 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Specific Distance Correlation Matching for Few-Shot Action Recognition
Dec 15, 2025Few-shot action recognition (FSAR) has recently made notable progress through set matching and efficient adaptation of large-scale pre-trained models. However, two key limitations persist. First, existing set matching metrics typically rely on cosine similarity to measure inter-frame linear dependencies and then perform matching with only instance-level information, thus failing to capture more complex patterns such as nonlinear relationships and overlooking task-specific cues. Second, for efficient adaptation of CLIP to FSAR, recent work performing fine-tuning via skip-fusion layers (which we refer to as side layers) has significantly reduced memory cost. However, the newly introduced side layers are often difficult to optimize under limited data conditions. To address these limitations, we propose TS-FSAR, a framework comprising three components: (1) a visual Ladder Side Network (LSN) for efficient CLIP fine-tuning; (2) a metric called Task-Specific Distance Correlation Matching (TS-DCM), which uses $α$-distance correlation to model both linear and nonlinear inter-frame dependencies and leverages a task prototype to enable task-specific matching; and (3) a Guiding LSN with Adapted CLIP (GLAC) module, which regularizes LSN using the adapted frozen CLIP to improve training for better $α$-distance correlation estimation under limited supervision. Extensive experiments on five widely-used benchmarks demonstrate that our TS-FSAR yields superior performance compared to prior state-of-the-arts.
DALIP: Distribution Alignment-based Language-Image Pre-Training for Domain-Specific Data
Apr 02, 2025Recently, Contrastive Language-Image Pre-training (CLIP) has shown promising performance in domain-specific data (e.g., biology), and has attracted increasing research attention. Existing works generally focus on collecting extensive domain-specific data and directly tuning the original CLIP models. Intuitively, such a paradigm takes no full consideration of the characteristics lying in domain-specific data (e.g., fine-grained nature of biological data) and so limits model capability, while mostly losing the original ability of CLIP in the general domain. In this paper, we propose a Distribution Alignment-based Language-Image Pre-Training (DALIP) method for biological data. Specifically, DALIP optimizes CLIP models by matching the similarity between feature distribution of image-text pairs instead of the original [cls] token, which can capture rich yet effective information inherent in image-text pairs as powerful representations, and so better cope with fine-grained nature of biological data. Particularly, our DALIP efficiently approximates feature distribution via its first- and second-order statistics, while presenting a Multi-head Brownian Distance Covariance (MBDC) module to acquire second-order statistics of token features efficiently. Furthermore, we collect a new dataset for plant domain (e.g., specific data in biological domain) comprising 10M plant data with 3M general-domain data (namely PlantMix-13M) according to data mixing laws. Extensive experiments show that DALIP clearly outperforms existing CLIP counterparts in biological domain, while well generalizing to remote sensing and medical imaging domains. Besides, our PlantMix-13M dataset further boosts performance of DALIP in plant domain, while preserving model ability in general domain.
