 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Initialization Methods for Large-Scale Clustering
Jul 23, 2020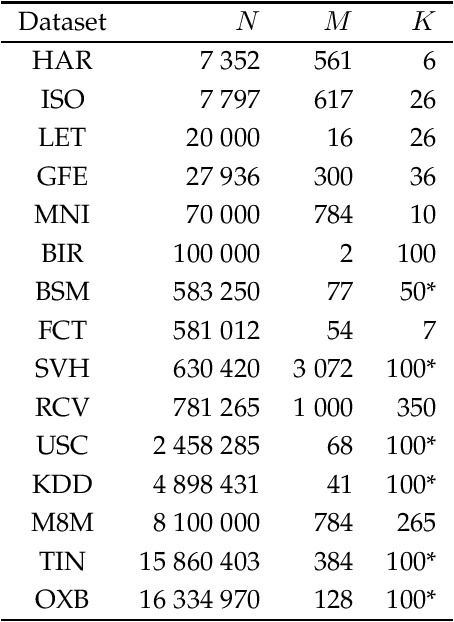
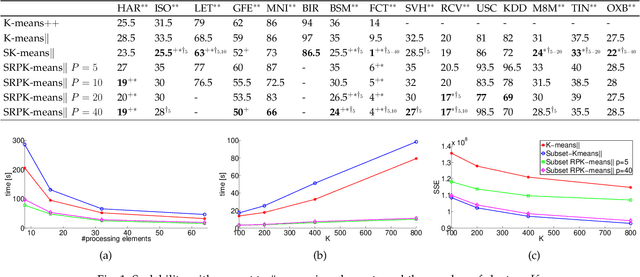
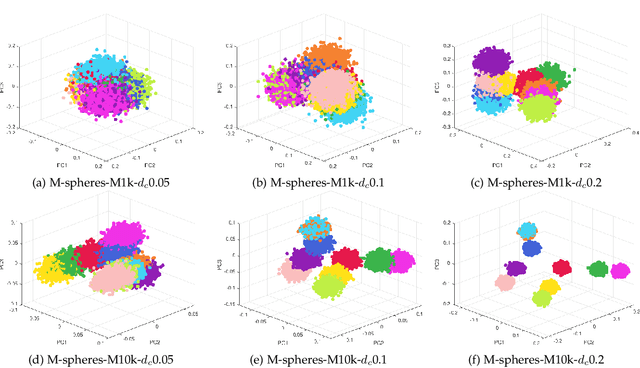
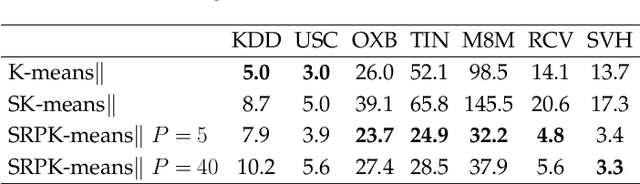
In this work, two new initialization methods for K-means clustering are proposed. Both proposals are based on applying a divide-and-conquer approach for the K-means|| type of an initialization strategy. The second proposal also utilizes multiple lower-dimensional subspaces produced by the random projection method for the initialization. The proposed methods are scalable and can be run in parallel, which make them suitable for initializing large-scale problems. In the experiments, comparison of the proposed methods to the K-means++ and K-means|| methods is conducted using an extensive set of reference and synthetic large-scale datasets. Concerning the latter, a novel high-dimensional clustering data generation algorithm is given. The experiments show that the proposed methods compare favorably to the state-of-the-art. We also observe that the currently most popular K-means++ initialization behaves like the random one in the very high-dimensional cases.