 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural-Symbolic Knowledge Tracing: Injecting Educational Knowledge into Deep Learning for Responsible Learner Modelling
Apr 09, 2026The growing use of artificial intelligence (AI) in education, particularly large language models (LLMs), has increased interest in intelligent tutoring systems. However, LLMs often show limited adaptivity and struggle to model learners' evolving knowledge over time, highlighting the need for dedicated learner modelling approaches. Although deep knowledge tracing methods achieve strong predictive performance, their opacity and susceptibility to bias can limit alignment with pedagogical principles. To address this, we propose Responsible-DKT, a neural-symbolic deep knowledge tracing approach that integrates symbolic educational knowledge (e.g., mastery and non-mastery rules) into sequential neural models for responsible learner modelling. Experiments on a real-world dataset of students' math interactions show that Responsible-DKT outperforms both a neural-symbolic baseline and a fully data-driven PyTorch DKT model across training settings. The model achieves over 0.80 AUC with only 10% of training data and up to 0.90 AUC, improving performance by up to 13%. It also demonstrates improved temporal reliability, producing lower early- and mid-sequence prediction errors and the lowest prediction inconsistency rates across sequence lengths, indicating that prediction updates remain directionally aligned with observed student responses over time. Furthermore, the neural-symbolic approach offers intrinsic interpretability via a grounded computation graph that exposes the logic behind each prediction, enabling both local and global explanations. It also allows empirical evaluation of pedagogical assumptions, revealing that repeated incorrect responses (non-mastery) strongly influence prediction updates. These results indicate that neural-symbolic approaches enhance both performance and interpretability, mitigate data limitations, and support more responsible, human-centered AI in education.
Problems With Large Language Models for Learner Modelling: Why LLMs Alone Fall Short for Responsible Tutoring in K--12 Education
Dec 28, 2025The rapid rise of large language model (LLM)-based tutors in K--12 education has fostered a misconception that generative models can replace traditional learner modelling for adaptive instruction. This is especially problematic in K--12 settings, which the EU AI Act classifies as high-risk domain requiring responsible design. Motivated by these concerns, this study synthesises evidence on limitations of LLM-based tutors and empirically investigates one critical issue: the accuracy, reliability, and temporal coherence of assessing learners' evolving knowledge over time. We compare a deep knowledge tracing (DKT) model with a widely used LLM, evaluated zero-shot and fine-tuned, using a large open-access dataset. Results show that DKT achieves the highest discrimination performance (AUC = 0.83) on next-step correctness prediction and consistently outperforms the LLM across settings. Although fine-tuning improves the LLM's AUC by approximately 8\% over the zero-shot baseline, it remains 6\% below DKT and produces higher early-sequence errors, where incorrect predictions are most harmful for adaptive support. Temporal analyses further reveal that DKT maintains stable, directionally correct mastery updates, whereas LLM variants exhibit substantial temporal weaknesses, including inconsistent and wrong-direction updates. These limitations persist despite the fine-tuned LLM requiring nearly 198 hours of high-compute training, far exceeding the computational demands of DKT. Our qualitative analysis of multi-skill mastery estimation further shows that, even after fine-tuning, the LLM produced inconsistent mastery trajectories, while DKT maintained smooth and coherent updates. Overall, the findings suggest that LLMs alone are unlikely to match the effectiveness of established intelligent tutoring systems, and that responsible tutoring requires hybrid frameworks that incorporate learner modelling.
Towards responsible AI for education: Hybrid human-AI to confront the Elephant in the room
Apr 22, 2025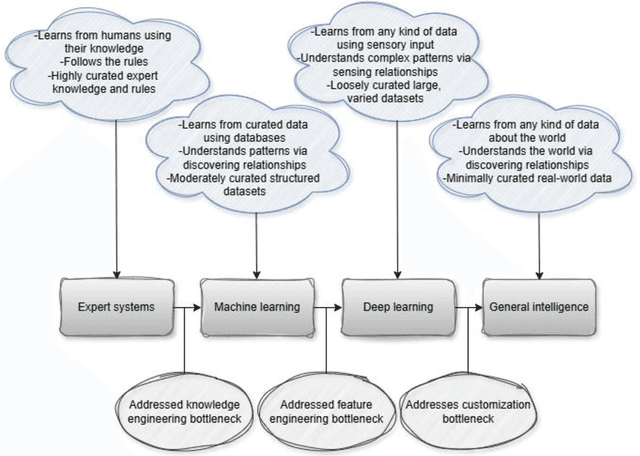
Despite significant advancements in AI-driven educational systems and ongoing calls for responsible AI for education, several critical issues remain unresolved -- acting as the elephant in the room within AI in education, learning analytics, educational data mining, learning sciences, and educational psychology communities. This critical analysis identifies and examines nine persistent challenges that continue to undermine the fairness, transparency, and effectiveness of current AI methods and applications in education. These include: (1) the lack of clarity around what AI for education truly means -- often ignoring the distinct purposes, strengths, and limitations of different AI families -- and the trend of equating it with domain-agnostic, company-driven large language models; (2) the widespread neglect of essential learning processes such as motivation, emotion, and (meta)cognition in AI-driven learner modelling and their contextual nature; (3) limited integration of domain knowledge and lack of stakeholder involvement in AI design and development; (4) continued use of non-sequential machine learning models on temporal educational data; (5) misuse of non-sequential metrics to evaluate sequential models; (6) use of unreliable explainable AI methods to provide explanations for black-box models; (7) ignoring ethical guidelines in addressing data inconsistencies during model training; (8) use of mainstream AI methods for pattern discovery and learning analytics without systematic benchmarking; and (9) overemphasis on global prescriptions while overlooking localised, student-specific recommendations. Supported by theoretical and empirical research, we demonstrate how hybrid AI methods -- specifically neural-symbolic AI -- can address the elephant in the room and serve as the foundation for responsible, trustworthy AI systems in education.
