 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUIDED: Granular Understanding via Identification, Detection, and Discrimination for Fine-Grained Open-Vocabulary Object Detection
Mar 27, 2026Fine-grained open-vocabulary object detection (FG-OVD) aims to detect novel object categories described by attribute-rich texts. While existing open-vocabulary detectors show promise at the base-category level, they underperform in fine-grained settings due to the semantic entanglement of subjects and attributes in pretrained vision-language model (VLM) embeddings -- leading to over-representation of attributes, mislocalization, and semantic drift in embedding space. We propose GUIDED, a decomposition framework specifically designed to address the semantic entanglement between subjects and attributes in fine-grained prompts. By separating object localization and fine-grained recognition into distinct pathways, HUIDED aligns each subtask with the module best suited for its respective roles. Specifically, given a fine-grained class name, we first use a language model to extract a coarse-grained subject and its descriptive attributes. Then the detector is guided solely by the subject embedding, ensuring stable localization unaffected by irrelevant or overrepresented attributes. To selectively retain helpful attributes, we introduce an attribute embedding fusion module that incorporates attribute information into detection queries in an attention-based manner. This mitigates over-representation while preserving discriminative power. Finally, a region-level attribute discrimination module compares each detected region against full fine-grained class names using a refined vision-language model with a projection head for improved alignment. Extensive experiments on FG-OVD and 3F-OVD benchmarks show that GUIDED achieves new state-of-the-art results, demonstrating the benefits of disentangled modeling and modular optimization. Our code will be released at https://github.com/lijm48/GUIDED.
DualPrim: Compact 3D Reconstruction with Positive and Negative Primitives
Mar 17, 2026Neural reconstructions often trade structure for fidelity, yielding dense and unstructured meshes with irregular topology and weak part boundaries that hinder editing, animation, and downstream asset reuse. We present DualPrim, a compact and structured 3D reconstruction framework. Unlike additive-only implicit or primitive methods, DualPrim represents shapes with positive and negative superquadrics: the former builds the bases while the latter carves local volumes through a differentiable operator, enabling topology-aware modeling of holes and concavities. This additive-subtractive design increases the representational power without sacrificing compactness or differentiability. We embed DualPrim in a volumetric differentiable renderer, enabling end-to-end learning from multi-view images and seamless mesh export via closed-form boolean difference. Empirically, DualPrim delivers state-of-the-art accuracy and produces compact, structured, and interpretable outputs that better satisfy downstream needs than additive-only alternatives.
SAP: Segment Any 4K Panorama
Mar 13, 2026Promptable instance segmentation is widely adopted in embodied and AR systems, yet the performance of foundation models trained on perspective imagery often degrades on 360° panoramas. In this paper, we introduce Segment Any 4K Panorama (SAP), a foundation model for 4K high-resolution panoramic instance-level segmentation. We reformulate panoramic segmentation as fixed-trajectory perspective video segmentation, decomposing a panorama into overlapping perspective patches sampled along a continuous spherical traversal. This memory-aligned reformulation preserves native 4K resolution while restoring the smooth viewpoint transitions required for stable cross-view propagation. To enable large-scale supervision, we synthesize 183,440 4K-resolution panoramic images with instance segmentation labels using the InfiniGen engine. Trained under this trajectory-aligned paradigm, SAP generalizes effectively to real-world 360° images, achieving +17.2 zero-shot mIoU gain over vanilla SAM2 of different sizes on real-world 4K panorama benchmark.
CoSMo3D: Open-World Promptable 3D Semantic Part Segmentation through LLM-Guided Canonical Spatial Modeling
Mar 01, 2026Open-world promptable 3D semantic segmentation remains brittle as semantics are inferred in the input sensor coordinates. Yet, humans, in contrast, interpret parts via functional roles in a canonical space -- wings extend laterally, handles protrude to the side, and legs support from below. Psychophysical evidence shows that we mentally rotate objects into canonical frames to reveal these roles. To fill this gap, we propose \methodName{}, which attains canonical space perception by inducing a latent canonical reference frame learned directly from data. By construction, we create a unified canonical dataset through LLM-guided intra- and cross-category alignment, exposing canonical spatial regularities across 200 categories. By induction, we realize canonicality inside the model through a dual-branch architecture with canonical map anchoring and canonical box calibration, collapsing pose variation and symmetry into a stable canonical embedding. This shift from input pose space to canonical embedding yields far more stable and transferable part semantics. Experimental results show that \methodName{} establishes new state of the art in open-world promptable 3D segmentation.
