 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Comparison of Encoder-Based Language Models and Feature-Based Supervised Machine Learning Approaches to Automated Scoring of Long Essays
Jan 07, 2026Long context may impose challenges for encoder-only language models in text processing, specifically for automated scoring of essays. This study trained several commonly used encoder-based language models for automated scoring of long essays. The performance of these trained models was evaluated and compared with the ensemble models built upon the base language models with a token limit of 512?. The experimented models include BERT-based models (BERT, RoBERTa, DistilBERT, and DeBERTa), ensemble models integrating embeddings from multiple encoder models, and ensemble models of feature-based supervised machine learning models, including Gradient-Boosted Decision Trees, eXtreme Gradient Boosting, and Light Gradient Boosting Machine. We trained, validated, and tested each model on a dataset of 17,307 essays, with an 80%/10%/10% split, and evaluated model performance using Quadratic Weighted Kappa. This study revealed that an ensemble-of-embeddings model that combines multiple pre-trained language model representations with gradient-boosting classifier as the ensemble model significantly outperforms individual language models at scoring long essays.
H2VU-Benchmark: A Comprehensive Benchmark for Hierarchical Holistic Video Understanding
Mar 31, 2025With the rapid development of multimodal models, the demand for assessing video understanding capabilities has been steadily increasing. However, existing benchmarks for evaluating video understanding exhibit significant limitations in coverage, task diversity, and scene adaptability. These shortcomings hinder the accurate assessment of models' comprehensive video understanding capabilities. To tackle this challenge, we propose a hierarchical and holistic video understanding (H2VU) benchmark designed to evaluate both general video and online streaming video comprehension. This benchmark contributes three key features: Extended video duration: Spanning videos from brief 3-second clips to comprehensive 1.5-hour recordings, thereby bridging the temporal gaps found in current benchmarks. Comprehensive assessment tasks: Beyond traditional perceptual and reasoning tasks, we have introduced modules for countercommonsense comprehension and trajectory state tracking. These additions test the models' deep understanding capabilities beyond mere prior knowledge. Enriched video data: To keep pace with the rapid evolution of current AI agents, we have expanded first-person streaming video datasets. This expansion allows for the exploration of multimodal models' performance in understanding streaming videos from a first-person perspective. Extensive results from H2VU reveal that existing multimodal large language models (MLLMs) possess substantial potential for improvement in our newly proposed evaluation tasks. We expect that H2VU will facilitate advancements in video understanding research by offering a comprehensive and in-depth analysis of MLLMs.
MarvelOVD: Marrying Object Recognition and Vision-Language Models for Robust Open-Vocabulary Object Detection
Jul 31, 2024



Learning from pseudo-labels that generated with VLMs~(Vision Language Models) has been shown as a promising solution to assist open vocabulary detection (OVD) in recent studies. However, due to the domain gap between VLM and vision-detection tasks, pseudo-labels produced by the VLMs are prone to be noisy, while the training design of the detector further amplifies the bias. In this work, we investigate the root cause of VLMs' biased prediction under the OVD context. Our observations lead to a simple yet effective paradigm, coded MarvelOVD, that generates significantly better training targets and optimizes the learning procedure in an online manner by marrying the capability of the detector with the vision-language model. Our key insight is that the detector itself can act as a strong auxiliary guidance to accommodate VLM's inability of understanding both the ``background'' and the context of a proposal within the image. Based on it, we greatly purify the noisy pseudo-labels via Online Mining and propose Adaptive Reweighting to effectively suppress the biased training boxes that are not well aligned with the target object. In addition, we also identify a neglected ``base-novel-conflict'' problem and introduce stratified label assignments to prevent it. Extensive experiments on COCO and LVIS datasets demonstrate that our method outperforms the other state-of-the-arts by significant margins. Codes are available at https://github.com/wkfdb/MarvelOVD
Credible Teacher for Semi-Supervised Object Detection in Open Scene
Jan 03, 2024


