 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTPano: Multi-Task Panoramic Scene Understanding via Label-Free Integration of Dense Prediction Priors
Feb 05, 2026Comprehensive panoramic scene understanding is critical for immersive applications, yet it remains challenging due to the scarcity of high-resolution, multi-task annotations. While perspective foundation models have achieved success through data scaling, directly adapting them to the panoramic domain often fails due to severe geometric distortions and coordinate system discrepancies. Furthermore, the underlying relations between diverse dense prediction tasks in spherical spaces are underexplored. To address these challenges, we propose MTPano, a robust multi-task panoramic foundation model established by a label-free training pipeline. First, to circumvent data scarcity, we leverage powerful perspective dense priors. We project panoramic images into perspective patches to generate accurate, domain-gap-free pseudo-labels using off-the-shelf foundation models, which are then re-projected to serve as patch-wise supervision. Second, to tackle the interference between task types, we categorize tasks into rotation-invariant (e.g., depth, segmentation) and rotation-variant (e.g., surface normals) groups. We introduce the Panoramic Dual BridgeNet, which disentangles these feature streams via geometry-aware modulation layers that inject absolute position and ray direction priors. To handle the distortion from equirectangular projections (ERP), we incorporate ERP token mixers followed by a dual-branch BridgeNet for interactions with gradient truncation, facilitating beneficial cross-task information sharing while blocking conflicting gradients from incompatible task attributes. Additionally, we introduce auxiliary tasks (image gradient, point map, etc.) to fertilize the cross-task learning process. Extensive experiments demonstrate that MTPano achieves state-of-the-art performance on multiple benchmarks and delivers competitive results against task-specific panoramic specialist foundation models.
UniSER: A Foundation Model for Unified Soft Effects Removal
Nov 18, 2025Digital images are often degraded by soft effects such as lens flare, haze, shadows, and reflections, which reduce aesthetics even though the underlying pixels remain partially visible. The prevailing works address these degradations in isolation, developing highly specialized, specialist models that lack scalability and fail to exploit the shared underlying essences of these restoration problems. While specialist models are limited, recent large-scale pretrained generalist models offer powerful, text-driven image editing capabilities. while recent general-purpose systems (e.g., GPT-4o, Flux Kontext, Nano Banana) require detailed prompts and often fail to achieve robust removal on these fine-grained tasks or preserve identity of the scene. Leveraging the common essence of soft effects, i.e., semi-transparent occlusions, we introduce a foundational versatile model UniSER, capable of addressing diverse degradations caused by soft effects within a single framework. Our methodology centers on curating a massive 3.8M-pair dataset to ensure robustness and generalization, which includes novel, physically-plausible data to fill critical gaps in public benchmarks, and a tailored training pipeline that fine-tunes a Diffusion Transformer to learn robust restoration priors from this diverse data, integrating fine-grained mask and strength controls. This synergistic approach allows UniSER to significantly outperform both specialist and generalist models, achieving robust, high-fidelity restoration in the wild.
SPGen: Spherical Projection as Consistent and Flexible Representation for Single Image 3D Shape Generation
Sep 16, 2025
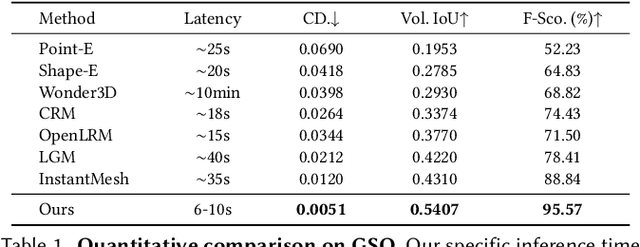
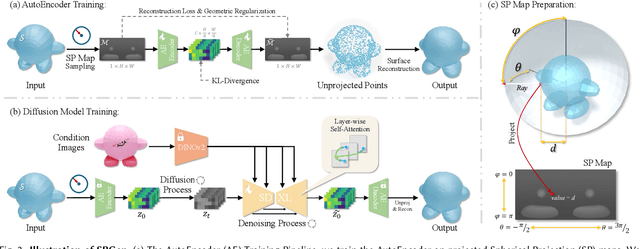
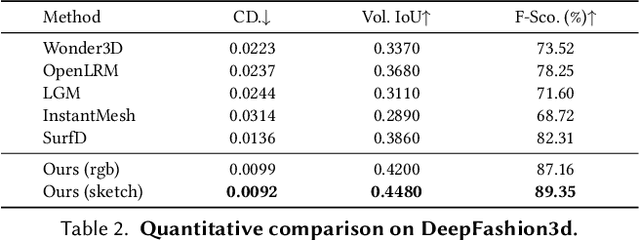
Existing single-view 3D generative models typically adopt multiview diffusion priors to reconstruct object surfaces, yet they remain prone to inter-view inconsistencies and are unable to faithfully represent complex internal structure or nontrivial topologies. In particular, we encode geometry information by projecting it onto a bounding sphere and unwrapping it into a compact and structural multi-layer 2D Spherical Projection (SP) representation. Operating solely in the image domain, SPGen offers three key advantages simultaneously: (1) Consistency. The injective SP mapping encodes surface geometry with a single viewpoint which naturally eliminates view inconsistency and ambiguity; (2) Flexibility. Multi-layer SP maps represent nested internal structures and support direct lifting to watertight or open 3D surfaces; (3) Efficiency. The image-domain formulation allows the direct inheritance of powerful 2D diffusion priors and enables efficient finetuning with limited computational resources. Extensive experiments demonstrate that SPGen significantly outperforms existing baselines in geometric quality and computational efficiency.
