 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTCS: Test-Time Curriculum Synthesis for Self-Evolving
Jan 30, 2026Test-Time Training offers a promising way to improve the reasoning ability of large language models (LLMs) by adapting the model using only the test questions. However, existing methods struggle with difficult reasoning problems for two reasons: raw test questions are often too difficult to yield high-quality pseudo-labels, and the limited size of test sets makes continuous online updates prone to instability. To address these limitations, we propose TTCS, a co-evolving test-time training framework. Specifically, TTCS initializes two policies from the same pretrained model: a question synthesizer and a reasoning solver. These policies evolve through iterative optimization: the synthesizer generates progressively challenging question variants conditioned on the test questions, creating a structured curriculum tailored to the solver's current capability, while the solver updates itself using self-consistency rewards computed from multiple sampled responses on both original test and synthetic questions. Crucially, the solver's feedback guides the synthesizer to generate questions aligned with the model's current capability, and the generated question variants in turn stabilize the solver's test-time training. Experiments show that TTCS consistently strengthens the reasoning ability on challenging mathematical benchmarks and transfers to general-domain tasks across different LLM backbones, highlighting a scalable path towards dynamically constructing test-time curricula for self-evolving. Our code and implementation details are available at https://github.com/XMUDeepLIT/TTCS.
Task-Specific Distance Correlation Matching for Few-Shot Action Recognition
Dec 15, 2025Few-shot action recognition (FSAR) has recently made notable progress through set matching and efficient adaptation of large-scale pre-trained models. However, two key limitations persist. First, existing set matching metrics typically rely on cosine similarity to measure inter-frame linear dependencies and then perform matching with only instance-level information, thus failing to capture more complex patterns such as nonlinear relationships and overlooking task-specific cues. Second, for efficient adaptation of CLIP to FSAR, recent work performing fine-tuning via skip-fusion layers (which we refer to as side layers) has significantly reduced memory cost. However, the newly introduced side layers are often difficult to optimize under limited data conditions. To address these limitations, we propose TS-FSAR, a framework comprising three components: (1) a visual Ladder Side Network (LSN) for efficient CLIP fine-tuning; (2) a metric called Task-Specific Distance Correlation Matching (TS-DCM), which uses $α$-distance correlation to model both linear and nonlinear inter-frame dependencies and leverages a task prototype to enable task-specific matching; and (3) a Guiding LSN with Adapted CLIP (GLAC) module, which regularizes LSN using the adapted frozen CLIP to improve training for better $α$-distance correlation estimation under limited supervision. Extensive experiments on five widely-used benchmarks demonstrate that our TS-FSAR yields superior performance compared to prior state-of-the-arts.
