 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Specific Distance Correlation Matching for Few-Shot Action Recognition
Dec 15, 2025Few-shot action recognition (FSAR) has recently made notable progress through set matching and efficient adaptation of large-scale pre-trained models. However, two key limitations persist. First, existing set matching metrics typically rely on cosine similarity to measure inter-frame linear dependencies and then perform matching with only instance-level information, thus failing to capture more complex patterns such as nonlinear relationships and overlooking task-specific cues. Second, for efficient adaptation of CLIP to FSAR, recent work performing fine-tuning via skip-fusion layers (which we refer to as side layers) has significantly reduced memory cost. However, the newly introduced side layers are often difficult to optimize under limited data conditions. To address these limitations, we propose TS-FSAR, a framework comprising three components: (1) a visual Ladder Side Network (LSN) for efficient CLIP fine-tuning; (2) a metric called Task-Specific Distance Correlation Matching (TS-DCM), which uses $α$-distance correlation to model both linear and nonlinear inter-frame dependencies and leverages a task prototype to enable task-specific matching; and (3) a Guiding LSN with Adapted CLIP (GLAC) module, which regularizes LSN using the adapted frozen CLIP to improve training for better $α$-distance correlation estimation under limited supervision. Extensive experiments on five widely-used benchmarks demonstrate that our TS-FSAR yields superior performance compared to prior state-of-the-arts.
DALIP: Distribution Alignment-based Language-Image Pre-Training for Domain-Specific Data
Apr 02, 2025Recently, Contrastive Language-Image Pre-training (CLIP) has shown promising performance in domain-specific data (e.g., biology), and has attracted increasing research attention. Existing works generally focus on collecting extensive domain-specific data and directly tuning the original CLIP models. Intuitively, such a paradigm takes no full consideration of the characteristics lying in domain-specific data (e.g., fine-grained nature of biological data) and so limits model capability, while mostly losing the original ability of CLIP in the general domain. In this paper, we propose a Distribution Alignment-based Language-Image Pre-Training (DALIP) method for biological data. Specifically, DALIP optimizes CLIP models by matching the similarity between feature distribution of image-text pairs instead of the original [cls] token, which can capture rich yet effective information inherent in image-text pairs as powerful representations, and so better cope with fine-grained nature of biological data. Particularly, our DALIP efficiently approximates feature distribution via its first- and second-order statistics, while presenting a Multi-head Brownian Distance Covariance (MBDC) module to acquire second-order statistics of token features efficiently. Furthermore, we collect a new dataset for plant domain (e.g., specific data in biological domain) comprising 10M plant data with 3M general-domain data (namely PlantMix-13M) according to data mixing laws. Extensive experiments show that DALIP clearly outperforms existing CLIP counterparts in biological domain, while well generalizing to remote sensing and medical imaging domains. Besides, our PlantMix-13M dataset further boosts performance of DALIP in plant domain, while preserving model ability in general domain.
Wasserstein Distance Rivals Kullback-Leibler Divergence for Knowledge Distillation
