 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSo-ViT: Mind Visual Tokens for Vision Transformer
Paper and Code
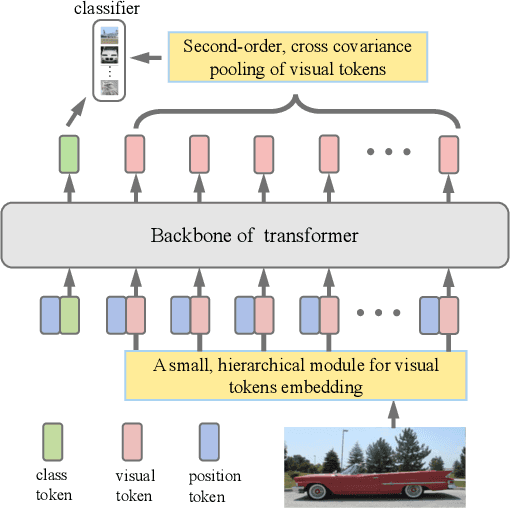

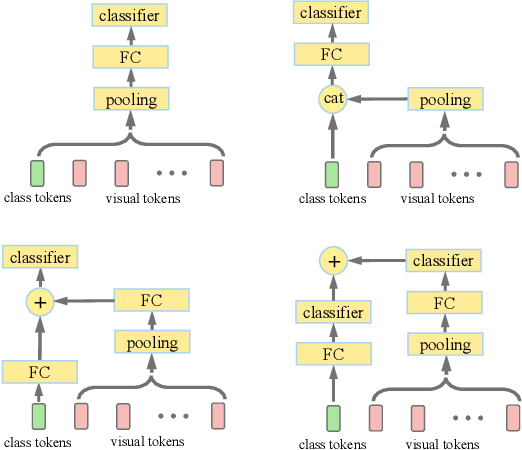
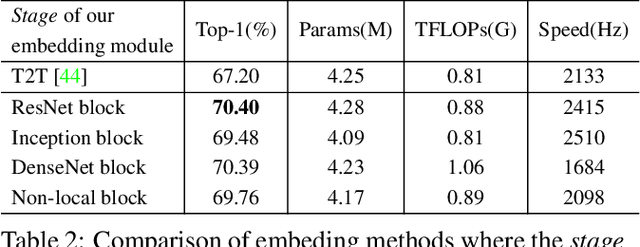
Recently the vision transformer (ViT) architecture, where the backbone purely consists of self-attention mechanism, has achieved very promising performance in visual classification. However, the high performance of the original ViT heavily depends on pretraining using ultra large-scale datasets, and it significantly underperforms on ImageNet-1K if trained from scratch. This paper makes the efforts toward addressing this problem, by carefully considering the role of visual tokens. First, for classification head, existing ViT only exploits class token while entirely neglecting rich semantic information inherent in high-level visual tokens. Therefore, we propose a new classification paradigm, where the second-order, cross-covariance pooling of visual tokens is combined with class token for final classification. Meanwhile, a fast singular value power normalization is proposed for improving the second-order pooling. Second, the original ViT employs the naive embedding of fixed-size image patches, lacking the ability to model translation equivariance and locality. To alleviate this problem, we develop a light-weight, hierarchical module based on off-the-shelf convolutions for visual token embedding. The proposed architecture, which we call So-ViT, is thoroughly evaluated on ImageNet-1K. The results show our models, when trained from scratch, outperform the competing ViT variants, while being on par with or better than state-of-the-art CNN models. Code is available at https://github.com/jiangtaoxie/So-ViT