 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping the Challenges of HCI: An Application and Evaluation of ChatGPT and GPT-4 for Cost-Efficient Question Answering
Jun 08, 2023



Large language models (LLMs), such as ChatGPT and GPT-4, are gaining wide-spread real world use. Yet, the two LLMs are closed source, and little is known about the LLMs' performance in real-world use cases. In academia, LLM performance is often measured on benchmarks which may have leaked into ChatGPT's and GPT-4's training data. In this paper, we apply and evaluate ChatGPT and GPT-4 for the real-world task of cost-efficient extractive question answering over a text corpus that was published after the two LLMs completed training. More specifically, we extract research challenges for researchers in the field of HCI from the proceedings of the 2023 Conference on Human Factors in Computing Systems (CHI). We critically evaluate the LLMs on this practical task and conclude that the combination of ChatGPT and GPT-4 makes an excellent cost-efficient means for analyzing a text corpus at scale. Cost-efficiency is key for prototyping research ideas and analyzing text corpora from different perspectives, with implications for applying LLMs in academia and practice. For researchers in HCI, we contribute an interactive visualization of 4392 research challenges in over 90 research topics. We share this visualization and the dataset in the spirit of open science.
Minimal Learning Machine for Multi-Label Learning
May 09, 2023
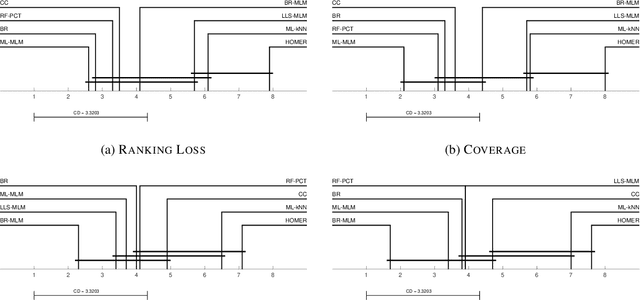
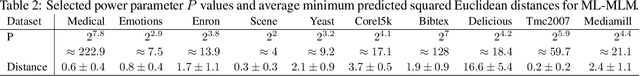
Distance-based supervised method, the minimal learning machine, constructs a predictive model from data by learning a mapping between input and output distance matrices. In this paper, we propose methods and evaluate how this technique and its core component, the distance mapping, can be adapted to multi-label learning. The proposed approach is based on combining the distance mapping with an inverse distance weighting. Although the proposal is one of the simplest methods in the multi-label learning literature, it achieves state-of-the-art performance for small to moderate-sized multi-label learning problems. Besides its simplicity, the proposed method is fully deterministic and its hyper-parameter can be selected via ranking loss-based statistic which has a closed form, thus avoiding conventional cross-validation-based hyper-parameter tuning. In addition, due to its simple linear distance mapping-based construction, we demonstrate that the proposed method can assess predictions' uncertainty for multi-label classification, which is a valuable capability for data-centric machine learning pipelines.