Dec 11, 2024



Since pioneering work of Hinton et al., knowledge distillation based on Kullback-Leibler Divergence (KL-Div) has been predominant, and recently its variants have achieved compelling performance. However, KL-Div only compares probabilities of the corresponding category between the teacher and student while lacking a mechanism for cross-category comparison. Besides, KL-Div is problematic when applied to intermediate layers, as it cannot handle non-overlapping distributions and is unaware of geometry of the underlying manifold. To address these downsides, we propose a methodology of Wasserstein Distance (WD) based knowledge distillation. Specifically, we propose a logit distillation method called WKD-L based on discrete WD, which performs cross-category comparison of probabilities and thus can explicitly leverage rich interrelations among categories. Moreover, we introduce a feature distillation method called WKD-F, which uses a parametric method for modeling feature distributions and adopts continuous WD for transferring knowledge from intermediate layers. Comprehensive evaluations on image classification and object detection have shown (1) for logit distillation WKD-L outperforms very strong KL-Div variants; (2) for feature distillation WKD-F is superior to the KL-Div counterparts and state-of-the-art competitors. The source code is available at https://peihuali.org/WKD
TAMT: Temporal-Aware Model Tuning for Cross-Domain Few-Shot Action Recognition
Nov 28, 2024



Going beyond few-shot action recognition (FSAR), cross-domain FSAR (CDFSAR) has attracted recent research interests by solving the domain gap lying in source-to-target transfer learning. Existing CDFSAR methods mainly focus on joint training of source and target data to mitigate the side effect of domain gap. However, such kind of methods suffer from two limitations: First, pair-wise joint training requires retraining deep models in case of one source data and multiple target ones, which incurs heavy computation cost, especially for large source and small target data. Second, pre-trained models after joint training are adopted to target domain in a straightforward manner, hardly taking full potential of pre-trained models and then limiting recognition performance. To overcome above limitations, this paper proposes a simple yet effective baseline, namely Temporal-Aware Model Tuning (TAMT) for CDFSAR. Specifically, our TAMT involves a decoupled paradigm by performing pre-training on source data and fine-tuning target data, which avoids retraining for multiple target data with single source. To effectively and efficiently explore the potential of pre-trained models in transferring to target domain, our TAMT proposes a Hierarchical Temporal Tuning Network (HTTN), whose core involves local temporal-aware adapters (TAA) and a global temporal-aware moment tuning (GTMT). Particularly, TAA learns few parameters to recalibrate the intermediate features of frozen pre-trained models, enabling efficient adaptation to target domains. Furthermore, GTMT helps to generate powerful video representations, improving match performance on the target domain. Experiments on several widely used video benchmarks show our TAMT outperforms the recently proposed counterparts by 13%$\sim$31%, achieving new state-of-the-art CDFSAR results.
Joint Distribution Matters: Deep Brownian Distance Covariance for Few-Shot Classification
Apr 09, 2022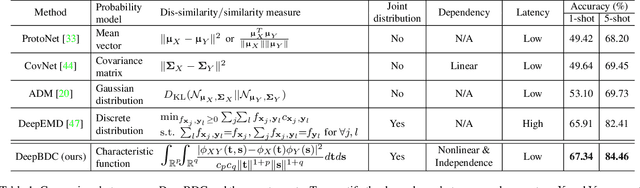
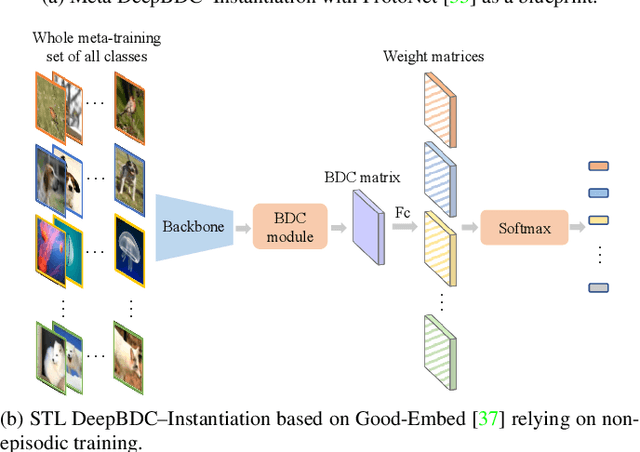
