 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural-Symbolic Knowledge Tracing: Injecting Educational Knowledge into Deep Learning for Responsible Learner Modelling
Apr 09, 2026The growing use of artificial intelligence (AI) in education, particularly large language models (LLMs), has increased interest in intelligent tutoring systems. However, LLMs often show limited adaptivity and struggle to model learners' evolving knowledge over time, highlighting the need for dedicated learner modelling approaches. Although deep knowledge tracing methods achieve strong predictive performance, their opacity and susceptibility to bias can limit alignment with pedagogical principles. To address this, we propose Responsible-DKT, a neural-symbolic deep knowledge tracing approach that integrates symbolic educational knowledge (e.g., mastery and non-mastery rules) into sequential neural models for responsible learner modelling. Experiments on a real-world dataset of students' math interactions show that Responsible-DKT outperforms both a neural-symbolic baseline and a fully data-driven PyTorch DKT model across training settings. The model achieves over 0.80 AUC with only 10% of training data and up to 0.90 AUC, improving performance by up to 13%. It also demonstrates improved temporal reliability, producing lower early- and mid-sequence prediction errors and the lowest prediction inconsistency rates across sequence lengths, indicating that prediction updates remain directionally aligned with observed student responses over time. Furthermore, the neural-symbolic approach offers intrinsic interpretability via a grounded computation graph that exposes the logic behind each prediction, enabling both local and global explanations. It also allows empirical evaluation of pedagogical assumptions, revealing that repeated incorrect responses (non-mastery) strongly influence prediction updates. These results indicate that neural-symbolic approaches enhance both performance and interpretability, mitigate data limitations, and support more responsible, human-centered AI in education.
Representation Finetuning for Continual Learning
Mar 11, 2026The world is inherently dynamic, and continual learning aims to enable models to adapt to ever-evolving data streams. While pre-trained models have shown powerful performance in continual learning, they still require finetuning to adapt effectively to downstream tasks. However, prevailing Parameter-Efficient Fine-Tuning (PEFT) methods operate through empirical, black-box optimization at the weight level. These approaches lack explicit control over representation drift, leading to sensitivity to domain shifts and catastrophic forgetting in continual learning scenarios. In this work, we introduce Continual Representation Learning (CoRe), a novel framework that for the first time shifts the finetuning paradigm from weight space to representation space. Unlike conventional methods, CoRe performs task-specific interventions within a low-rank linear subspace of hidden representations, adopting a learning process with explicit objectives, which ensures stability for past tasks while maintaining plasticity for new ones. By constraining updates to a low-rank subspace, CoRe achieves exceptional parameter efficiency. Extensive experiments across multiple continual learning benchmarks demonstrate that CoRe not only preserves parameter efficiency but also significantly outperforms existing state-of-the-art methods. Our work introduces representation finetuning as a new, more effective and interpretable paradigm for continual learning.
Reversible Lifelong Model Editing via Semantic Routing-Based LoRA
Mar 11, 2026The dynamic evolution of real-world necessitates model editing within Large Language Models. While existing methods explore modular isolation or parameter-efficient strategies, they still suffer from semantic drift or knowledge forgetting due to continual updating. To address these challenges, we propose SoLA, a Semantic routing-based LoRA framework for lifelong model editing. In SoLA, each edit is encapsulated as an independent LoRA module, which is frozen after training and mapped to input by semantic routing, allowing dynamic activation of LoRA modules via semantic matching. This mechanism avoids semantic drift caused by cluster updating and mitigates catastrophic forgetting from parameter sharing. More importantly, SoLA supports precise revocation of specific edits by removing key from semantic routing, which restores model's original behavior. To our knowledge, this reversible rollback editing capability is the first to be achieved in existing literature. Furthermore, SoLA integrates decision-making process into edited layer, eliminating the need for auxiliary routing networks and enabling end-to-end decision-making process. Extensive experiments demonstrate that SoLA effectively learns and retains edited knowledge, achieving accurate, efficient, and reversible lifelong model editing.
Key-Value Pair-Free Continual Learner via Task-Specific Prompt-Prototype
Jan 08, 2026Continual learning aims to enable models to acquire new knowledge while retaining previously learned information. Prompt-based methods have shown remarkable performance in this domain; however, they typically rely on key-value pairing, which can introduce inter-task interference and hinder scalability. To overcome these limitations, we propose a novel approach employing task-specific Prompt-Prototype (ProP), thereby eliminating the need for key-value pairs. In our method, task-specific prompts facilitate more effective feature learning for the current task, while corresponding prototypes capture the representative features of the input. During inference, predictions are generated by binding each task-specific prompt with its associated prototype. Additionally, we introduce regularization constraints during prompt initialization to penalize excessively large values, thereby enhancing stability. Experiments on several widely used datasets demonstrate the effectiveness of the proposed method. In contrast to mainstream prompt-based approaches, our framework removes the dependency on key-value pairs, offering a fresh perspective for future continual learning research.