Knowledge Discovery from Atomic Structures using Feature Importances
Feb 28, 2023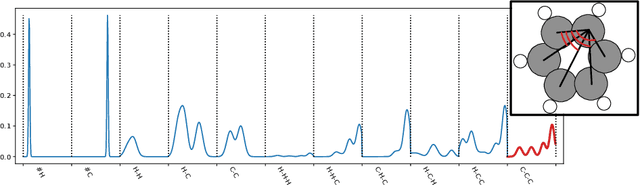
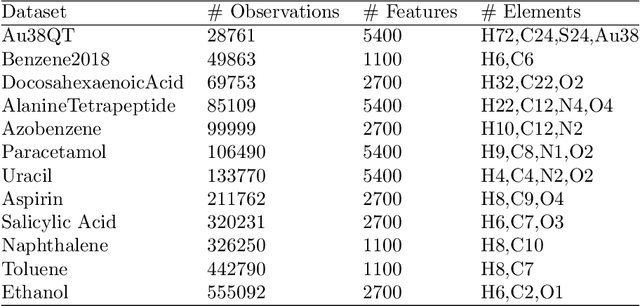
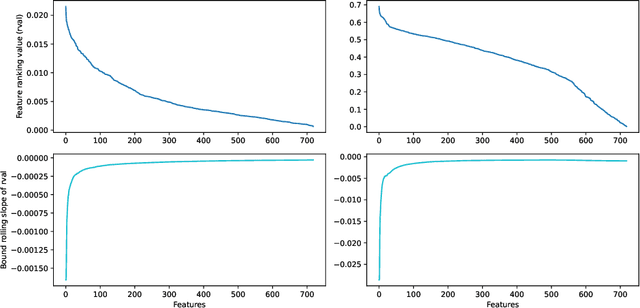
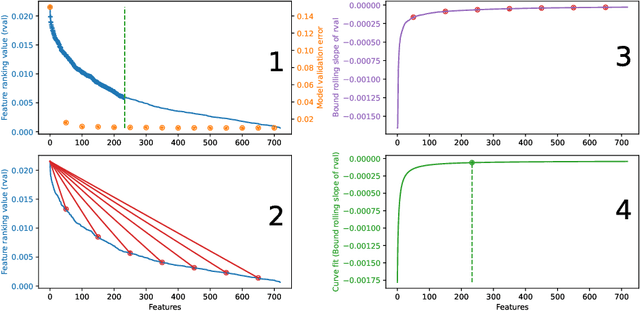
Molecular-level understanding of the interactions between the constituents of an atomic structure is essential for designing novel materials in various applications. This need goes beyond the basic knowledge of the number and types of atoms, their chemical composition, and the character of the chemical interactions. The bigger picture takes place on the quantum level which can be addressed by using the Density-functional theory (DFT). Use of DFT, however, is a computationally taxing process, and its results do not readily provide easily interpretable insight into the atomic interactions which would be useful information in material design. An alternative way to address atomic interactions is to use an interpretable machine learning approach, where a predictive DFT surrogate is constructed and analyzed. The purpose of this paper is to propose such a procedure using a modification of the recently published interpretable distance-based regression method. Our tests with a representative benchmark set of molecules and a complex hybrid nanoparticle confirm the viability and usefulness of the proposed approach.
Scalable Initialization Methods for Large-Scale Clustering
Jul 23, 2020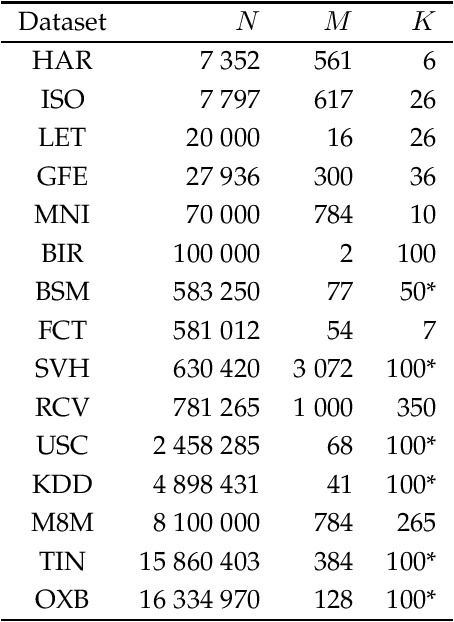
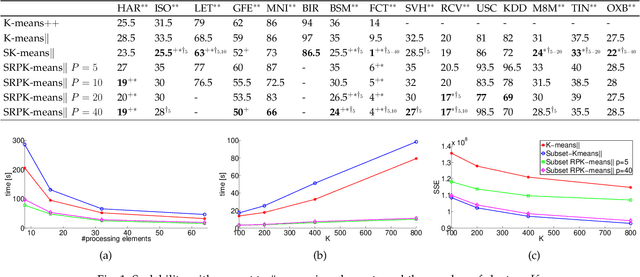
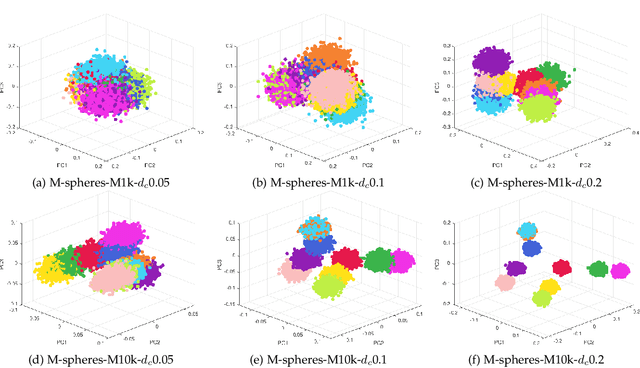
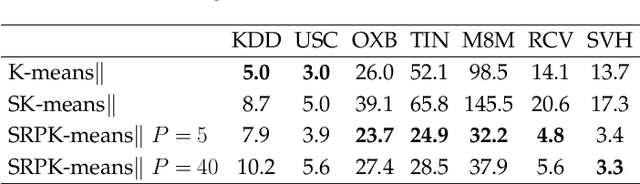
In this work, two new initialization methods for K-means clustering are proposed. Both proposals are based on applying a divide-and-conquer approach for the K-means|| type of an initialization strategy. The second proposal also utilizes multiple lower-dimensional subspaces produced by the random projection method for the initialization. The proposed methods are scalable and can be run in parallel, which make them suitable for initializing large-scale problems. In the experiments, comparison of the proposed methods to the K-means++ and K-means|| methods is conducted using an extensive set of reference and synthetic large-scale datasets. Concerning the latter, a novel high-dimensional clustering data generation algorithm is given. The experiments show that the proposed methods compare favorably to the state-of-the-art. We also observe that the currently most popular K-means++ initialization behaves like the random one in the very high-dimensional cases.