DMA: Online RAG Alignment with Human Feedback
Nov 06, 2025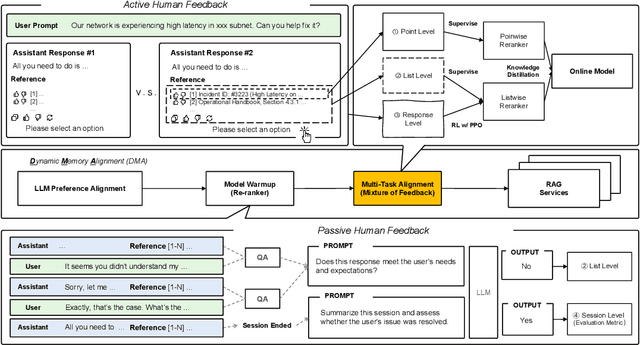

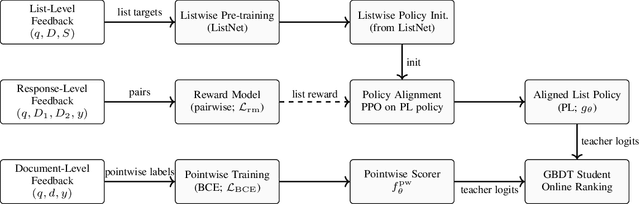
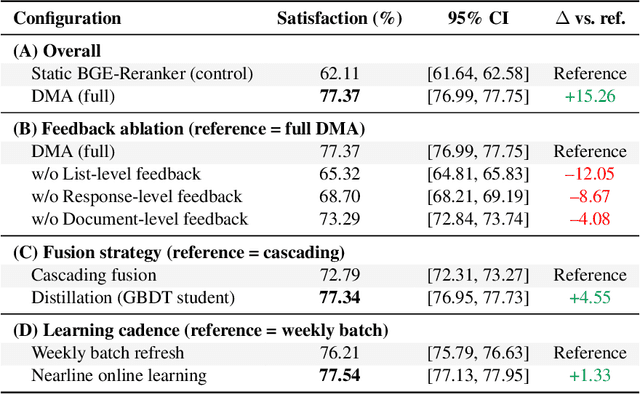
Retrieval-augmented generation (RAG) systems often rely on static retrieval, limiting adaptation to evolving intent and content drift. We introduce Dynamic Memory Alignment (DMA), an online learning framework that systematically incorporates multi-granularity human feedback to align ranking in interactive settings. DMA organizes document-, list-, and response-level signals into a coherent learning pipeline: supervised training for pointwise and listwise rankers, policy optimization driven by response-level preferences, and knowledge distillation into a lightweight scorer for low-latency serving. Throughout this paper, memory refers to the model's working memory, which is the entire context visible to the LLM for In-Context Learning. We adopt a dual-track evaluation protocol mirroring deployment: (i) large-scale online A/B ablations to isolate the utility of each feedback source, and (ii) few-shot offline tests on knowledge-intensive benchmarks. Online, a multi-month industrial deployment further shows substantial improvements in human engagement. Offline, DMA preserves competitive foundational retrieval while yielding notable gains on conversational QA (TriviaQA, HotpotQA). Taken together, these results position DMA as a principled approach to feedback-driven, real-time adaptation in RAG without sacrificing baseline capability.
Unsupervised Multimodal Clustering for Semantics Discovery in Multimodal Utterances
May 21, 2024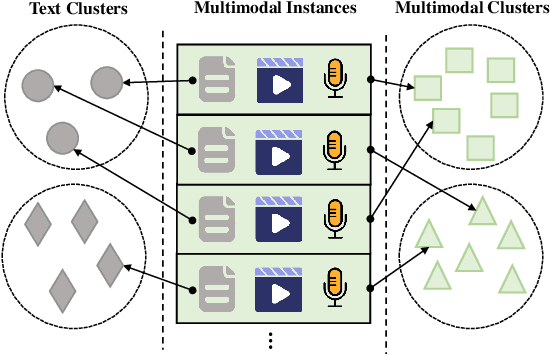
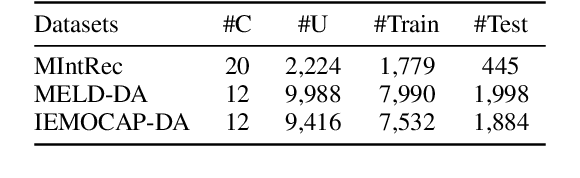
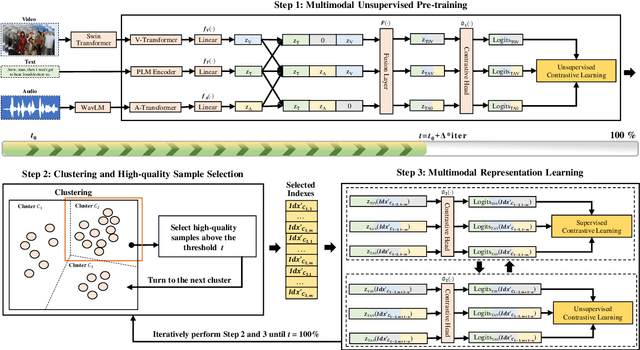
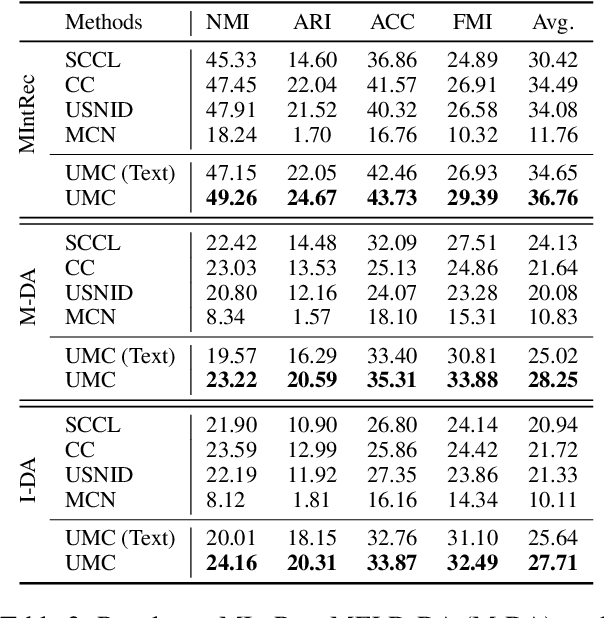
Discovering the semantics of multimodal utterances is essential for understanding human language and enhancing human-machine interactions. Existing methods manifest limitations in leveraging nonverbal information for discerning complex semantics in unsupervised scenarios. This paper introduces a novel unsupervised multimodal clustering method (UMC), making a pioneering contribution to this field. UMC introduces a unique approach to constructing augmentation views for multimodal data, which are then used to perform pre-training to establish well-initialized representations for subsequent clustering. An innovative strategy is proposed to dynamically select high-quality samples as guidance for representation learning, gauged by the density of each sample's