TC-LLaVA: Rethinking the Transfer from Image to Video Understanding with Temporal Considerations
Sep 05, 2024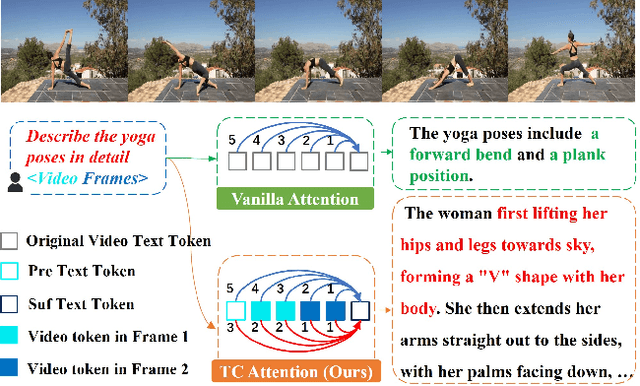

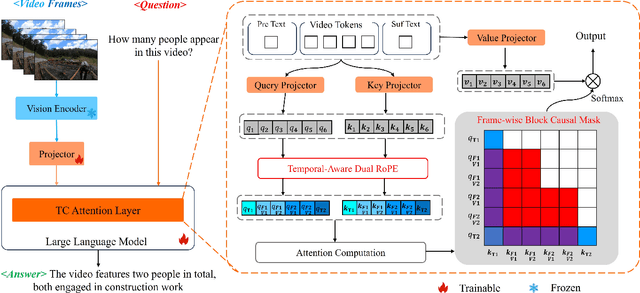

Multimodal Large Language Models (MLLMs) have significantly improved performance across various image-language applications. Recently, there has been a growing interest in adapting image pre-trained MLLMs for video-related tasks. However, most efforts concentrate on enhancing the vision encoder and projector components, while the core part, Large Language Models (LLMs), remains comparatively under-explored. In this paper, we propose two strategies to enhance the model's capability in video understanding tasks by improving inter-layer attention computation in LLMs. Specifically, the first approach focuses on the enhancement of Rotary Position Embedding (RoPE) with Temporal-Aware Dual RoPE, which introduces temporal position information to strengthen the MLLM's temporal modeling capabilities while preserving the relative position relationships of both visual and text tokens. The second approach involves enhancing the Attention Mask with the Frame-wise Block Causal Attention Mask, a simple yet effective method that broadens visual token interactions within and across video frames while maintaining the causal inference mechanism. Based on these proposed methods, we adapt LLaVA for video understanding tasks, naming it Temporal-Considered LLaVA (TC-LLaVA). Our TC-LLaVA achieves new state-of-the-art performance across various video understanding benchmarks with only supervised fine-tuning (SFT) on video-related datasets.
Joint Distribution Matters: Deep Brownian Distance Covariance for Few-Shot Classification
Apr 09, 2022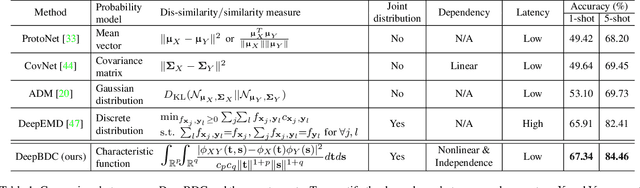
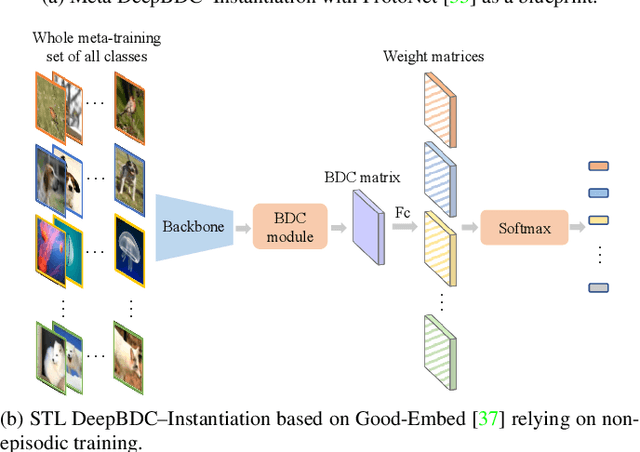
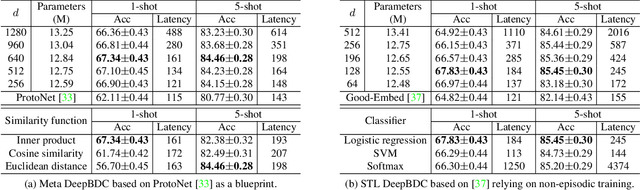
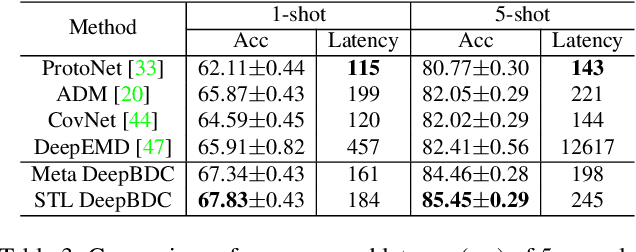
Few-shot classification is a challenging problem as only very few training examples are given for each new task. One of the effective research lines to address this challenge focuses on learning deep representations driven by a similarity measure between a query image and few support images of some class. Statistically, this amounts to measure the dependency of image features, viewed as random vectors in a high-dimensional embedding space. Previous methods either only use marginal distributions without considering joint distributions, suffering from limited representation capability, or are computationally expensive though harnessing joint distributions. In this paper, we propose a deep Brownian Distance Covariance (DeepBDC) method for few-shot classification. The central idea of DeepBDC is to learn image representations by measuring the discrepancy between joint characteristic functions of embedded features and product of the marginals. As the BDC metric is decoupled, we formulate it as a highly modular and efficient