MonkeyOCR v1.5 Technical Report: Unlocking Robust Document Parsing for Complex Patterns
Nov 16, 2025Document parsing is a core task in document intelligence, supporting applications such as information extraction, retrieval-augmented generation, and automated document analysis. However, real-world documents often feature complex layouts with multi-level tables, embedded images or formulas, and cross-page structures, which remain challenging for existing OCR systems. We introduce MonkeyOCR v1.5, a unified vision-language framework that enhances both layout understanding and content recognition through a two-stage pipeline. The first stage employs a large multimodal model to jointly predict layout and reading order, leveraging visual information to ensure sequential consistency. The second stage performs localized recognition of text, formulas, and tables within detected regions, maintaining high visual fidelity while reducing error propagation. To address complex table structures, we propose a visual consistency-based reinforcement learning scheme that evaluates recognition quality via render-and-compare alignment, improving structural accuracy without manual annotations. Additionally, two specialized modules, Image-Decoupled Table Parsing and Type-Guided Table Merging, are introduced to enable reliable parsing of tables containing embedded images and reconstruction of tables crossing pages or columns. Comprehensive experiments on OmniDocBench v1.5 demonstrate that MonkeyOCR v1.5 achieves state-of-the-art performance, outperforming PPOCR-VL and MinerU 2.5 while showing exceptional robustness in visually complex document scenarios. A trial link can be found at https://github.com/Yuliang-Liu/MonkeyOCR .
AvatarTex: High-Fidelity Facial Texture Reconstruction from Single-Image Stylized Avatars
Nov 10, 2025We present AvatarTex, a high-fidelity facial texture reconstruction framework capable of generating both stylized and photorealistic textures from a single image. Existing methods struggle with stylized avatars due to the lack of diverse multi-style datasets and challenges in maintaining geometric consistency in non-standard textures. To address these limitations, AvatarTex introduces a novel three-stage diffusion-to-GAN pipeline. Our key insight is that while diffusion models excel at generating diversified textures, they lack explicit UV constraints, whereas GANs provide a well-structured latent space that ensures style and topology consistency. By integrating these strengths, AvatarTex achieves high-quality topology-aligned texture synthesis with both artistic and geometric coherence. Specifically, our three-stage pipeline first completes missing texture regions via diffusion-based inpainting, refines style and structure consistency using GAN-based latent optimization, and enhances fine details through diffusion-based repainting. To address the need for a stylized texture dataset, we introduce TexHub, a high-resolution collection of 20,000 multi-style UV textures with precise UV-aligned layouts. By leveraging TexHub and our structured diffusion-to-GAN pipeline, AvatarTex establishes a new state-of-the-art in multi-style facial texture reconstruction. TexHub will be released upon publication to facilitate future research in this field.
