 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCameraVDP: Perceptual Display Assessment with Uncertainty Estimation via Camera and Visual Difference Prediction
Sep 10, 2025Accurate measurement of images produced by electronic displays is critical for the evaluation of both traditional and computational displays. Traditional display measurement methods based on sparse radiometric sampling and fitting a model are inadequate for capturing spatially varying display artifacts, as they fail to capture high-frequency and pixel-level distortions. While cameras offer sufficient spatial resolution, they introduce optical, sampling, and photometric distortions. Furthermore, the physical measurement must be combined with a model of a visual system to assess whether the distortions are going to be visible. To enable perceptual assessment of displays, we propose a combination of a camera-based reconstruction pipeline with a visual difference predictor, which account for both the inaccuracy of camera measurements and visual difference prediction. The reconstruction pipeline combines HDR image stacking, MTF inversion, vignetting correction, geometric undistortion, homography transformation, and color correction, enabling cameras to function as precise display measurement instruments. By incorporating a Visual Difference Predictor (VDP), our system models the visibility of various stimuli under different viewing conditions for the human visual system. We validate the proposed CameraVDP framework through three applications: defective pixel detection, color fringing awareness, and display non-uniformity evaluation. Our uncertainty analysis framework enables the estimation of the theoretical upper bound for defect pixel detection performance and provides confidence intervals for VDP quality scores.
elaTCSF: A Temporal Contrast Sensitivity Function for Flicker Detection and Modeling Variable Refresh Rate Flicker
Mar 21, 2025

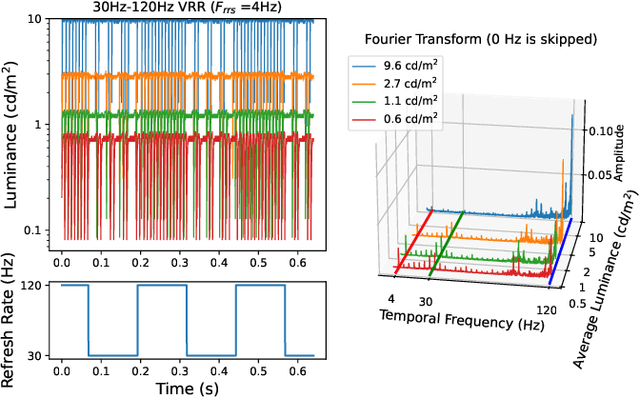

The perception of flicker has been a prominent concern in illumination and electronic display fields for over a century. Traditional approaches often rely on Critical Flicker Frequency (CFF), primarily suited for high-contrast (full-on, full-off) flicker. To tackle varying contrast flicker, the International Committee for Display Metrology (ICDM) introduced a Temporal Contrast Sensitivity Function TCSF$_{IDMS}$ within the Information Display Measurements Standard (IDMS). Nevertheless, this standard overlooks crucial parameters: luminance, eccentricity, and area. Existing models incorporating these parameters are inadequate for flicker detection, especially at low spatial frequencies. To address these limitations, we extend the TCSF$_{IDMS}$ and combine it with a new spatial probability summation model to incorporate the effects of luminance, eccentricity, and area (elaTCSF). We train the elaTCSF on various flicker detection datasets and establish the first variable refresh rate flicker detection dataset for further verification. Additionally, we contribute to resolving a longstanding debate on whether the flicker is more visible in peripheral vision. We demonstrate how elaTCSF can be used to predict flicker due to low-persistence in VR headsets, identify flicker-free VRR operational ranges, and determine flicker sensitivity in lighting design.
Do image and video quality metrics model low-level human vision?
Mar 20, 2025Image and video quality metrics, such as SSIM, LPIPS, and VMAF, are aimed to predict the perceived quality of the evaluated content and are often claimed to be "perceptual". Yet, few metrics directly model human visual perception, and most rely on hand-crafted formulas or training datasets to achieve alignment with perceptual data. In this paper, we propose a set of tests for full-reference quality metrics that examine their ability to model several aspects of low-level human vision: contrast sensitivity, contrast masking, and contrast matching. The tests are meant to provide additional scrutiny for newly proposed metrics. We use our tests to analyze 33 existing image and video quality metrics and find their strengths and weaknesses, such as the ability of LPIPS and MS-SSIM to predict contrast masking and poor performance of VMAF in this task. We further find that the popular SSIM metric overemphasizes differences in high spatial frequencies, but its multi-scale counterpart, MS-SSIM, addresses this shortcoming. Such findings cannot be easily made using existing evaluation protocols.