Towards Responsible and Trustworthy Educational Data Mining: Comparing Symbolic, Sub-Symbolic, and Neural-Symbolic AI Methods
Apr 01, 2025Given the demand for responsible and trustworthy AI for education, this study evaluates symbolic, sub-symbolic, and neural-symbolic AI (NSAI) in terms of generalizability and interpretability. Our extensive experiments on balanced and imbalanced self-regulated learning datasets of Estonian primary school students predicting 7th-grade mathematics national test performance showed that symbolic and sub-symbolic methods performed well on balanced data but struggled to identify low performers in imbalanced datasets. Interestingly, symbolic and sub-symbolic methods emphasized different factors in their decision-making: symbolic approaches primarily relied on cognitive and motivational factors, while sub-symbolic methods focused more on cognitive aspects, learned knowledge, and the demographic variable of gender -- yet both largely overlooked metacognitive factors. The NSAI method, on the other hand, showed advantages by: (i) being more generalizable across both classes -- even in imbalanced datasets -- as its symbolic knowledge component compensated for the underrepresented class; and (ii) relying on a more integrated set of factors in its decision-making, including motivation, (meta)cognition, and learned knowledge, thus offering a comprehensive and theoretically grounded interpretability framework. These contrasting findings highlight the need for a holistic comparison of AI methods before drawing conclusions based solely on predictive performance. They also underscore the potential of hybrid, human-centered NSAI methods to address the limitations of other AI families and move us closer to responsible AI for education. Specifically, by enabling stakeholders to contribute to AI design, NSAI aligns learned patterns with theoretical constructs, incorporates factors like motivation and metacognition, and strengthens the trustworthiness and responsibility of educational data mining.
Beyond Text-to-Text: An Overview of Multimodal and Generative Artificial Intelligence for Education Using Topic Modeling
Sep 24, 2024



Generative artificial intelligence (GenAI) can reshape education and learning. While large language models (LLMs) like ChatGPT dominate current educational research, multimodal capabilities, such as text-to-speech and text-to-image, are less explored. This study uses topic modeling to map the research landscape of multimodal and generative AI in education. An extensive literature search using Dimensions.ai yielded 4175 articles. Employing a topic modeling approach, latent topics were extracted, resulting in 38 interpretable topics organized into 14 thematic areas. Findings indicate a predominant focus on text-to-text models in educational contexts, with other modalities underexplored, overlooking the broader potential of multimodal approaches. The results suggest a research gap, stressing the importance of more balanced attention across different AI modalities and educational levels. In summary, this research provides an overview of current trends in generative AI for education, underlining opportunities for future exploration of multimodal technologies to fully realize the transformative potential of artificial intelligence in education.
Toward Scalable and Transparent Multimodal Analytics to Study Standard Medical Procedures: Linking Hand Movement, Proximity, and Gaze Data
Dec 08, 2023



This study employed multimodal learning analytics (MMLA) to analyze behavioral dynamics during the ABCDE procedure in nursing education, focusing on gaze entropy, hand movement velocities, and proximity measures. Utilizing accelerometers and eye-tracking techniques, behaviorgrams were generated to depict various procedural phases. Results identified four primary phases characterized by distinct patterns of visual attention, hand movements, and proximity to the patient or instruments. The findings suggest that MMLA can offer valuable insights into procedural competence in medical education. This research underscores the potential of MMLA to provide detailed, objective evaluations of clinical procedures and their inherent complexities.