AdaDrive: Self-Adaptive Slow-Fast System for Language-Grounded Autonomous Driving
Nov 09, 2025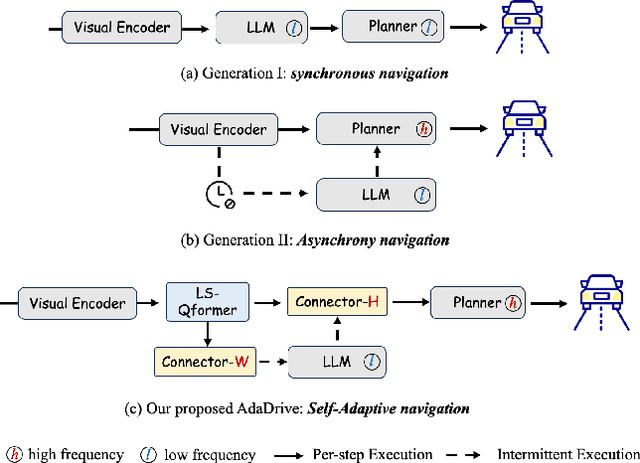
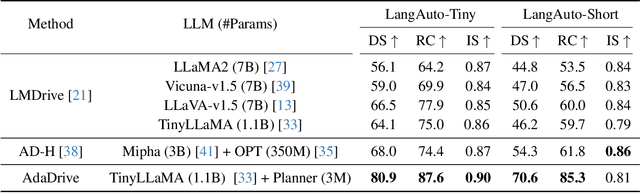
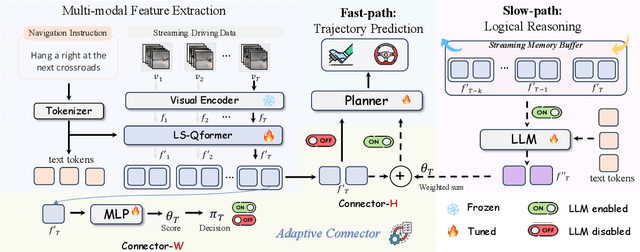
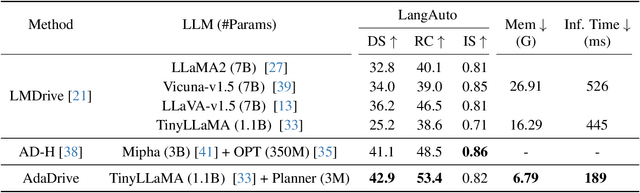
Effectively integrating Large Language Models (LLMs) into autonomous driving requires a balance between leveraging high-level reasoning and maintaining real-time efficiency. Existing approaches either activate LLMs too frequently, causing excessive computational overhead, or use fixed schedules, failing to adapt to dynamic driving conditions. To address these challenges, we propose AdaDrive, an adaptively collaborative slow-fast framework that optimally determines when and how LLMs contribute to decision-making. (1) When to activate the LLM: AdaDrive employs a novel adaptive activation loss that dynamically determines LLM invocation based on a comparative learning mechanism, ensuring activation only in complex or critical scenarios. (2) How to integrate LLM assistance: Instead of rigid binary activation, AdaDrive introduces an adaptive fusion strategy that modulates a continuous, scaled LLM influence based on scene complexity and prediction confidence, ensuring seamless collaboration with conventional planners. Through these strategies, AdaDrive provides a flexible, context-aware framework that maximizes decision accuracy without compromising real-time performance. Extensive experiments on language-grounded autonomous driving benchmarks demonstrate that AdaDrive state-of-the-art performance in terms of both driving accuracy and computational efficiency. Code is available at https://github.com/ReaFly/AdaDrive.
SPGen: Spherical Projection as Consistent and Flexible Representation for Single Image 3D Shape Generation
Sep 16, 2025
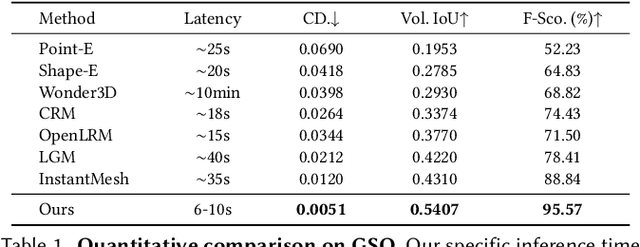
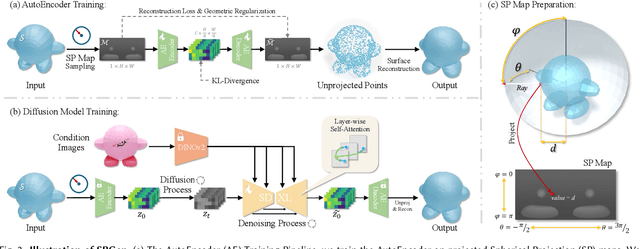
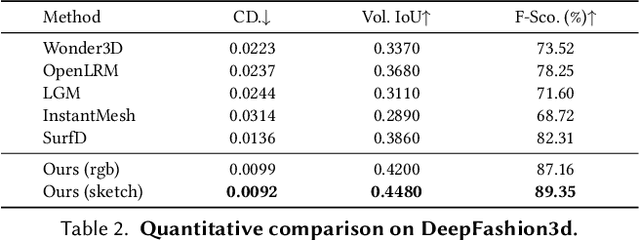
Existing single-view 3D generative models typically adopt multiview diffusion priors to reconstruct object surfaces, yet they remain prone to inter-view inconsistencies and are unable to faithfully represent complex internal structure or nontrivial topologies. In particular, we encode geometry information by projecting it onto a bounding sphere and unwrapping it into a compact and structural multi-layer 2D Spherical Projection (SP) representation. Operating solely in the image domain, SPGen offers three key advantages simultaneously: (1) Consistency. The injective SP mapping encodes surface geometry with a single viewpoint which naturally eliminates view inconsistency and ambiguity; (2) Flexibility. Multi-layer SP maps represent nested internal structures and support direct lifting to watertight or open 3D surfaces; (3) Efficiency. The image-domain formulation allows the direct inheritance of powerful 2D diffusion priors and enables efficient finetuning with limited computational resources. Extensive experiments demonstrate that SPGen significantly outperforms existing baselines in geometric quality and computational efficiency.