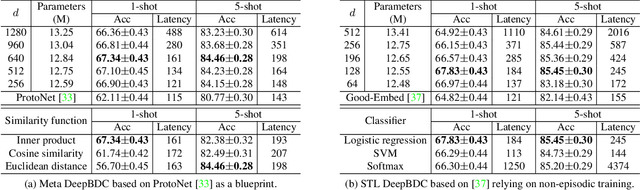
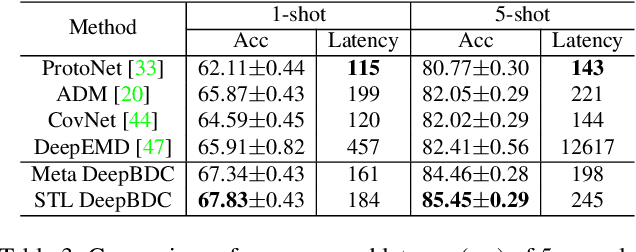
Few-shot classification is a challenging problem as only very few training examples are given for each new task. One of the effective research lines to address this challenge focuses on learning deep representations driven by a similarity measure between a query image and few support images of some class. Statistically, this amounts to measure the dependency of image features, viewed as random vectors in a high-dimensional embedding space. Previous methods either only use marginal distributions without considering joint distributions, suffering from limited representation capability, or are computationally expensive though harnessing joint distributions. In this paper, we propose a deep Brownian Distance Covariance (DeepBDC) method for few-shot classification. The central idea of DeepBDC is to learn image representations by measuring the discrepancy between joint characteristic functions of embedded features and product of the marginals. As the BDC metric is decoupled, we formulate it as a highly modular and efficient layer. Furthermore, we instantiate DeepBDC in two different few-shot classification frameworks. We make experiments on six standard few-shot image benchmarks, covering general object recognition, fine-grained categorization and cross-domain classification. Extensive evaluations show our DeepBDC significantly outperforms the counterparts, while establishing new state-of-the-art results. The source code is available at http://www.peihuali.org/DeepBDC
Temporal-attentive Covariance Pooling Networks for Video Recognition
Nov 06, 2021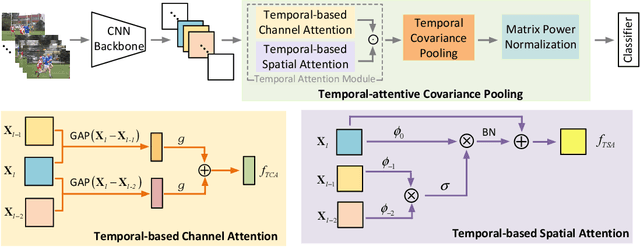

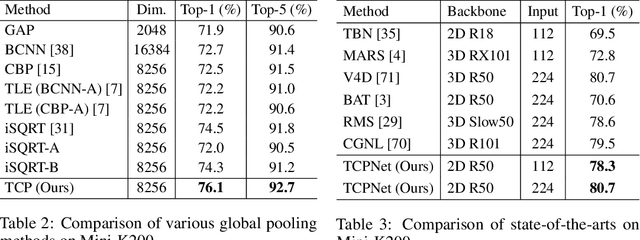
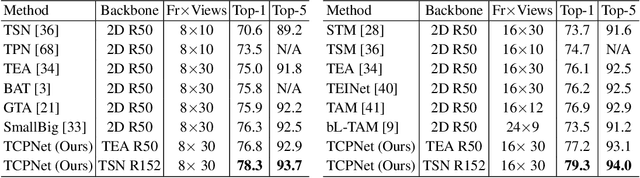
For video recognition task, a global representation summarizing the whole contents of the video snippets plays an important role for the final performance. However, existing video architectures usually generate it by using a simple, global average pooling (GAP) method, which has limited ability to capture complex dynamics of videos. For image recognition task, there exist evidences showing that covariance pooling has stronger representation ability than GAP. Unfortunately, such plain covariance pooling used in image recognition is an orderless representative, which cannot model spatio-temporal structure inherent in videos. Therefore, this paper proposes a Temporal-attentive Covariance Pooling(TCP), inserted at the end of deep architectures, to produce powerful video representations. Specifically, our TCP first develops a temporal attention module to adaptively calibrate spatio-temporal features for the succeeding covariance pooling, approximatively producing attentive covariance representations. Then, a temporal covariance pooling performs temporal pooling of the attentive covariance representations to characterize both intra-frame correlations and inter-frame cross-correlations of the calibrated features. As such, the proposed TCP can capture complex temporal dynamics. Finally, a fast matrix power normalization is introduced to exploit geometry of covariance representations. Note that our TCP is model-agnostic and can be flexibly integrated into any video architectures, resulting in TCPNet for effective video recognition. The extensive experiments on six benchmarks (e.g., Kinetics, Something-Something V1 and Charades) using various video architectures show our TCPNet is clearly superior to its counterparts, while having strong generalization ability. The source code is publicly available.
