 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerMatch: Do Pseudo-labels Benefit All Layers?
Jun 20, 2024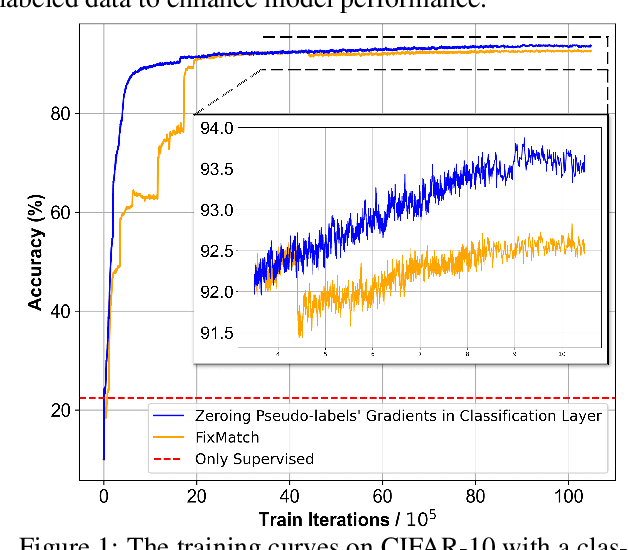
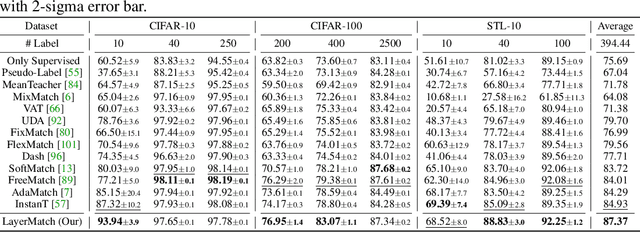
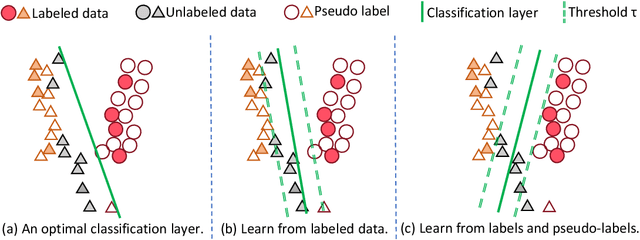
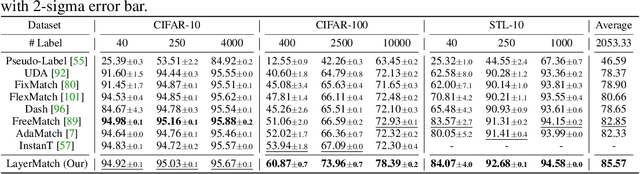
Deep neural networks have achieved remarkable performance across various tasks when supplied with large-scale labeled data. However, the collection of labeled data can be time-consuming and labor-intensive. Semi-supervised learning (SSL), particularly through pseudo-labeling algorithms that iteratively assign pseudo-labels for self-training, offers a promising solution to mitigate the dependency of labeled data. Previous research generally applies a uniform pseudo-labeling strategy across all model layers, assuming that pseudo-labels exert uniform influence throughout. Contrasting this, our theoretical analysis and empirical experiment demonstrate feature extraction layer and linear classification layer have distinct learning behaviors in response to pseudo-labels. Based on these insights, we develop two layer-specific pseudo-label strategies, termed Grad-ReLU and Avg-Clustering. Grad-ReLU mitigates the impact of noisy pseudo-labels by removing the gradient detrimental effects of pseudo-labels in the linear classification layer. Avg-Clustering accelerates the convergence of feature extraction layer towards stable clustering centers by integrating consistent outputs. Our approach, LayerMatch, which integrates these two strategies, can avoid the severe interference of noisy pseudo-labels in the linear classification layer while accelerating the clustering capability of the feature extraction layer. Through extensive experimentation, our approach consistently demonstrates exceptional performance on standard semi-supervised learning benchmarks, achieving a significant improvement of 10.38% over baseline method and a 2.44% increase compared to state-of-the-art methods.
BEACON: Benchmark for Comprehensive RNA Tasks and Language Models
Jun 14, 2024RNA plays a pivotal role in translating genetic instructions into functional outcomes, underscoring its importance in biological processes and disease mechanisms. Despite the emergence of numerous deep learning approaches for RNA, particularly universal RNA language models, there remains a significant lack of standardized benchmarks to assess the effectiveness of these methods. In this study, we introduce the first comprehensive RNA benchmark BEACON (\textbf{BE}nchm\textbf{A}rk for \textbf{CO}mprehensive R\textbf{N}A Task and Language Models). First, BEACON comprises 13 distinct tasks derived from extensive previous work covering structural analysis, functional studies, and engineering applications, enabling a comprehensive assessment of the performance of methods on various RNA understanding tasks. Second, we examine a range of models, including traditional approaches like CNNs, as well as advanced RNA foundation models based on language models, offering valuable insights into the task-specific performances of these models. Third, we investigate the vital RNA language model components from the tokenizer and positional encoding aspects. Notably, our findings emphasize the superiority of single nucleotide tokenization and the effectiveness of Attention with Linear Biases (ALiBi) over traditional positional encoding methods. Based on these insights, a simple yet strong baseline called BEACON-B is proposed, which can achieve outstanding performance with limited data and computational resources. The datasets and source code of our benchmark are available at https://github.com/terry-r123/RNABenchmark.