GarmentX: Autoregressive Parametric Representations for High-Fidelity 3D Garment Generation
Apr 29, 2025This work presents GarmentX, a novel framework for generating diverse, high-fidelity, and wearable 3D garments from a single input image. Traditional garment reconstruction methods directly predict 2D pattern edges and their connectivity, an overly unconstrained approach that often leads to severe self-intersections and physically implausible garment structures. In contrast, GarmentX introduces a structured and editable parametric representation compatible with GarmentCode, ensuring that the decoded sewing patterns always form valid, simulation-ready 3D garments while allowing for intuitive modifications of garment shape and style. To achieve this, we employ a masked autoregressive model that sequentially predicts garment parameters, leveraging autoregressive modeling for structured generation while mitigating inconsistencies in direct pattern prediction. Additionally, we introduce GarmentX dataset, a large-scale dataset of 378,682 garment parameter-image pairs, constructed through an automatic data generation pipeline that synthesizes diverse and high-quality garment images conditioned on parametric garment representations. Through integrating our method with GarmentX dataset, we achieve state-of-the-art performance in geometric fidelity and input image alignment, significantly outperforming prior approaches. We will release GarmentX dataset upon publication.
TASTE-Rob: Advancing Video Generation of Task-Oriented Hand-Object Interaction for Generalizable Robotic Manipulation
Mar 14, 2025

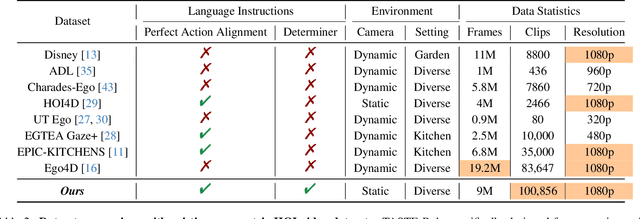
We address key limitations in existing datasets and models for task-oriented hand-object interaction video generation, a critical approach of generating video demonstrations for robotic imitation learning. Current datasets, such as Ego4D, often suffer from inconsistent view perspectives and misaligned interactions, leading to reduced video quality and limiting their applicability for precise imitation learning tasks. Towards this end, we introduce TASTE-Rob -- a pioneering large-scale dataset of 100,856 ego-centric hand-object interaction videos. Each video is meticulously aligned with language instructions and recorded from a consistent camera viewpoint to ensure interaction clarity. By fine-tuning a Video Diffusion Model (VDM) on TASTE-Rob, we achieve realistic object interactions, though we observed occasional inconsistencies in hand grasping postures. To enhance realism, we introduce a three-stage pose-refinement pipeline that improves hand posture accuracy in generated videos. Our curated dataset, coupled with the specialized pose-refinement framework, provides notable performance gains in generating high-quality, task-oriented hand-object interaction videos, resulting in achieving superior generalizable robotic manipulation. The TASTE-Rob dataset will be made publicly available upon publication to foster further advancements in the field.