layer. Furthermore, we instantiate DeepBDC in two different few-shot classification frameworks. We make experiments on six standard few-shot image benchmarks, covering general object recognition, fine-grained categorization and cross-domain classification. Extensive evaluations show our DeepBDC significantly outperforms the counterparts, while establishing new state-of-the-art results. The source code is available at http://www.peihuali.org/DeepBDC
Binocular Mutual Learning for Improving Few-shot Classification
Aug 27, 2021
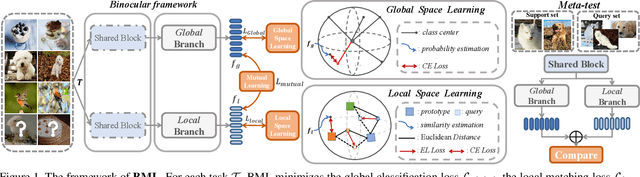
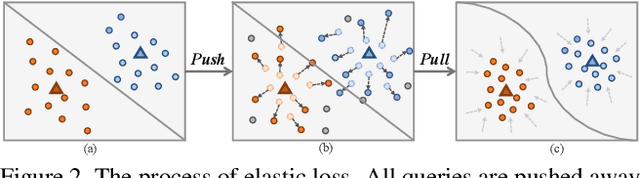
Most of the few-shot learning methods learn to transfer knowledge from datasets with abundant labeled data (i.e., the base set). From the perspective of class space on base set, existing methods either focus on utilizing all classes under a global view by normal pretraining, or pay more attention to adopt an episodic manner to train meta-tasks within few classes in a local view. However, the interaction of the two views is rarely explored. As the two views capture complementary information, we naturally think of the compatibility of them for achieving further performance gains. Inspired by the mutual learning paradigm and binocular parallax, we propose a unified framework, namely Binocular Mutual Learning (BML), which achieves the compatibility of the global view and the local view through both intra-view and cross-view modeling. Concretely, the global view learns in the whole class space to capture rich inter-class relationships. Meanwhile, the local view learns in the local class space within each episode, focusing on matching positive pairs correctly. In addition, cross-view mutual interaction further promotes the collaborative learning and the implicit exploration of useful knowledge from each other. During meta-test, binocular embeddings are aggregated together to support decision-making, which greatly improve the accuracy of classification. Extensive experiments conducted on multiple benchmarks including cross-domain validation confirm the effectiveness of our method.
3rd Place Solution for Short-video Face Parsing Challenge
Jul 14, 2021


This is a short technical report introducing the solution of Team Rat for Short-video Parsing Face Parsing Track of The 3rd Person in Context (PIC) Workshop and Challenge at CVPR 2021. In this report, we propose an Edge-Aware Network (EANet) that uses edge information to refine the segmentation edge. To further obtain the finer edge results, we introduce edge attention loss that only compute cross entropy on the edges, it can effectively reduce the classification error around edge and get more smooth boundary. Benefiting from the edge information and edge attention loss, the proposed EANet achieves 86.16\% accuracy in the Short-video Face Parsing track of the 3rd Person in Context (PIC) Workshop and Challenge, ranked the third place.