Problems With Large Language Models for Learner Modelling: Why LLMs Alone Fall Short for Responsible Tutoring in K--12 Education
Dec 28, 2025The rapid rise of large language model (LLM)-based tutors in K--12 education has fostered a misconception that generative models can replace traditional learner modelling for adaptive instruction. This is especially problematic in K--12 settings, which the EU AI Act classifies as high-risk domain requiring responsible design. Motivated by these concerns, this study synthesises evidence on limitations of LLM-based tutors and empirically investigates one critical issue: the accuracy, reliability, and temporal coherence of assessing learners' evolving knowledge over time. We compare a deep knowledge tracing (DKT) model with a widely used LLM, evaluated zero-shot and fine-tuned, using a large open-access dataset. Results show that DKT achieves the highest discrimination performance (AUC = 0.83) on next-step correctness prediction and consistently outperforms the LLM across settings. Although fine-tuning improves the LLM's AUC by approximately 8\% over the zero-shot baseline, it remains 6\% below DKT and produces higher early-sequence errors, where incorrect predictions are most harmful for adaptive support. Temporal analyses further reveal that DKT maintains stable, directionally correct mastery updates, whereas LLM variants exhibit substantial temporal weaknesses, including inconsistent and wrong-direction updates. These limitations persist despite the fine-tuned LLM requiring nearly 198 hours of high-compute training, far exceeding the computational demands of DKT. Our qualitative analysis of multi-skill mastery estimation further shows that, even after fine-tuning, the LLM produced inconsistent mastery trajectories, while DKT maintained smooth and coherent updates. Overall, the findings suggest that LLMs alone are unlikely to match the effectiveness of established intelligent tutoring systems, and that responsible tutoring requires hybrid frameworks that incorporate learner modelling.
Towards responsible AI for education: Hybrid human-AI to confront the Elephant in the room
Apr 22, 2025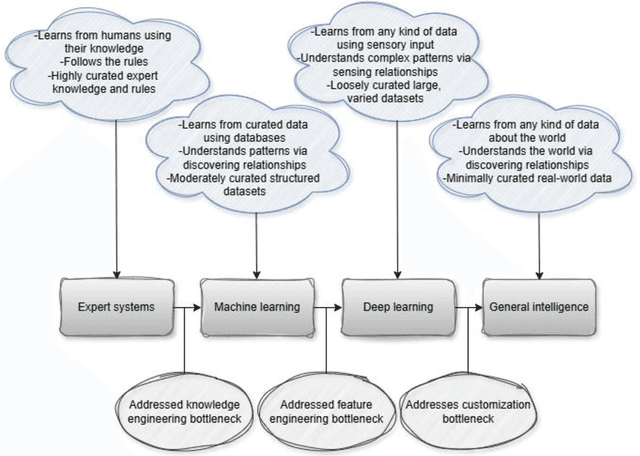
Despite significant advancements in AI-driven educational systems and ongoing calls for responsible AI for education, several critical issues remain unresolved -- acting as the elephant in the room within AI in education, learning analytics, educational data mining, learning sciences, and educational psychology communities. This critical analysis identifies and examines nine persistent challenges that continue to undermine the fairness, transparency, and effectiveness of current AI methods and applications in education. These include: (1) the lack of clarity around what AI for education truly means -- often ignoring the distinct purposes, strengths, and limitations of different AI families -- and the trend of equating it with domain-agnostic, company-driven large language models; (2) the widespread neglect of essential learning processes such as motivation, emotion, and (meta)cognition in AI-driven learner modelling and their contextual nature; (3) limited integration of domain knowledge and lack of stakeholder involvement in AI design and development; (4) continued use of non-sequential machine learning models on temporal educational data; (5) misuse of non-sequential metrics to evaluate sequential models; (6) use of unreliable explainable AI methods to provide explanations for black-box models; (7) ignoring ethical guidelines in addressing data inconsistencies during model training; (8) use of mainstream AI methods for pattern discovery and learning analytics without systematic benchmarking; and (9) overemphasis on global prescriptions while overlooking localised, student-specific recommendations. Supported by theoretical and empirical research, we demonstrate how hybrid AI methods -- specifically neural-symbolic AI -- can address the elephant in the room and serve as the foundation for responsible, trustworthy AI systems in education.
Mathematical Capabilities of Large Language Models in Finnish Matriculation Examination
Apr 15, 2025



Large language models (LLMs) have shown increasing promise in educational settings, yet their mathematical reasoning has been considered evolving. This study evaluates the mathematical capabilities of various LLMs using the Finnish matriculation examination, a high-stakes digital test for upper secondary education. Initial tests yielded moderate performance corresponding to mid-range grades, but later evaluations demonstrated substantial improvements as the language models evolved. Remarkably, some models achieved near-perfect or perfect scores, matching top student performance and qualifying for university admission. Our findings highlight the rapid advances in the mathematical proficiency of LLMs and illustrate their potential to also support educational assessments at scale.
