlooking localised, student-specific recommendations. Supported by theoretical and empirical research, we demonstrate how hybrid AI methods -- specifically neural-symbolic AI -- can address the elephant in the room and serve as the foundation for responsible, trustworthy AI systems in education.
Towards Responsible and Trustworthy Educational Data Mining: Comparing Symbolic, Sub-Symbolic, and Neural-Symbolic AI Methods
Apr 01, 2025Given the demand for responsible and trustworthy AI for education, this study evaluates symbolic, sub-symbolic, and neural-symbolic AI (NSAI) in terms of generalizability and interpretability. Our extensive experiments on balanced and imbalanced self-regulated learning datasets of Estonian primary school students predicting 7th-grade mathematics national test performance showed that symbolic and sub-symbolic methods performed well on balanced data but struggled to identify low performers in imbalanced datasets. Interestingly, symbolic and sub-symbolic methods emphasized different factors in their decision-making: symbolic approaches primarily relied on cognitive and motivational factors, while sub-symbolic methods focused more on cognitive aspects, learned knowledge, and the demographic variable of gender -- yet both largely overlooked metacognitive factors. The NSAI method, on the other hand, showed advantages by: (i) being more generalizable across both classes -- even in imbalanced datasets -- as its symbolic knowledge component compensated for the underrepresented class; and (ii) relying on a more integrated set of factors in its decision-making, including motivation, (meta)cognition, and learned knowledge, thus offering a comprehensive and theoretically grounded interpretability framework. These contrasting findings highlight the need for a holistic comparison of AI methods before drawing conclusions based solely on predictive performance. They also underscore the potential of hybrid, human-centered NSAI methods to address the limitations of other AI families and move us closer to responsible AI for education. Specifically, by enabling stakeholders to contribute to AI design, NSAI aligns learned patterns with theoretical constructs, incorporates factors like motivation and metacognition, and strengthens the trustworthiness and responsibility of educational data mining.
Transformers Meet Relational Databases
Dec 06, 2024Transformer models have continuously expanded into all machine learning domains convertible to the underlying sequence-to-sequence representation, including tabular data. However, while ubiquitous, this representation restricts their extension to the more general case of relational databases. In this paper, we introduce a modular neural message-passing scheme that closely adheres to the formal relational model, enabling direct end-to-end learning of tabular Transformers from database storage systems. We address the challenges of appropriate learning data representation and loading, which are critical in the database setting, and compare our approach against a number of representative models from various related fields across a significantly wide range of datasets. Our results demonstrate a superior performance of this newly proposed class of neural architectures.
Deep Learning for Generalised Planning with Background Knowledge
Oct 10, 2024
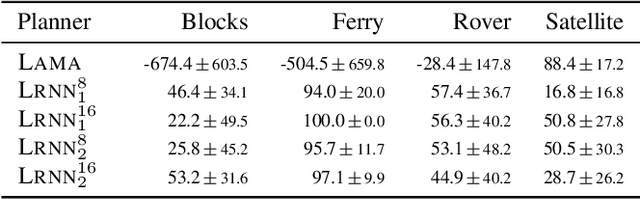


Automated planning is a form of declarative problem solving which has recently drawn attention from the machine learning (ML) community. ML has been applied to planning either as a way to test `reasoning capabilities' of architectures, or more pragmatically in an attempt to scale up solvers with learned domain knowledge. In practice, planning problems are easy to solve but hard to optimise. However, ML approaches still struggle to solve many problems that are often easy for both humans and classical planners. In this paper, we thus propose a new ML approach that allows users to specify background knowledge (BK) through Datalog rules to guide both the learning and planning processes in an integrated fashion. By incorporating BK, our approach bypasses the need to relearn how to solve problems from scratch and instead focuses the learning on plan quality optimisation. Experiments with BK demonstrate that our method successfully scales and learns to plan efficiently with high quality solutions from small training data generated in under 5 seconds.
Beating the market with a bad predictive model
Oct 23, 2020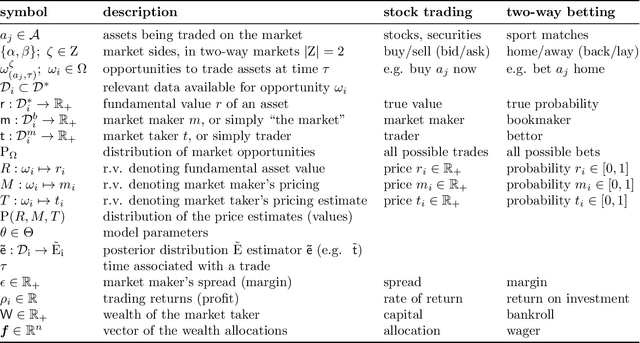



It is a common misconception that in order to make consistent profits as a trader, one needs to posses some extra information leading to an asset value estimation more accurate than that reflected by the current market price. While the idea makes intuitive sense and is also well substantiated by the widely popular Kelly criterion, we prove that it is generally possible to make systematic profits with a completely inferior price-predicting model. The key idea is to alter the training objective of the predictive models to explicitly decorrelate them from the market, enabling to exploit inconspicuous biases in market maker's pricing, and profit on the inherent advantage of the market taker. We introduce the problem setting throughout the diverse domains of stock trading and sports betting to provide insights into the common underlying properties of profitable predictive models, their connections to standard portfolio optimization strategies, and the, commonly overlooked, advantage of the market taker. Consequently, we prove desirability of the decorrelation objective across common market distributions, translate the concept into a practical machine learning setting, and demonstrate its viability with real world market data.