Semi-Supervised Object Detection (SSOD) has achieved resounding success by leveraging unlabeled data to improve detection performance. However, in Open Scene Semi-Supervised Object Detection (O-SSOD), unlabeled data may contains unknown objects not observed in the labeled data, which will increase uncertainty in the model's predictions for known objects. It is detrimental to the current methods that mainly rely on self-training, as more uncertainty leads to the lower localization and classification precision of pseudo labels. To this end, we propose Credible Teacher, an end-to-end framework. Credible Teacher adopts an interactive teaching mechanism using flexible labels to prevent uncertain pseudo labels from misleading the model and gradually reduces its uncertainty through the guidance of other credible pseudo labels. Empirical results have demonstrated our method effectively restrains the adverse effect caused by O-SSOD and significantly outperforms existing counterparts.
Semi-DETR: Semi-Supervised Object Detection with Detection Transformers
Jul 16, 2023



We analyze the DETR-based framework on semi-supervised object detection (SSOD) and observe that (1) the one-to-one assignment strategy generates incorrect matching when the pseudo ground-truth bounding box is inaccurate, leading to training inefficiency; (2) DETR-based detectors lack deterministic correspondence between the input query and its prediction output, which hinders the applicability of the consistency-based regularization widely used in current SSOD methods. We present Semi-DETR, the first transformer-based end-to-end semi-supervised object detector, to tackle these problems. Specifically, we propose a Stage-wise Hybrid Matching strategy that combines the one-to-many assignment and one-to-one assignment strategies to improve the training efficiency of the first stage and thus provide high-quality pseudo labels for the training of the second stage. Besides, we introduce a Crossview Query Consistency method to learn the semantic feature invariance of object queries from different views while avoiding the need to find deterministic query correspondence. Furthermore, we propose a Cost-based Pseudo Label Mining module to dynamically mine more pseudo boxes based on the matching cost of pseudo ground truth bounding boxes for consistency training. Extensive experiments on all SSOD settings of both COCO and Pascal VOC benchmark datasets show that our Semi-DETR method outperforms all state-of-the-art methods by clear margins. The PaddlePaddle version code1 is at https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/semi_det/semi_detr.
Urban Regional Function Guided Traffic Flow Prediction
Mar 20, 2023


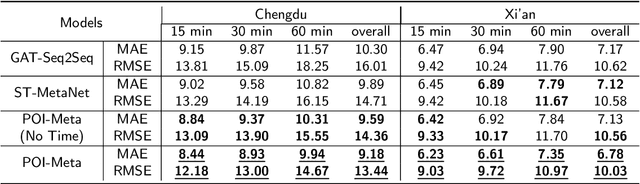
The prediction of traffic flow is a challenging yet crucial problem in spatial-temporal analysis, which has recently gained increasing interest. In addition to spatial-temporal correlations, the functionality of urban areas also plays a crucial role in traffic flow prediction. However, the exploration of regional functional attributes mainly focuses on adding additional topological structures, ignoring the influence of functional attributes on regional traffic patterns. Different from the existing works, we propose a novel module named POI-MetaBlock, which utilizes the functionality of each region (represented by Point of Interest distribution) as metadata to further mine different traffic characteristics in areas with different functions. Specifically, the proposed POI-MetaBlock employs a self-attention architecture and incorporates POI and time information to generate dynamic attention parameters for each region, which enables the model to fit different traffic patterns of various areas at different times. Furthermore, our lightweight POI-MetaBlock can be easily integrated into conventional traffic flow prediction models. Extensive experiments demonstrate that our module significantly improves the performance of traffic flow prediction and outperforms state-of-the-art methods that use metadata.
Aerial Images Meet Crowdsourced Trajectories: A New Approach to Robust Road Extraction
Nov 30, 2021