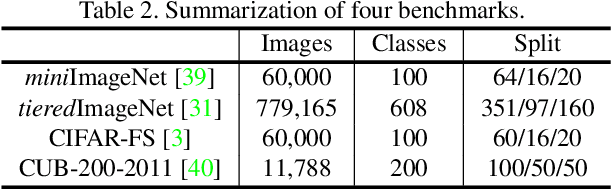
So-ViT: Mind Visual Tokens for Vision Transformer
Apr 22, 2021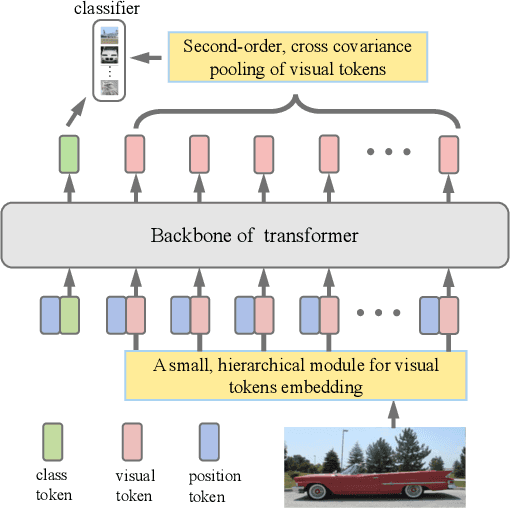

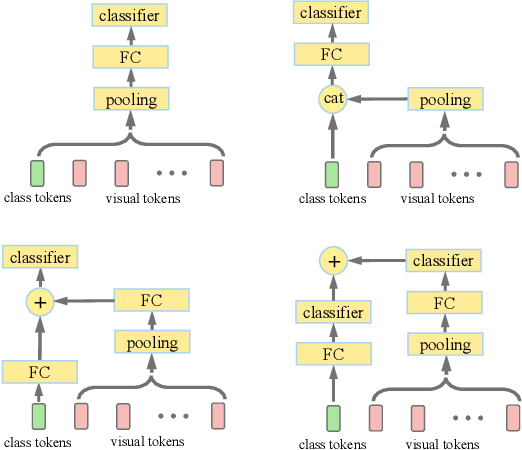
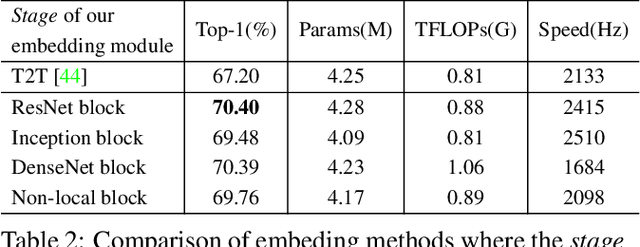
Recently the vision transformer (ViT) architecture, where the backbone purely consists of self-attention mechanism, has achieved very promising performance in visual classification. However, the high performance of the original ViT heavily depends on pretraining using ultra large-scale datasets, and it significantly underperforms on ImageNet-1K if trained from scratch. This paper makes the efforts toward addressing this problem, by carefully considering the role of visual tokens. First, for classification head, existing ViT only exploits class token while entirely neglecting rich semantic information inherent in high-level visual tokens. Therefore, we propose a new classification paradigm, where the second-order, cross-covariance pooling of visual tokens is combined with class token for final classification. Meanwhile, a fast singular value power normalization is proposed for improving the second-order pooling. Second, the original ViT employs the naive embedding of fixed-size image patches, lacking the ability to model translation equivariance and locality. To alleviate this problem, we develop a light-weight, hierarchical module based on off-the-shelf convolutions for visual token embedding. The proposed architecture, which we call So-ViT, is thoroughly evaluated on ImageNet-1K. The results show our models, when trained from scratch, outperform the competing ViT variants, while being on par with or better than state-of-the-art CNN models. Code is available at https://github.com/jiangtaoxie/So-ViT
Deep CNNs Meet Global Covariance Pooling: Better Representation and Generalization
Apr 15, 2019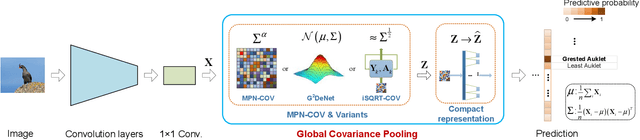

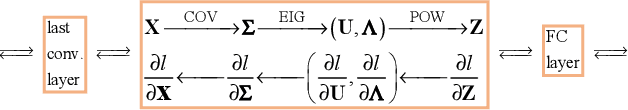

Compared with global average pooling in existing deep convolutional neural networks (CNNs), global covariance pooling can capture richer statistics of deep features, having potential for improving representation and generalization abilities of deep CNNs. However, integration of global covariance pooling into deep CNNs brings two challenges: (1) robust