Do computer vision foundation models learn the low-level characteristics of the human visual system?
Feb 27, 2025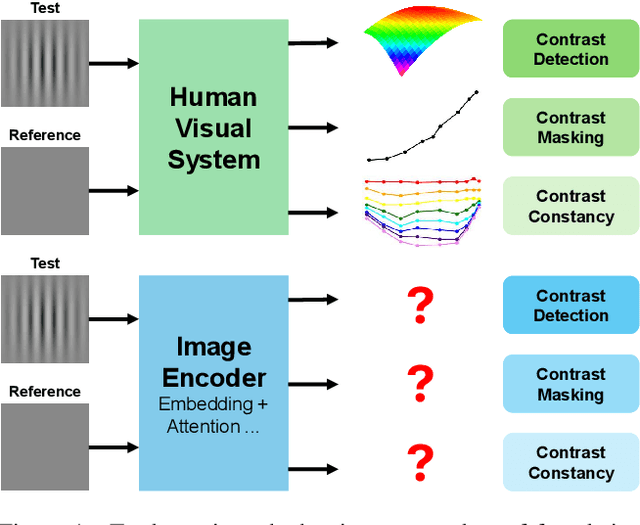
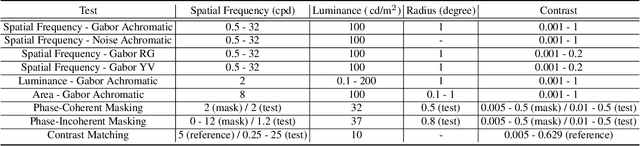
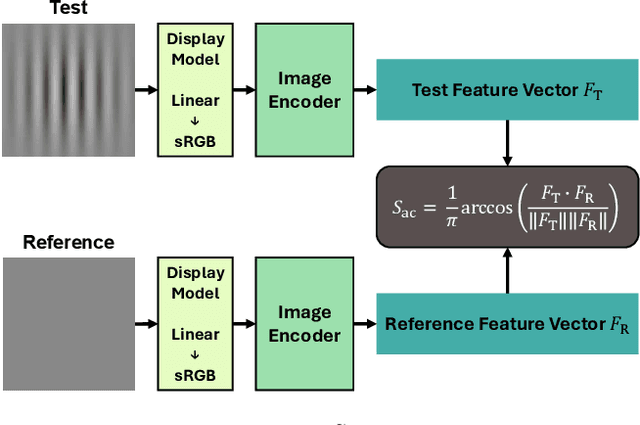
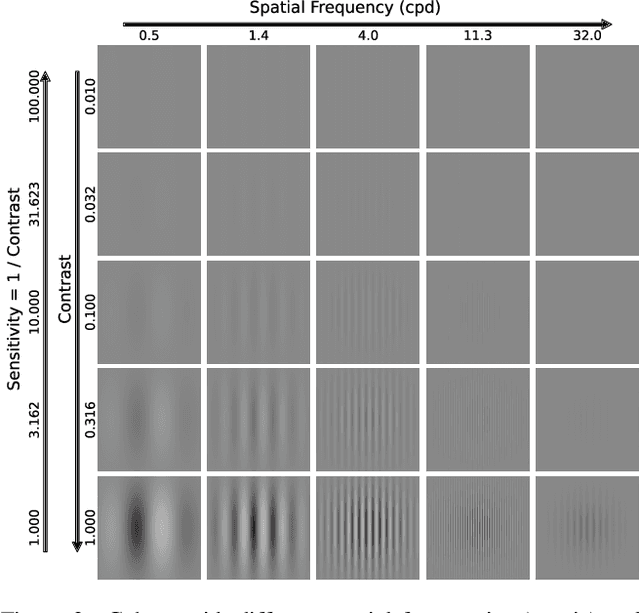
Computer vision foundation models, such as DINO or OpenCLIP, are trained in a self-supervised manner on large image datasets. Analogously, substantial evidence suggests that the human visual system (HVS) is influenced by the statistical distribution of colors and patterns in the natural world, characteristics also present in the training data of foundation models. The question we address in this paper is whether foundation models trained on natural images mimic some of the low-level characteristics of the human visual system, such as contrast detection, contrast masking, and contrast constancy. Specifically, we designed a protocol comprising nine test types to evaluate the image encoders of 45 foundation and generative models. Our results indicate that some foundation models (e.g., DINO, DINOv2, and OpenCLIP), share some of the characteristics of human vision, but other models show little resemblance. Foundation models tend to show smaller sensitivity to low contrast and rather irregular responses to contrast across frequencies. The foundation models show the best agreement with human data in terms of contrast masking. Our findings suggest that human vision and computer vision may take both similar and different paths when learning to interpret images of the real world. Overall, while differences remain, foundation models trained on vision tasks start to align with low-level human vision, with DINOv2 showing the closest resemblance.
