 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Specific Distance Correlation Matching for Few-Shot Action Recognition
Dec 15, 2025Few-shot action recognition (FSAR) has recently made notable progress through set matching and efficient adaptation of large-scale pre-trained models. However, two key limitations persist. First, existing set matching metrics typically rely on cosine similarity to measure inter-frame linear dependencies and then perform matching with only instance-level information, thus failing to capture more complex patterns such as nonlinear relationships and overlooking task-specific cues. Second, for efficient adaptation of CLIP to FSAR, recent work performing fine-tuning via skip-fusion layers (which we refer to as side layers) has significantly reduced memory cost. However, the newly introduced side layers are often difficult to optimize under limited data conditions. To address these limitations, we propose TS-FSAR, a framework comprising three components: (1) a visual Ladder Side Network (LSN) for efficient CLIP fine-tuning; (2) a metric called Task-Specific Distance Correlation Matching (TS-DCM), which uses $α$-distance correlation to model both linear and nonlinear inter-frame dependencies and leverages a task prototype to enable task-specific matching; and (3) a Guiding LSN with Adapted CLIP (GLAC) module, which regularizes LSN using the adapted frozen CLIP to improve training for better $α$-distance correlation estimation under limited supervision. Extensive experiments on five widely-used benchmarks demonstrate that our TS-FSAR yields superior performance compared to prior state-of-the-arts.
Wasserstein Distance Rivals Kullback-Leibler Divergence for Knowledge Distillation
Dec 11, 2024



Since pioneering work of Hinton et al., knowledge distillation based on Kullback-Leibler Divergence (KL-Div) has been predominant, and recently its variants have achieved compelling performance. However, KL-Div only compares probabilities of the corresponding category between the teacher and student while lacking a mechanism for cross-category comparison. Besides, KL-Div is problematic when applied to intermediate layers, as it cannot handle non-overlapping distributions and is unaware of geometry of the underlying manifold. To address these downsides, we propose a methodology of Wasserstein Distance (WD) based knowledge distillation. Specifically, we propose a logit distillation method called WKD-L based on discrete WD, which performs cross-category comparison of probabilities and thus can explicitly leverage rich interrelations among categories. Moreover, we introduce a feature distillation method called WKD-F, which uses a parametric method for modeling feature distributions and adopts continuous WD for transferring knowledge from intermediate layers. Comprehensive evaluations on image classification and object detection have shown (1) for logit distillation WKD-L outperforms very strong KL-Div variants; (2) for feature distillation WKD-F is superior to the KL-Div counterparts and state-of-the-art competitors. The source code is available at https://peihuali.org/WKD
Joint Distribution Matters: Deep Brownian Distance Covariance for Few-Shot Classification
Apr 09, 2022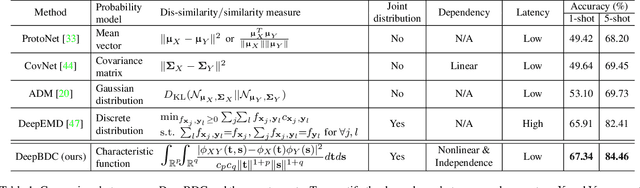
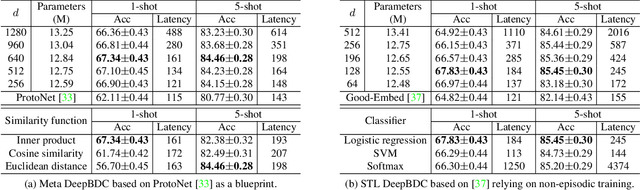
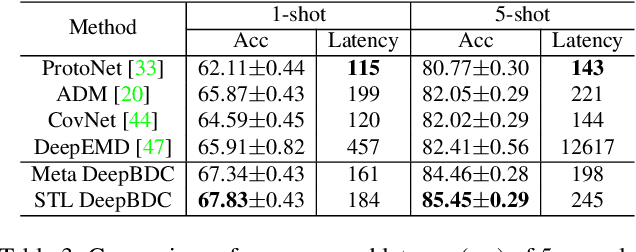
Few-shot classification is a challenging problem as only very few training examples are given for each new task. One of the effective research lines to address this challenge focuses on learning deep representations driven by a similarity measure between a query image and few support images of some class. Statistically, this amounts to measure the dependency of image features, viewed as random vectors in a high-dimensional embedding space. Previous methods either only use marginal distributions without considering joint distributions, suffering from limited representation capability, or are computationally expensive though harnessing joint distributions. In this paper, we propose a deep Brownian Distance Covariance (DeepBDC) method for few-shot classification. The central idea of DeepBDC is to learn image representations by measuring the discrepancy between joint characteristic functions of embedded features and product of the marginals. As the BDC metric is decoupled, we formulate it as a highly modular and efficient layer. Furthermore, we instantiate DeepBDC in two different few-shot classification frameworks. We make experiments on six standard few-shot image benchmarks, covering general object recognition, fine-grained categorization and cross-domain classification. Extensive evaluations show our DeepBDC significantly outperforms the counterparts, while establishing new state-of-the-art results. The source code is available at http://www.peihuali.org/DeepBDC