covariance estimation given deep features of high dimension and small sample; (2) appropriate use of geometry of covariances. To address these challenges, we propose a global Matrix Power Normalized COVariance (MPN-COV) Pooling. Our MPN-COV conforms to a robust covariance estimator, very suitable for scenario of high dimension and small sample. It can also be regarded as power-Euclidean metric between covariances, effectively exploiting their geometry. Furthermore, a global Gaussian embedding method is proposed to incorporate first-order statistics into MPN-COV. For fast training of MPN-COV networks, we propose an iterative matrix square root normalization, avoiding GPU unfriendly eigen-decomposition inherent in MPN-COV. Additionally, progressive 1x1 and group convolutions are introduced to compact covariance representations. The MPN-COV and its variants are highly modular, readily plugged into existing deep CNNs. Extensive experiments are conducted on large-scale object classification, scene categorization, fine-grained visual recognition and texture classification, showing our methods are superior to the counterparts and achieve state-of-the-art performance.
Global Second-order Pooling Convolutional Networks
Nov 30, 2018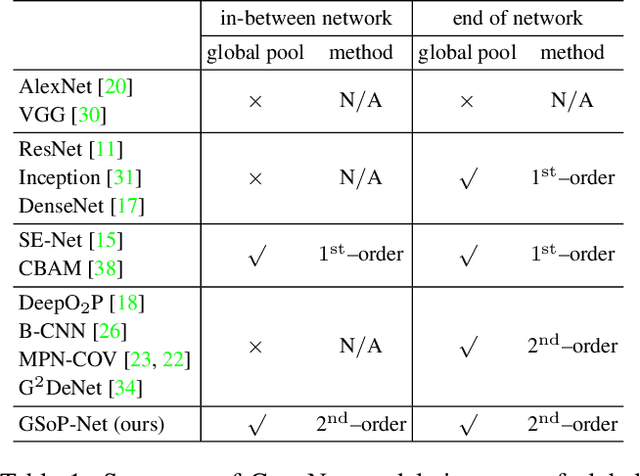
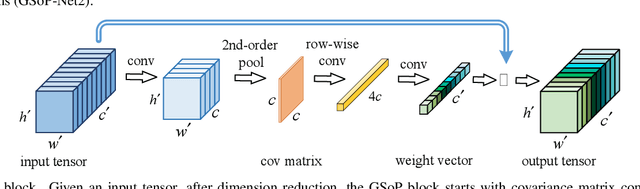
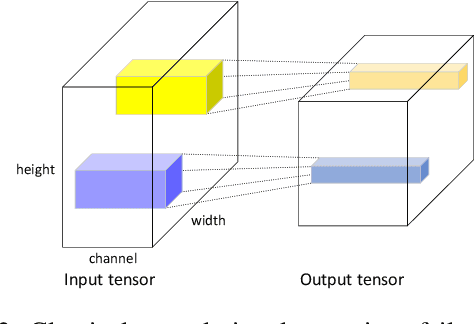
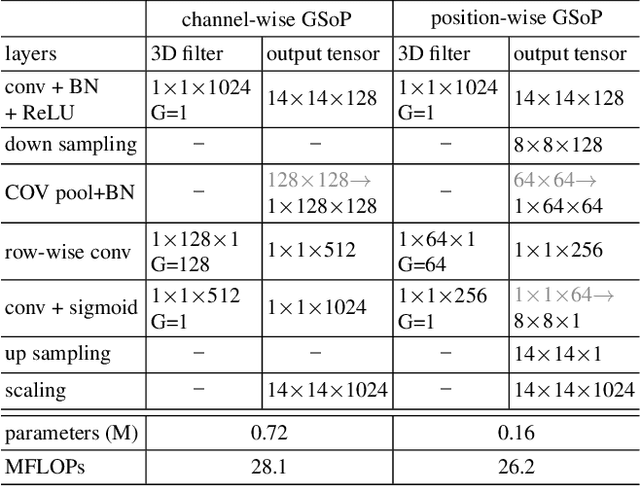
Deep Convolutional Networks (ConvNets) are fundamental to, besides large-scale visual recognition, a lot of vision tasks. As the primary goal of the ConvNets is to characterize complex boundaries of thousands of classes in a high-dimensional space, it is critical to learn higher-order representations for enhancing non-linear modeling capability. Recently, Global Second-order Pooling (GSoP), plugged at the end of networks, has attracted increasing attentions, achieving much better performance than classical, first-order networks in a variety of vision tasks. However, how to effectively introduce higher-order representation in earlier layers for improving non-linear capability of ConvNets is still an open problem. In this paper, we propose a novel network model introducing GSoP across from lower to higher layers for exploiting holistic image information throughout