Rethinking of Feature Interaction for Multi-task Learning on Dense Prediction
Dec 21, 2023



Existing works generally adopt the encoder-decoder structure for Multi-task Dense Prediction, where the encoder extracts the task-generic features, and multiple decoders generate task-specific features for predictions. We observe that low-level representations with rich details and high-level representations with abundant task information are not both involved in the multi-task interaction process. Additionally, low-quality and low-efficiency issues also exist in current multi-task learning architectures. In this work, we propose to learn a comprehensive intermediate feature globally from both task-generic and task-specific features, we reveal an important fact that this intermediate feature, namely the bridge feature, is a good solution to the above issues. Based on this, we propose a novel Bridge-Feature-Centirc Interaction (BRFI) method. A Bridge Feature Extractor (BFE) is designed for the generation of strong bridge features and Task Pattern Propagation (TPP) is applied to ensure high-quality task interaction participants. Then a Task-Feature Refiner (TFR) is developed to refine final task predictions with the well-learned knowledge from the bridge features. Extensive experiments are conducted on NYUD-v2 and PASCAL Context benchmarks, and the superior performance shows the proposed architecture is effective and powerful in promoting different dense prediction tasks simultaneously.
Rethinking Cross-Domain Pedestrian Detection: A Background-Focused Distribution Alignment Framework for Instance-Free One-Stage Detectors
Sep 15, 2023



Cross-domain pedestrian detection aims to generalize pedestrian detectors from one label-rich domain to another label-scarce domain, which is crucial for various real-world applications. Most recent works focus on domain alignment to train domain-adaptive detectors either at the instance level or image level. From a practical point of view, one-stage detectors are faster. Therefore, we concentrate on designing a cross-domain algorithm for rapid one-stage detectors that lacks instance-level proposals and can only perform image-level feature alignment. However, pure image-level feature alignment causes the foreground-background misalignment issue to arise, i.e., the foreground features in the source domain image are falsely aligned with background features in the target domain image. To address this issue, we systematically analyze the importance of foreground and background in image-level cross-domain alignment, and learn that background plays a more critical role in image-level cross-domain alignment. Therefore, we focus on cross-domain background feature alignment while minimizing the influence of foreground features on the cross-domain alignment stage. This paper proposes a novel framework, namely, background-focused distribution alignment (BFDA), to train domain adaptive onestage pedestrian detectors. Specifically, BFDA first decouples the background features from the whole image feature maps and then aligns them via a novel long-short-range discriminator.
* This paper published on IEEE Transactions on Image Processing on August 2023.See https://ieeexplore.ieee.org/document/10231122
Multi-Object Manipulation via Object-Centric Neural Scattering Functions
Jun 14, 2023Learned visual dynamics models have proven effective for robotic manipulation tasks. Yet, it remains unclear how best to represent scenes involving multi-object interactions. Current methods decompose a scene into discrete objects, but they struggle with precise modeling and manipulation amid challenging lighting conditions as they only encode appearance tied with specific illuminations. In this work, we propose using object-centric neural scattering functions (OSFs) as object representations in a model-predictive control framework. OSFs model per-object light transport, enabling compositional scene re-rendering under object rearrangement and varying lighting conditions. By combining this approach with inverse parameter estimation and graph-based neural dynamics models, we demonstrate improved model-predictive control performance and generalization in compositional multi-object environments, even in previously unseen scenarios and harsh lighting conditions.