nearest neighbors. Besides, it is equipped to automatically determine the optimal value for the top-$K$ parameter in each cluster to refine sample selection. Finally, both high- and low-quality samples are used to learn representations conducive to effective clustering. We build baselines on benchmark multimodal intent and dialogue act datasets. UMC shows remarkable improvements of 2-6\% scores in clustering metrics over state-of-the-art methods, marking the first successful endeavor in this domain. The complete code and data are available at https://github.com/thuiar/UMC.
USNID: A Framework for Unsupervised and Semi-supervised New Intent Discovery
Apr 16, 2023



New intent discovery is of great value to natural language processing, allowing for a better understanding of user needs and providing friendly services. However, most existing methods struggle to capture the complicated semantics of discrete text representations when limited or no prior knowledge of labeled data is available. To tackle this problem, we propose a novel framework called USNID for unsupervised and semi-supervised new intent discovery, which has three key technologies. First, it takes full use of unsupervised or semi-supervised data to mine shallow semantic similarity relations and provide well-initialized representations for clustering. Second, it designs a centroid-guided clustering mechanism to address the issue of cluster allocation inconsistency and provide high-quality self-supervised targets for representation learning. Third, it captures high-level semantics in unsupervised or semi-supervised data to discover fine-grained intent-wise clusters by optimizing both cluster-level and instance-level objectives. We also propose an effective method for estimating the cluster number in open-world scenarios without knowing the number of new intents beforehand. USNID performs exceptionally well on several intent benchmark datasets, achieving new state-of-the-art results in unsupervised and semi-supervised new intent discovery and demonstrating robust performance with different cluster numbers.
Joint Distribution Matters: Deep Brownian Distance Covariance for Few-Shot Classification
Apr 09, 2022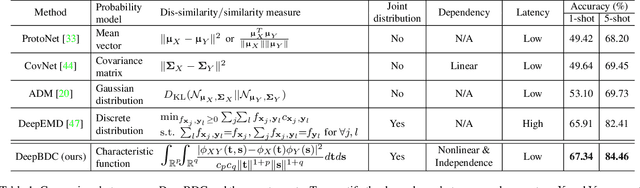
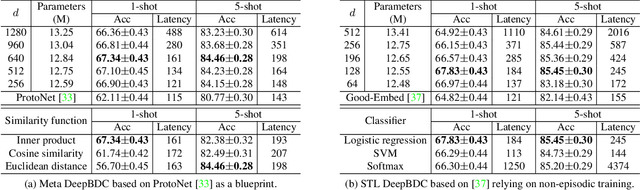
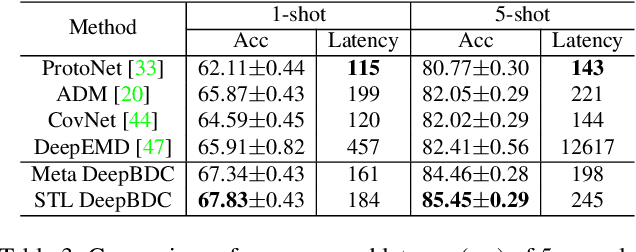
Few-shot classification is a challenging problem as only very few training examples are given for each new task. One of the effective research lines to address this challenge focuses on learning deep representations driven by a similarity measure between a query image and few support images of some class. Statistically, this amounts to measure the dependency of image features, viewed as random vectors in a high-dimensional embedding space. Previous methods either only use marginal distributions without considering joint distributions, suffering from limited representation capability, or are computationally