 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Help Multimodal Language Analysis? MMLA: A Comprehensive Benchmark
Apr 24, 2025Multimodal language analysis is a rapidly evolving field that leverages multiple modalities to enhance the understanding of high-level semantics underlying human conversational utterances. Despite its significance, little research has investigated the capability of multimodal large language models (MLLMs) to comprehend cognitive-level semantics. In this paper, we introduce MMLA, a comprehensive benchmark specifically designed to address this gap. MMLA comprises over 61K multimodal utterances drawn from both staged and real-world scenarios, covering six core dimensions of multimodal semantics: intent, emotion, dialogue act, sentiment, speaking style, and communication behavior. We evaluate eight mainstream branches of LLMs and MLLMs using three methods: zero-shot inference, supervised fine-tuning, and instruction tuning. Extensive experiments reveal that even fine-tuned models achieve only about 60%~70% accuracy, underscoring the limitations of current MLLMs in understanding complex human language. We believe that MMLA will serve as a solid foundation for exploring the potential of large language models in multimodal language analysis and provide valuable resources to advance this field. The datasets and code are open-sourced at https://github.com/thuiar/MMLA.
Deep-Learning Recognition of Scanning Transmission Electron Microscopy: Quantifying and Mitigating the Influence of Gaussian Noises
Sep 25, 2024
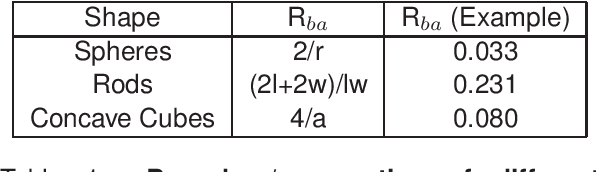
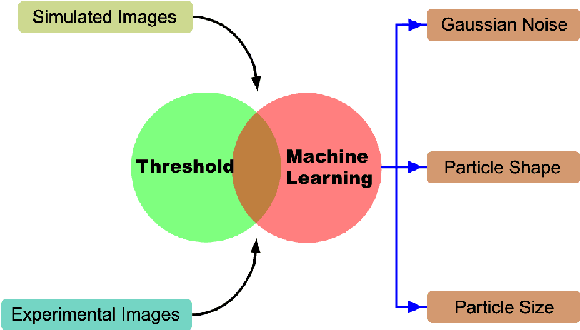
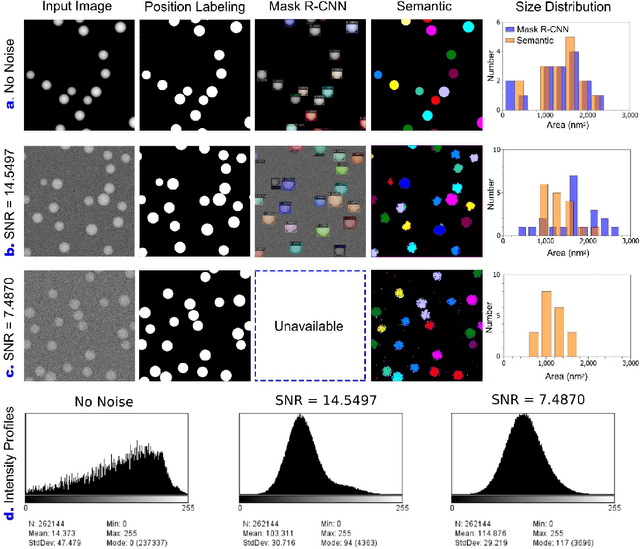
Scanning transmission electron microscopy (STEM) is a powerful tool to reveal the morphologies and structures of materials, thereby attracting intensive interests from the scientific and industrial communities. The outstanding spatial (atomic level) and temporal (ms level) resolutions of the STEM techniques generate fruitful amounts of high-definition data, thereby enabling the high-volume and high-speed analysis of materials. On the other hand, processing of the big dataset generated by STEM is time-consuming and beyond the capability of human-based manual work, which urgently calls for computer-based automation. In this work, we present a deep-learning mask region-based neural network (Mask R-CNN) for the recognition of nanoparticles imaged by STEM, as well as generating the associated dimensional analysis. The Mask R-CNN model was tested on simulated STEM-HAADF results with different Gaussian noises, particle shapes and particle sizes, and the results indicated that Gaussian noise has determining influence on the accuracy of recognition. By applying Gaussian and Non-Local Means filters on the noise-containing STEM-HAADF results, the influences of noises are largely mitigated, and recognition accuracy is significantly improved. This filtering-recognition approach was further applied to experimental STEM-HAADF results, which yields satisfying accuracy compared with the traditional threshold methods. The deep-learning-based method developed in this work has great potentials in analysis of the complicated structures and large data generated by STEM-HAADF.