a network. Given an input 3D tensor outputted by some previous convolutional layer, we perform GSoP to obtain a covariance matrix which, after nonlinear transformation, is used for tensor scaling along channel dimension. Similarly, we can perform GSoP along spatial dimension for tensor scaling as well. In this way, we can make full use of the second-order statistics of the holistic image throughout a network. The proposed networks are thoroughly evaluated on large-scale ImageNet-1K, and experiments have shown that they outperformed non-trivially the counterparts while achieving state-of-the-art results.
Is Second-order Information Helpful for Large-scale Visual Recognition?
Apr 01, 2018



By stacking layers of convolution and nonlinearity, convolutional networks (ConvNets) effectively learn from low-level to high-level features and discriminative representations. Since the end goal of large-scale recognition is to delineate complex boundaries of thousands of classes, adequate exploration of feature distributions is important for realizing full potentials of ConvNets. However, state-of-the-art works concentrate only on deeper or wider architecture design, while rarely exploring feature statistics higher than first-order. We take a step towards addressing this problem. Our method consists in covariance pooling, instead of the most commonly used first-order pooling, of high-level convolutional features. The main challenges involved are robust covariance estimation given a small sample of large-dimensional features and usage of the manifold structure of covariance matrices. To address these challenges, we present a Matrix Power Normalized Covariance (MPN-COV) method. We develop forward and backward propagation formulas regarding the nonlinear matrix functions such that MPN-COV can be trained end-to-end. In addition, we analyze both qualitatively and quantitatively its advantage over the well-known Log-Euclidean metric. On the ImageNet 2012 validation set, by combining MPN-COV we achieve over 4%, 3% and 2.5% gains for AlexNet, VGG-M and VGG-16, respectively; integration of MPN-COV into 50-layer ResNet outperforms ResNet-101 and is comparable to ResNet-152. The source code will be available on the project page: http://www.peihuali.org/MPN-COV