Rethinking the BERT-like Pretraining for DNA Sequences
Oct 12, 2023With the success of large-scale pretraining in NLP, there is an increasing trend of applying it to the domain of life sciences. In particular, pretraining methods based on DNA sequences have garnered growing attention due to their potential to capture generic information about genes. However, existing pretraining methods for DNA sequences largely rely on direct adoptions of BERT pretraining from NLP, lacking a comprehensive understanding and a specifically tailored approach. To address this research gap, we first conducted a series of exploratory experiments and gained several insightful observations: 1) In the fine-tuning phase of downstream tasks, when using K-mer overlapping tokenization instead of K-mer non-overlapping tokenization, both overlapping and non-overlapping pretraining weights show consistent performance improvement.2) During the pre-training process, using K-mer overlapping tokenization quickly produces clear K-mer embeddings and reduces the loss to a very low level, while using K-mer non-overlapping tokenization results in less distinct embeddings and continuously decreases the loss. 3) Using overlapping tokenization causes the self-attention in the intermediate layers of pre-trained models to tend to overly focus on certain tokens, reflecting that these layers are not adequately optimized. In summary, overlapping tokenization can benefit the fine-tuning of downstream tasks but leads to inadequate pretraining with fast convergence. To unleash the pretraining potential, we introduce a novel approach called RandomMask, which gradually increases the task difficulty of BERT-like pretraining by continuously expanding its mask boundary, forcing the model to learn more knowledge. RandomMask is simple but effective, achieving top-tier performance across 26 datasets of 28 datasets spanning 7 downstream tasks.
Rethinking Cross-Domain Pedestrian Detection: A Background-Focused Distribution Alignment Framework for Instance-Free One-Stage Detectors
Sep 15, 2023



Cross-domain pedestrian detection aims to generalize pedestrian detectors from one label-rich domain to another label-scarce domain, which is crucial for various real-world applications. Most recent works focus on domain alignment to train domain-adaptive detectors either at the instance level or image level. From a practical point of view, one-stage detectors are faster. Therefore, we concentrate on designing a cross-domain algorithm for rapid one-stage detectors that lacks instance-level proposals and can only perform image-level feature alignment. However, pure image-level feature alignment causes the foreground-background misalignment issue to arise, i.e., the foreground features in the source domain image are falsely aligned with background features in the target domain image. To address this issue, we systematically analyze the importance of foreground and background in image-level cross-domain alignment, and learn that background plays a more critical role in image-level cross-domain alignment. Therefore, we focus on cross-domain background feature alignment while minimizing the influence of foreground features on the cross-domain alignment stage. This paper proposes a novel framework, namely, background-focused distribution alignment (BFDA), to train domain adaptive onestage pedestrian detectors. Specifically, BFDA first decouples the background features from the whole image feature maps and then aligns them via a novel long-short-range discriminator.
* This paper published on IEEE Transactions on Image Processing on August 2023.See https://ieeexplore.ieee.org/document/10231122
Mind the Class Weight Bias: Weighted Maximum Mean Discrepancy for Unsupervised Domain Adaptation
May 01, 2017
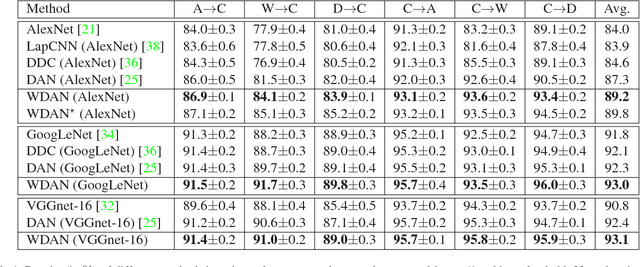


In domain adaptation, maximum mean discrepancy (MMD) has been widely adopted as a discrepancy metric between the distributions of source and target domains. However, existing MMD-based domain adaptation methods generally ignore the changes of class prior distributions, i.e., class weight bias across domains. This remains an open problem but ubiquitous for domain adaptation, which can be caused by changes in sample selection criteria and application scenarios. We show that MMD cannot account for class weight bias and results in degraded domain adaptation performance. To address this issue, a weighted MMD model is proposed in this paper. Specifically, we introduce class-specific auxiliary weights into the original MMD for exploiting the class prior probability on source and target domains, whose challenge lies in the fact that the class label in target domain is unavailable. To account for it, our proposed weighted MMD model is defined by introducing an auxiliary weight for each class in the source domain, and a classification EM algorithm is suggested by alternating between assigning the pseudo-labels, estimating auxiliary weights and updating model parameters. Extensive experiments demonstrate the superiority of our weighted MMD over conventional MMD for domain adaptation.