So-ViT: Mind Visual Tokens for Vision Transformer
Apr 22, 2021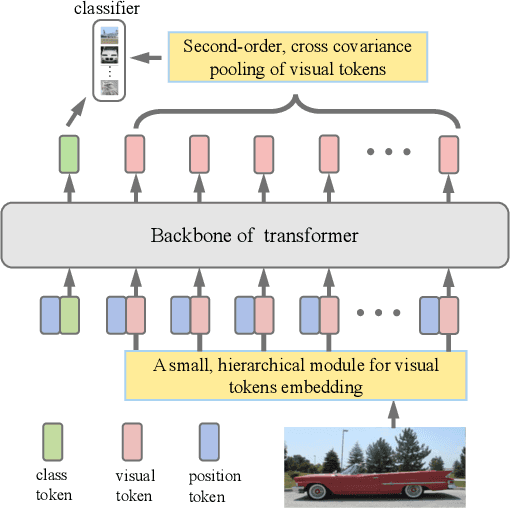

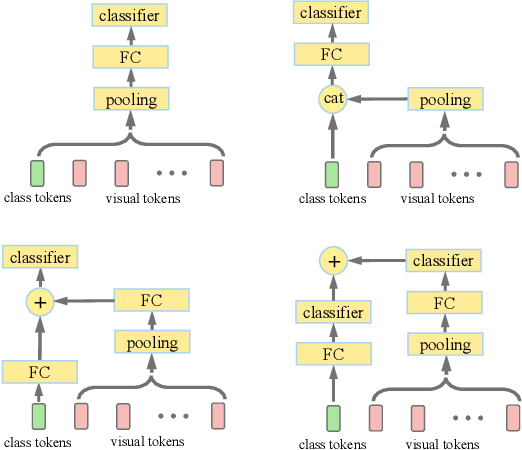
Recently the vision transformer (ViT) architecture, where the backbone purely consists of self-attention mechanism, has achieved very promising performance in visual classification. However, the high performance of the original ViT heavily depends on pretraining using ultra large-scale datasets, and it significantly underperforms on ImageNet-1K if trained from scratch. This paper makes the efforts toward addressing this problem, by carefully considering the role of visual tokens. First, for classification head, existing ViT only exploits class token while entirely neglecting rich semantic information inherent in high-level visual tokens. Therefore, we propose a new classification paradigm, where the second-order, cross-covariance pooling of visual tokens is combined with class token for final classification. Meanwhile, a fast singular value power normalization is proposed for improving the second-order pooling. Second, the original ViT employs the naive embedding of fixed-size image patches, lacking the ability to model translation equivariance and locality. To alleviate this problem, we develop a light-weight, hierarchical module based on off-the-shelf convolutions for visual token embedding. The proposed architecture, which we call So-ViT, is thoroughly evaluated on ImageNet-1K. The results show our models, when trained from scratch, outperform the competing ViT variants, while being on par with or better than state-of-the-art CNN models. Code is available at https://github.com/jiangtaoxie/So-ViT
What Deep CNNs Benefit from Global Covariance Pooling: An Optimization Perspective
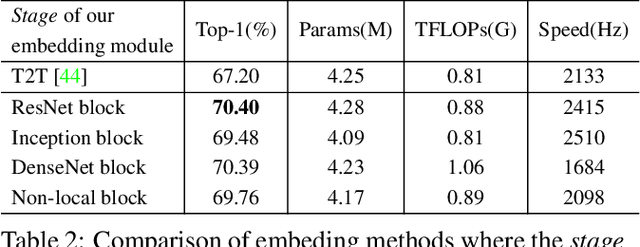
Mar 25, 2020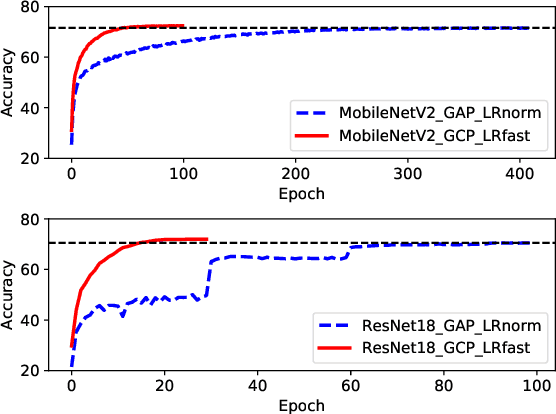
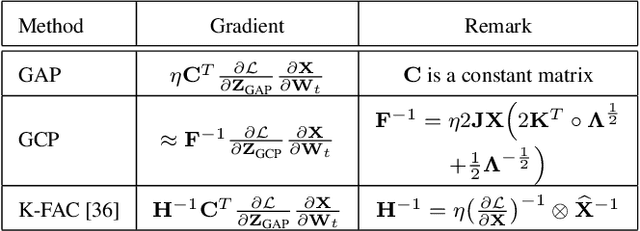
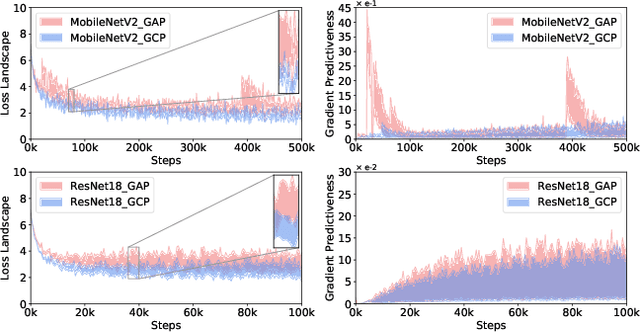
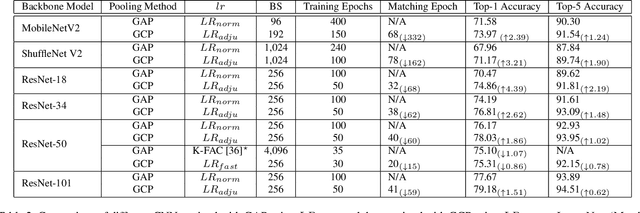
Recent works have demonstrated that global covariance pooling (GCP) has the ability to improve performance of deep convolutional neural networks (CNNs) on visual classification task. Despite considerable advance, the reasons on effectiveness of GCP on deep CNNs have not been well studied. In this paper, we make an attempt to understand what deep CNNs benefit from GCP in a viewpoint