3R-GS: Best Practice in Optimizing Camera Poses Along with 3DGS
Apr 05, 20253D Gaussian Splatting (3DGS) has revolutionized neural rendering with its efficiency and quality, but like many novel view synthesis methods, it heavily depends on accurate camera poses from Structure-from-Motion (SfM) systems. Although recent SfM pipelines have made impressive progress, questions remain about how to further improve both their robust performance in challenging conditions (e.g., textureless scenes) and the precision of camera parameter estimation simultaneously. We present 3R-GS, a 3D Gaussian Splatting framework that bridges this gap by jointly optimizing 3D Gaussians and camera parameters from large reconstruction priors MASt3R-SfM. We note that naively performing joint 3D Gaussian and camera optimization faces two challenges: the sensitivity to the quality of SfM initialization, and its limited capacity for global optimization, leading to suboptimal reconstruction results. Our 3R-GS, overcomes these issues by incorporating optimized practices, enabling robust scene reconstruction even with imperfect camera registration. Extensive experiments demonstrate that 3R-GS delivers high-quality novel view synthesis and precise camera pose estimation while remaining computationally efficient. Project page: https://zsh523.github.io/3R-GS/
SolidGS: Consolidating Gaussian Surfel Splatting for Sparse-View Surface Reconstruction
Dec 19, 2024



Gaussian splatting has achieved impressive improvements for both novel-view synthesis and surface reconstruction from multi-view images. However, current methods still struggle to reconstruct high-quality surfaces from only sparse view input images using Gaussian splatting. In this paper, we propose a novel method called SolidGS to address this problem. We observed that the reconstructed geometry can be severely inconsistent across multi-views, due to the property of Gaussian function in geometry rendering. This motivates us to consolidate all Gaussians by adopting a more solid kernel function, which effectively improves the surface reconstruction quality. With the additional help of geometrical regularization and monocular normal estimation, our method achieves superior performance on the sparse view surface reconstruction than all the Gaussian splatting methods and neural field methods on the widely used DTU, Tanks-and-Temples, and LLFF datasets.
Multi-Task Label Discovery via Hierarchical Task Tokens for Partially Annotated Dense Predictions
Nov 27, 2024In recent years, simultaneous learning of multiple dense prediction tasks with partially annotated label data has emerged as an important research area. Previous works primarily focus on constructing cross-task consistency or conducting adversarial training to regularize cross-task predictions, which achieve promising performance improvements, while still suffering from the lack of direct pixel-wise supervision for multi-task dense predictions. To tackle this challenge, we propose a novel approach to optimize a set of learnable hierarchical task tokens, including global and fine-grained ones, to discover consistent pixel-wise supervision signals in both feature and prediction levels. Specifically, the global task tokens are designed for effective cross-task feature interactions in a global context. Then, a group of fine-grained task-specific spatial tokens for each task is learned from the corresponding global task tokens. It is embedded to have dense interactions with each task-specific feature map. The learned global and local fine-grained task tokens are further used to discover pseudo task-specific dense labels at different levels of granularity, and they can be utilized to directly supervise the learning of the multi-task dense prediction framework. Extensive experimental results on challenging NYUD-v2, Cityscapes, and PASCAL Context datasets demonstrate significant improvements over existing state-of-the-art methods for partially annotated multi-task dense prediction.