expensive though harnessing joint distributions. In this paper, we propose a deep Brownian Distance Covariance (DeepBDC) method for few-shot classification. The central idea of DeepBDC is to learn image representations by measuring the discrepancy between joint characteristic functions of embedded features and product of the marginals. As the BDC metric is decoupled, we formulate it as a highly modular and efficient layer. Furthermore, we instantiate DeepBDC in two different few-shot classification frameworks. We make experiments on six standard few-shot image benchmarks, covering general object recognition, fine-grained categorization and cross-domain classification. Extensive evaluations show our DeepBDC significantly outperforms the counterparts, while establishing new state-of-the-art results. The source code is available at http://www.peihuali.org/DeepBDC
Joint CNN and Transformer Network via weakly supervised Learning for efficient crowd counting
Mar 12, 2022

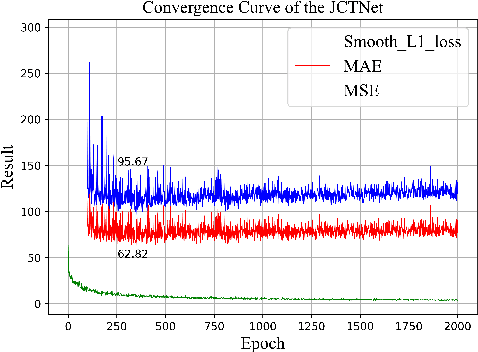
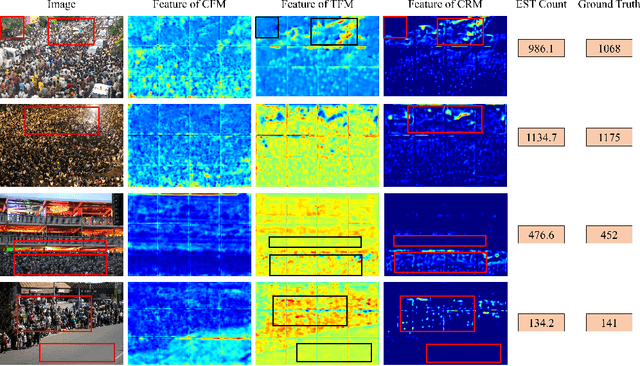
Currently, for crowd counting, the fully supervised methods via density map estimation are the mainstream research directions. However, such methods need location-level annotation of persons in an image, which is time-consuming and laborious. Therefore, the weakly supervised method just relying upon the count-level annotation is urgently needed. Since CNN is not suitable for modeling the global context and the interactions between image patches, crowd counting with weakly supervised learning via CNN generally can not show good performance. The weakly supervised model via Transformer was sequentially proposed to model the global context and learn contrast features. However, the transformer directly partitions the crowd images into a series of tokens, which may not be a good choice due to each pedestrian being an independent individual, and the parameter number of the network is very large. Hence, we propose a Joint CNN and Transformer Network (JCTNet) via weakly supervised learning for crowd counting in this paper. JCTNet consists of three parts: CNN feature extraction module (CFM), Transformer feature extraction module (TFM), and counting regression module (CRM). In particular, the CFM extracts crowd semantic information features, then sends their patch partitions to TRM for modeling global context, and CRM is used to predict the number of people. Extensive experiments and visualizations demonstrate that JCTNet can effectively focus on the crowd regions and obtain superior weakly supervised counting performance on five mainstream datasets. The number of parameters of the model can be reduced by about 67%~73% compared with the pure Transformer works. We also tried to explain the phenomenon that a model constrained only by count-level annotations can still focus on the crowd regions. We believe our work can promote further research in this field.