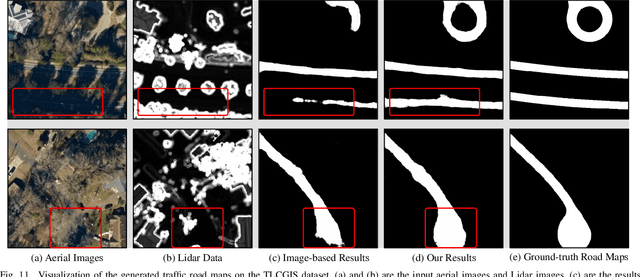

Land remote sensing analysis is a crucial research in earth science. In this work, we focus on a challenging task of land analysis, i.e., automatic extraction of traffic roads from remote sensing data, which has widespread applications in urban development and expansion estimation. Nevertheless, conventional methods either only utilized the limited information of aerial images, or simply fused multimodal information (e.g., vehicle trajectories), thus cannot well recognize unconstrained roads. To facilitate this problem, we introduce a novel neural network framework termed Cross-Modal Message Propagation Network (CMMPNet), which fully benefits the complementary different modal data (i.e., aerial images and crowdsourced trajectories). Specifically, CMMPNet is composed of two deep Auto-Encoders for modality-specific representation learning and a tailor-designed Dual Enhancement Module for cross-modal representation refinement. In particular, the complementary information of each modality is comprehensively extracted and dynamically propagated to enhance the representation of another modality. Extensive experiments on three real-world benchmarks demonstrate the effectiveness of our CMMPNet for robust road extraction benefiting from blending different modal data, either using image and trajectory data or image and Lidar data. From the experimental results, we observe that the proposed approach outperforms current state-of-the-art methods by large margins.
Segmentation-Aware and Adaptive Iris Recognition
Dec 31, 2019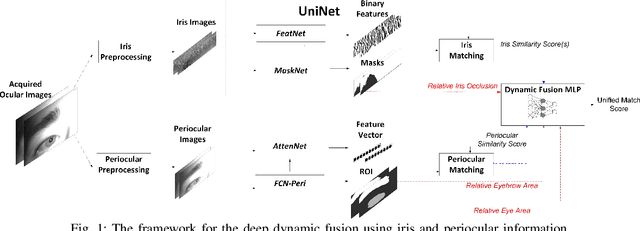

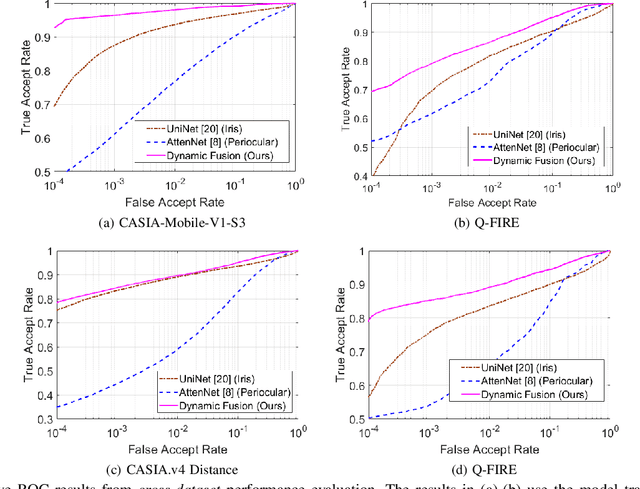
Iris recognition has emerged as one of the most accurate and convenient biometric for the human identification and has been increasingly employed in a wide range of e-security applications. The quality of iris images acquired at-a-distance or under less constrained imaging environments is known to degrade the iris matching accuracy. The periocular information is inherently embedded in such iris images and can be exploited to assist in the iris recognition under such non-ideal scenarios. Our analysis of such iris templates also indicates significant degradation and reduction in the region of interest, where the iris recognition can benefit from a similarity distance that can consider importance of different binary bits, instead of the direct use of Hamming distance in the literature. Periocular information can be dynamically reinforced, by incorporating the differences in the effective area of available iris regions, for more accurate iris recognition. This paper presents such a segmentation-assisted adaptive framework for more accurate less-constrained iris recognition. The effectiveness of this framework is evaluated on three publicly available iris databases using within-dataset and cross-dataset performance evaluation and validates the merit of the proposed iris recognition framework.