Minimal Learning Machine: Theoretical Results and Clustering-Based Reference Point Selection
Sep 22, 2019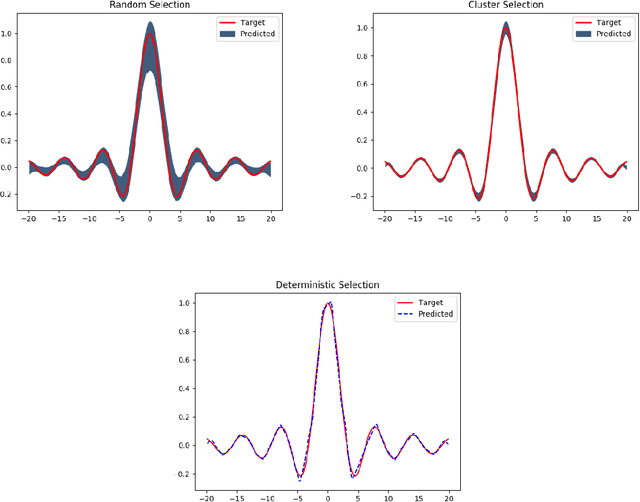

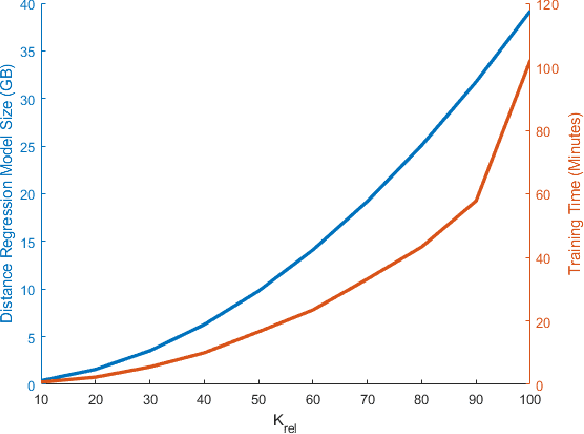
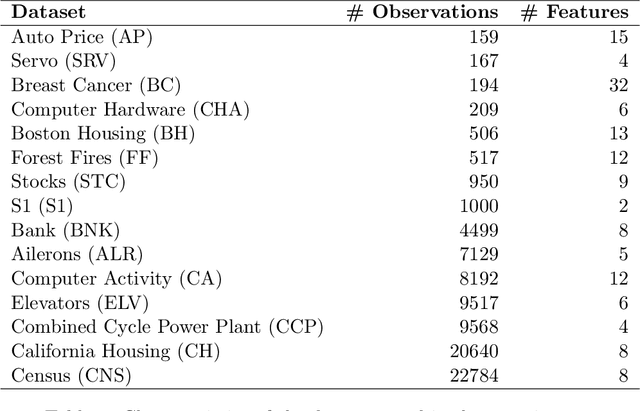
The Minimal Learning Machine (MLM) is a nonlinear supervised approach based on learning a linear mapping between distance matrices computed in the input and output data spaces, where distances are calculated concerning a subset of points called reference points. Its simple formulation has attracted several recent works on extensions and applications. In this paper, we aim to address some open questions related to the MLM. First, we detail theoretical aspects that assure the interpolation and universal approximation capabilities of the MLM, which were previously only empirically verified. Second, we identify the task of selecting reference points as having major importance for the MLM's generalization capability; furthermore, we assess several clustering-based methods in regression scenarios. Based on an extensive empirical evaluation, we conclude that the evaluated methods are both scalable and useful. Specifically, for a small number of reference points, the clustering-based methods outperformed the standard random selection of the original MLM formulation.