 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAGSM: Disentangled Avatar Generation with GS-enhanced Mesh
Nov 20, 2024



Text-driven avatar generation has gained significant attention owing to its convenience. However, existing methods typically model the human body with all garments as a single 3D model, limiting its usability, such as clothing replacement, and reducing user control over the generation process. To overcome the limitations above, we propose DAGSM, a novel pipeline that generates disentangled human bodies and garments from the given text prompts. Specifically, we model each part (e.g., body, upper/lower clothes) of the clothed human as one GS-enhanced mesh (GSM), which is a traditional mesh attached with 2D Gaussians to better handle complicated textures (e.g., woolen, translucent clothes) and produce realistic cloth animations. During the generation, we first create the unclothed body, followed by a sequence of individual cloth generation based on the body, where we introduce a semantic-based algorithm to achieve better human-cloth and garment-garment separation. To improve texture quality, we propose a view-consistent texture refinement module, including a cross-view attention mechanism for texture style consistency and an incident-angle-weighted denoising (IAW-DE) strategy to update the appearance. Extensive experiments have demonstrated that DAGSM generates high-quality disentangled avatars, supports clothing replacement and realistic animation, and outperforms the baselines in visual quality.
TIP-Editor: An Accurate 3D Editor Following Both Text-Prompts And Image-Prompts
Jan 26, 2024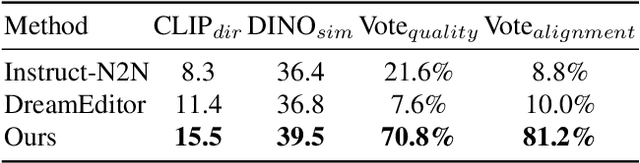


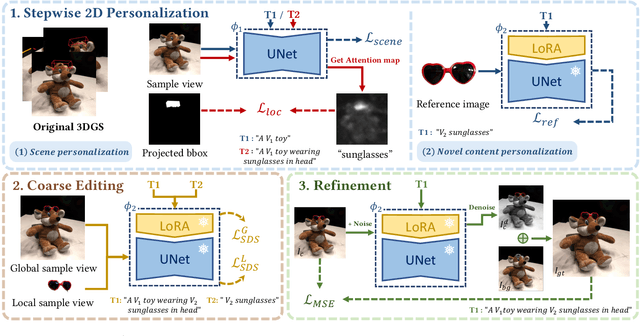
Text-driven 3D scene editing has gained significant attention owing to its convenience and user-friendliness. However, existing methods still lack accurate control of the specified appearance and location of the editing result due to the inherent limitations of the text description. To this end, we propose a 3D scene editing framework, TIPEditor, that accepts both text and image prompts and a 3D bounding box to specify the editing region. With the image prompt, users can conveniently specify the detailed appearance/style of the target content in complement to the text description, enabling accurate control of the appearance. Specifically, TIP-Editor employs a stepwise 2D personalization strategy to better learn the representation of the existing scene and the reference image, in which a localization loss is proposed to encourage correct object placement as specified by the bounding box. Additionally, TIPEditor utilizes explicit and flexible 3D Gaussian splatting as the 3D representation to facilitate local editing while keeping the background unchanged. Extensive experiments have demonstrated that TIP-Editor conducts accurate editing following the text and image prompts in the specified bounding box region, consistently outperforming the baselines in editing quality, and the alignment to the prompts, qualitatively and quantitatively.
Credible Teacher for Semi-Supervised Object Detection in Open Scene
Jan 03, 2024


Semi-Supervised Object Detection (SSOD) has achieved resounding success by leveraging unlabeled data to improve detection performance. However, in Open Scene Semi-Supervised Object Detection (O-SSOD), unlabeled data may contains unknown objects not observed in the labeled data, which will increase uncertainty in the model's predictions for known objects. It is detrimental to the current methods that mainly rely on self-training, as more uncertainty leads to the lower localization and classification precision of pseudo labels. To this end, we propose Credible Teacher, an end-to-end framework. Credible Teacher adopts an interactive teaching mechanism using flexible labels to prevent uncertain pseudo labels from misleading the model and gradually reduces its uncertainty through the guidance of other credible pseudo labels. Empirical results have demonstrated our method effectively restrains the adverse effect caused by O-SSOD and significantly outperforms existing counterparts.
DreamEditor: Text-Driven 3D Scene Editing with Neural Fields
Jun 29, 2023