of optimization. Specifically, we explore the effect of GCP on deep CNNs in terms of the Lipschitzness of optimization loss and the predictiveness of gradients, and show that GCP can make the optimization landscape more smooth and the gradients more predictive. Furthermore, we discuss the connection between GCP and second-order optimization for deep CNNs. More importantly, above findings can account for several merits of covariance pooling for training deep CNNs that have not been recognized previously or fully explored, including significant acceleration of network convergence (i.e., the networks trained with GCP can support rapid decay of learning rates, achieving favorable performance while significantly reducing number of training epochs), stronger robustness to distorted examples generated by image corruptions and perturbations, and good generalization ability to different vision tasks, e.g., object detection and instance segmentation. We conduct extensive experiments using various deep CNN models on diversified tasks, and the results provide strong support to our findings.
ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
Oct 08, 2019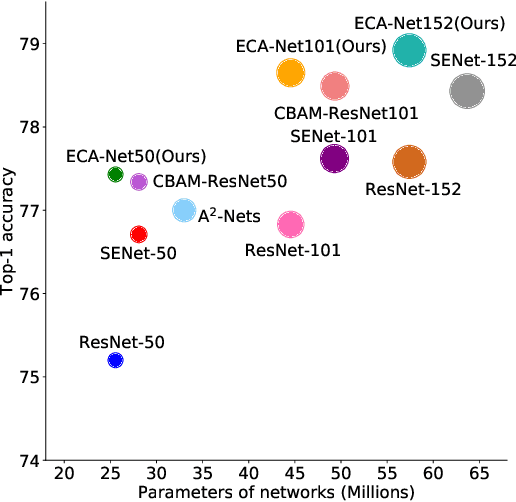
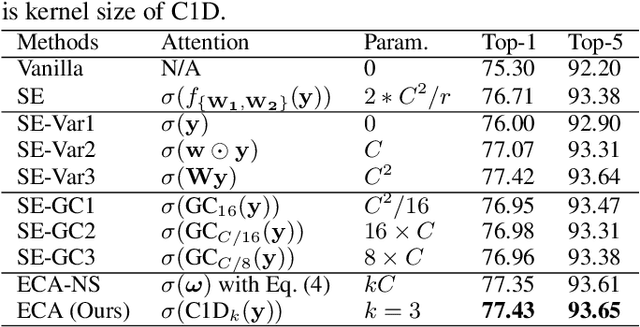
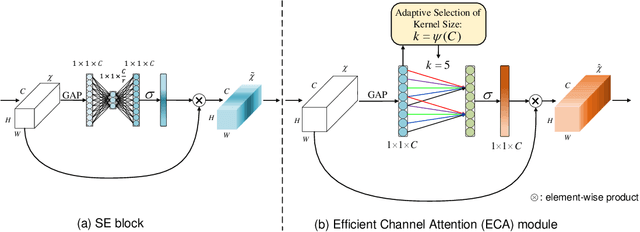
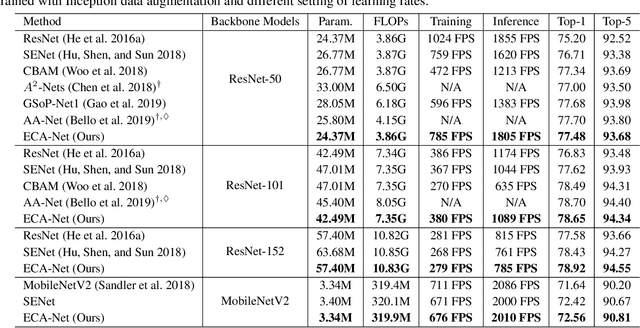
Channel attention has recently demonstrated to offer great potential in improving the performance of deep convolutional neural networks (CNNs). However, most existing methods dedicate to developing more sophisticated attention modules to achieve better performance, inevitably increasing the computational burden. To overcome the paradox of performance and complexity trade-off, this paper makes an attempt to investigate an extremely lightweight attention module for boosting the performance of deep CNNs. In particular, we propose an Efficient Channel Attention (ECA) module, which only involves $k (k < 9)$ parameters but brings clear performance gain. By revisiting the channel attention module in SENet, we empirically show avoiding dimensionality reduction and appropriate cross-channel interaction are important to learn effective channel attention. Therefore, we propose a local cross-channel interaction strategy without dimension reduction, which can be efficiently implemented by a fast 1D convolution. Furthermore, we