Towards Responsible and Trustworthy Educational Data Mining: Comparing Symbolic, Sub-Symbolic, and Neural-Symbolic AI Methods
Apr 01, 2025Given the demand for responsible and trustworthy AI for education, this study evaluates symbolic, sub-symbolic, and neural-symbolic AI (NSAI) in terms of generalizability and interpretability. Our extensive experiments on balanced and imbalanced self-regulated learning datasets of Estonian primary school students predicting 7th-grade mathematics national test performance showed that symbolic and sub-symbolic methods performed well on balanced data but struggled to identify low performers in imbalanced datasets. Interestingly, symbolic and sub-symbolic methods emphasized different factors in their decision-making: symbolic approaches primarily relied on cognitive and motivational factors, while sub-symbolic methods focused more on cognitive aspects, learned knowledge, and the demographic variable of gender -- yet both largely overlooked metacognitive factors. The NSAI method, on the other hand, showed advantages by: (i) being more generalizable across both classes -- even in imbalanced datasets -- as its symbolic knowledge component compensated for the underrepresented class; and (ii) relying on a more integrated set of factors in its decision-making, including motivation, (meta)cognition, and learned knowledge, thus offering a comprehensive and theoretically grounded interpretability framework. These contrasting findings highlight the need for a holistic comparison of AI methods before drawing conclusions based solely on predictive performance. They also underscore the potential of hybrid, human-centered NSAI methods to address the limitations of other AI families and move us closer to responsible AI for education. Specifically, by enabling stakeholders to contribute to AI design, NSAI aligns learned patterns with theoretical constructs, incorporates factors like motivation and metacognition, and strengthens the trustworthiness and responsibility of educational data mining.
Dementia Classification Using Acoustic Speech and Feature Selection
Feb 04, 2025



Dementia is a general term for a group of syndromes that affect cognitive functions such as memory, thinking, reasoning, and the ability to perform daily tasks. The number of dementia patients is increasing as the population ages, and it is estimated that over 10 million people develop dementia each year. Dementia progresses gradually, and the sooner a patient receives help and support, the better their chances of maintaining their functional abilities. For this reason, early diagnosis of dementia is important. In recent years, machine learning models based on naturally spoken language have been developed for the early diagnosis of dementia. These methods have proven to be user-friendly, cost-effective, scalable, and capable of providing extremely fast diagnoses. This study utilizes the well-known ADReSS challenge dataset for classifying healthy controls and Alzheimer's patients. The dataset contains speech recordings from a picture description task featuring a kitchen scene, collected from both healthy controls and dementia patients. Unlike most studies, this research does not segment the audio recordings into active speech segments; instead, acoustic features are extracted from entire recordings. The study employs Ridge linear regression, Extreme Minimal Learning Machine, and Linear Support Vector Machine machine learning models to compute feature importance scores based on model outputs. The Ridge model performed best in Leave-One-Subject-Out cross-validation, achieving a classification accuracy of 87.8%. The EMLM model, proved to be effective in both cross-validation and the classification of a separate test dataset, with accuracies of 85.3% and 79.2%, respectively. The study's results rank among the top compared to other studies using the same dataset and acoustic feature extraction for dementia diagnosis.
Identification of Cognitive Decline from Spoken Language through Feature Selection and the Bag of Acoustic Words Model
Feb 02, 2024Memory disorders are a central factor in the decline of functioning and daily activities in elderly individuals. The confirmation of the illness, initiation of medication to slow its progression, and the commencement of occupational therapy aimed at maintaining and rehabilitating cognitive abilities require a medical diagnosis. The early identification of symptoms of memory disorders, especially the decline in cognitive abilities, plays a significant role in ensuring the well-being of populations. Features related to speech production are known to connect with the speaker's cognitive ability and changes. The lack of standardized speech tests in clinical settings has led to a growing emphasis on developing automatic machine learning techniques for analyzing naturally spoken language. Non-lexical but acoustic properties of spoken language have proven useful when fast, cost-effective, and scalable solutions are needed for the rapid diagnosis of a disease. The work presents an approach related to feature selection, allowing for the automatic selection of the essential features required for diagnosis from the Geneva minimalistic acoustic parameter set and relative speech pauses, intended for automatic paralinguistic and clinical speech analysis. These features are refined into word histogram features, in which machine learning classifiers are trained to classify control subjects and dementia patients from the Dementia Bank's Pitt audio database. The results show that achieving a 75% average classification accuracy with only twenty-five features with the separate ADReSS 2020 competition test data and the Leave-One-Subject-Out cross-validation of the entire competition data is possible. The results rank at the top compared to international research, where the same dataset and only acoustic features have been used to diagnose patients.