Neural fields have achieved impressive advancements in view synthesis and scene reconstruction. However, editing these neural fields remains challenging due to the implicit encoding of geometry and texture information. In this paper, we propose DreamEditor, a novel framework that enables users to perform controlled editing of neural fields using text prompts. By representing scenes as mesh-based neural fields, DreamEditor allows localized editing within specific regions. DreamEditor utilizes the text encoder of a pretrained text-to-Image diffusion model to automatically identify the regions to be edited based on the semantics of the text prompts. Subsequently, DreamEditor optimizes the editing region and aligns its geometry and texture with the text prompts through score distillation sampling [29]. Extensive experiments have demonstrated that DreamEditor can accurately edit neural fields of real-world scenes according to the given text prompts while ensuring consistency in irrelevant areas. DreamEditor generates highly realistic textures and geometry, significantly surpassing previous works in both quantitative and qualitative evaluations.
Open Set Domain Adaptation By Novel Class Discovery
Mar 07, 2022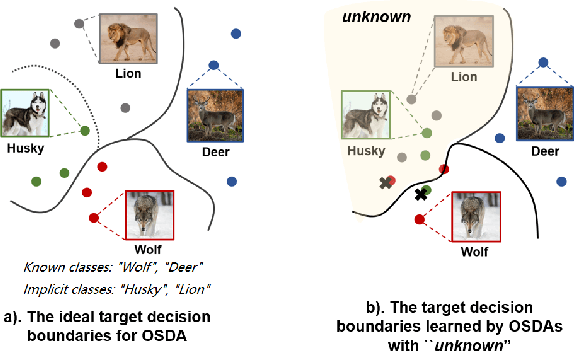
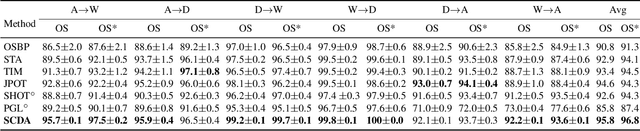
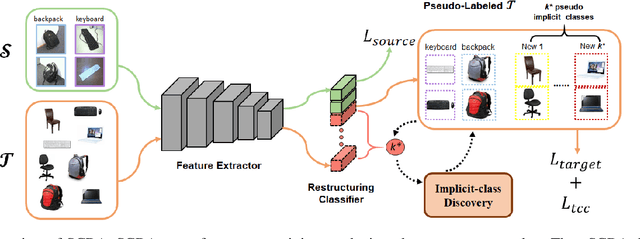

In Open Set Domain Adaptation (OSDA), large amounts of target samples are drawn from the implicit categories that never appear in the source domain. Due to the lack of their specific belonging, existing methods indiscriminately regard them as a single class unknown. We challenge this broadly-adopted practice that may arouse unexpected detrimental effects because the decision boundaries between the implicit categories have been fully ignored. Instead, we propose Self-supervised Class-Discovering Adapter (SCDA) that attempts to achieve OSDA by gradually discovering those implicit classes, then incorporating them to restructure the classifier and update the domain-adaptive features iteratively. SCDA performs two alternate steps to achieve implicit class discovery and self-supervised OSDA, respectively. By jointly optimizing for two tasks, SCDA achieves the state-of-the-art in OSDA and shows a competitive performance to unearth the implicit target classes.
Blending-target Domain Adaptation by Adversarial Meta-Adaptation Networks
Jul 08, 2019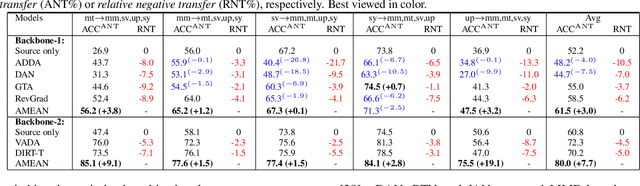
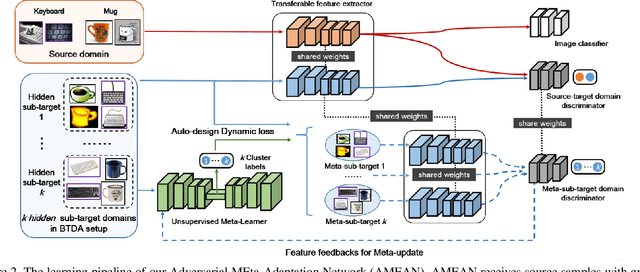
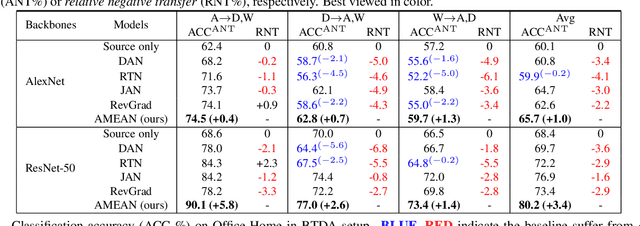
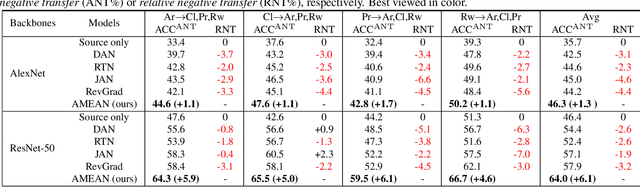
(Unsupervised) Domain Adaptation (DA) seeks for classifying target instances when solely provided with source labeled and target unlabeled examples for training. Learning domain-invariant features helps to achieve this goal, whereas it underpins unlabeled samples drawn from a single or multiple explicit target domains (Multi-target DA). In this paper, we consider a more realistic transfer scenario: our target domain is comprised of multiple sub-targets implicitly blended with each other, so that learners could not identify which sub-target each unlabeled sample belongs to. This Blending-target Domain Adaptation (BTDA) scenario commonly appears in practice and threatens the validities of most existing DA algorithms, due to the presence of domain gaps and categorical misalignments among these hidden sub-targets. To reap the transfer performance gains in this new scenario, we propose Adversarial Meta-Adaptation Network (AMEAN). AMEAN entails two adversarial transfer learning processes. The first is a conventional adversarial transfer to bridge our source and mixed target domains. To circumvent the intra-target category misalignment, the second process presents as ``learning to adapt'': It deploys an unsupervised meta-learner receiving target data and their ongoing feature-learning feedbacks, to discover target clusters as our ``meta-sub-target'' domains. These meta-sub-targets auto-design our meta-sub-target DA loss, which empirically eliminates the implicit category mismatching in our mixed target. We evaluate AMEAN and a variety of DA algorithms in three benchmarks under the BTDA setup. Empirical results show that BTDA is a quite challenging transfer setup for most existing DA algorithms, yet AMEAN significantly outperforms these state-of-the-art baselines and effectively restrains the negative transfer effects in BTDA.