develop a function of channel dimension to adaptively determine kernel size of 1D convolution, which stands for coverage of local cross-channel interaction. Our ECA module can be flexibly incorporated into existing CNN architectures, and the resulting CNNs are named by ECA-Net. We extensively evaluate the proposed ECA-Net on image classification, object detection and instance segmentation with backbones of ResNets and MobileNetV2. The experimental results show our ECA-Net is more efficient while performing favorably against its counterparts. The source code and models can be available at https://github.com/BangguWu/ECANet.
Deep CNNs Meet Global Covariance Pooling: Better Representation and Generalization
Apr 15, 2019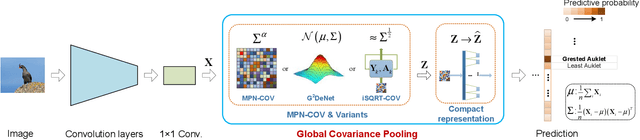

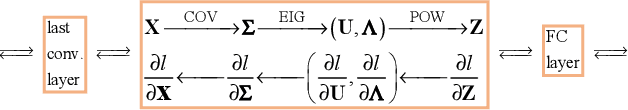

Compared with global average pooling in existing deep convolutional neural networks (CNNs), global covariance pooling can capture richer statistics of deep features, having potential for improving representation and generalization abilities of deep CNNs. However, integration of global covariance pooling into deep CNNs brings two challenges: (1) robust covariance estimation given deep features of high dimension and small sample; (2) appropriate use of geometry of covariances. To address these challenges, we propose a global Matrix Power Normalized COVariance (MPN-COV) Pooling. Our MPN-COV conforms to a robust covariance estimator, very suitable for scenario of high dimension and small sample. It can also be regarded as power-Euclidean metric between covariances, effectively exploiting their geometry. Furthermore, a global Gaussian embedding method is proposed to incorporate first-order statistics into MPN-COV. For fast training of MPN-COV networks, we propose an iterative matrix square root normalization, avoiding GPU unfriendly eigen-decomposition inherent in MPN-COV. Additionally, progressive 1x1 and group convolutions are introduced to compact covariance representations. The MPN-COV and its variants are highly modular, readily plugged into existing deep CNNs. Extensive experiments are conducted on large-scale object classification, scene categorization, fine-grained visual recognition and texture classification, showing our methods are superior to the counterparts and achieve state-of-the-art performance.