Governing equation discovery of a complex system from snapshots
Oct 22, 2024Complex systems in physics, chemistry, and biology that evolve over time with inherent randomness are typically described by stochastic differential equations (SDEs). A fundamental challenge in science and engineering is to determine the governing equations of a complex system from snapshot data. Traditional equation discovery methods often rely on stringent assumptions, such as the availability of the trajectory information or time-series data, and the presumption that the underlying system is deterministic. In this work, we introduce a data-driven, simulation-free framework, called Sparse Identification of Differential Equations from Snapshots (SpIDES), that discovers the governing equations of a complex system from snapshots by utilizing the advanced machine learning techniques to perform three essential steps: probability flow reconstruction, probability density estimation, and Bayesian sparse identification. We validate the effectiveness and robustness of SpIDES by successfully identifying the governing equation of an over-damped Langevin system confined within two potential wells. By extracting interpretable drift and diffusion terms from the SDEs, our framework provides deeper insights into system dynamics, enhances predictive accuracy, and facilitates more effective strategies for managing and simulating stochastic systems.
Learning Hamiltonian neural Koopman operator and simultaneously sustaining and discovering conservation law
Jun 04, 2024



Accurately finding and predicting dynamics based on the observational data with noise perturbations is of paramount significance but still a major challenge presently. Here, for the Hamiltonian mechanics, we propose the Hamiltonian Neural Koopman Operator (HNKO), integrating the knowledge of mathematical physics in learning the Koopman operator, and making it automatically sustain and even discover the conservation laws. We demonstrate the outperformance of the HNKO and its extension using a number of representative physical systems even with hundreds or thousands of freedoms. Our results suggest that feeding the prior knowledge of the underlying system and the mathematical theory appropriately to the learning framework can reinforce the capability of machine learning in solving physical problems.
From Fourier to Neural ODEs: Flow Matching for Modeling Complex Systems
May 23, 2024



Modeling complex systems using standard neural ordinary differential equations (NODEs) often faces some essential challenges, including high computational costs and susceptibility to local optima. To address these challenges, we propose a simulation-free framework, called Fourier NODEs (FNODEs), that effectively trains NODEs by directly matching the target vector field based on Fourier analysis. Specifically, we employ the Fourier analysis to estimate temporal and potential high-order spatial gradients from noisy observational data. We then incorporate the estimated spatial gradients as additional inputs to a neural network. Furthermore, we utilize the estimated temporal gradient as the optimization objective for the output of the neural network. Later, the trained neural network generates more data points through an ODE solver without participating in the computational graph, facilitating more accurate estimations of gradients based on Fourier analysis. These two steps form a positive feedback loop, enabling accurate dynamics modeling in our framework. Consequently, our approach outperforms state-of-the-art methods in terms of training time, dynamics prediction, and robustness. Finally, we demonstrate the superior performance of our framework using a number of representative complex systems.
Rethinking of Feature Interaction for Multi-task Learning on Dense Prediction
Dec 21, 2023



Existing works generally adopt the encoder-decoder structure for Multi-task Dense Prediction, where the encoder extracts the task-generic features, and multiple decoders generate task-specific features for predictions. We observe that low-level representations with rich details and high-level representations with abundant task information are not both involved in the multi-task interaction process. Additionally, low-quality and low-efficiency issues also exist in current multi-task learning architectures. In this work, we propose to learn a comprehensive intermediate feature globally from both task-generic and task-specific features, we reveal an important fact that this intermediate feature, namely the bridge feature, is a good solution to the above issues. Based on this, we propose a novel Bridge-Feature-Centirc Interaction (BRFI) method. A Bridge Feature Extractor (BFE) is designed for the generation of strong bridge features and Task Pattern Propagation (TPP) is applied to ensure high-quality task interaction participants. Then a Task-Feature Refiner (TFR) is developed to refine final task predictions with the well-learned knowledge from the bridge features. Extensive experiments are conducted on NYUD-v2 and PASCAL Context benchmarks, and the superior performance shows the proposed architecture is effective and powerful in promoting different dense prediction tasks simultaneously.