Unsupervised Multimodal Clustering for Semantics Discovery in Multimodal Utterances
May 21, 2024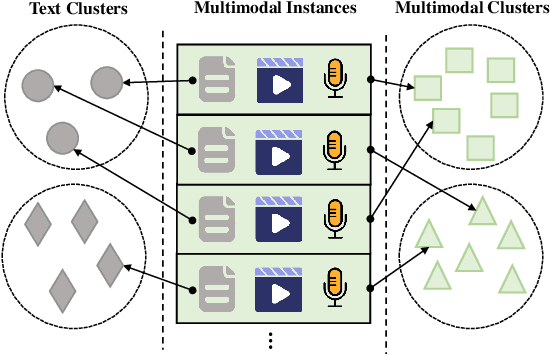
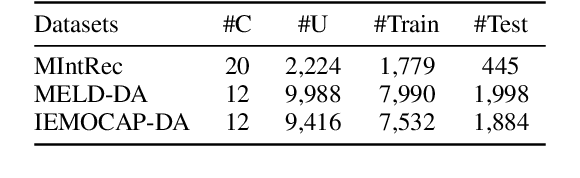
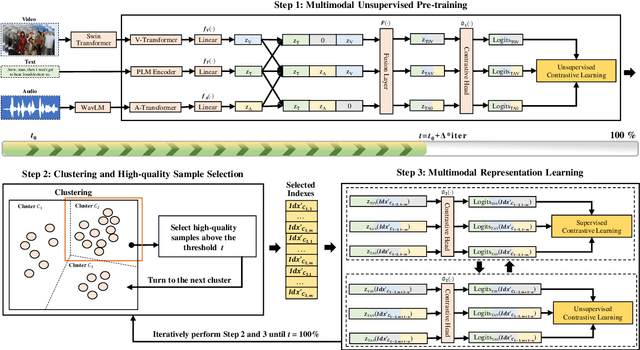
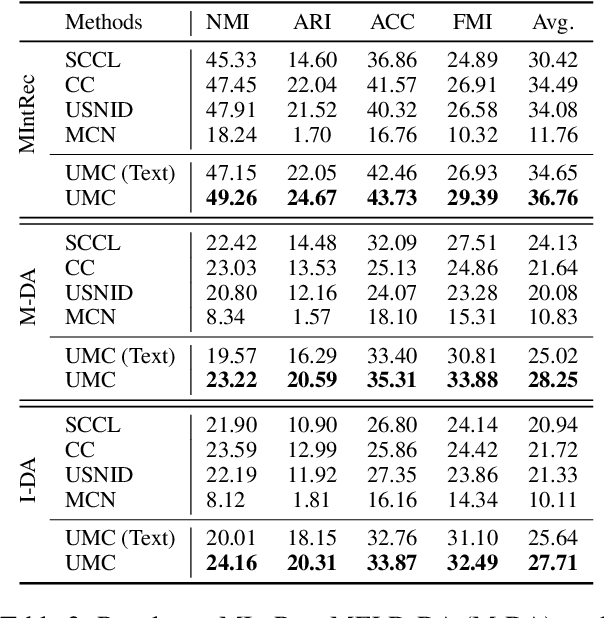
Discovering the semantics of multimodal utterances is essential for understanding human language and enhancing human-machine interactions. Existing methods manifest limitations in leveraging nonverbal information for discerning complex semantics in unsupervised scenarios. This paper introduces a novel unsupervised multimodal clustering method (UMC), making a pioneering contribution to this field. UMC introduces a unique approach to constructing augmentation views for multimodal data, which are then used to perform pre-training to establish well-initialized representations for subsequent clustering. An innovative strategy is proposed to dynamically select high-quality samples as guidance for representation learning, gauged by the density of each sample's nearest neighbors. Besides, it is equipped to automatically determine the optimal value for the top-$K$ parameter in each cluster to refine sample selection. Finally, both high- and low-quality samples are used to learn representations conducive to effective clustering. We build baselines on benchmark multimodal intent and dialogue act datasets. UMC shows remarkable improvements of 2-6\% scores in clustering metrics over state-of-the-art methods, marking the first successful endeavor in this domain. The complete code and data are available at https://github.com/thuiar/UMC.
MIntRec2.0: A Large-scale Benchmark Dataset for Multimodal Intent Recognition and Out-of-scope Detection in Conversations
Mar 20, 2024



Multimodal intent recognition poses significant challenges, requiring the incorporation of non-verbal modalities from real-world contexts to enhance the comprehension of human intentions. Existing benchmark datasets are limited in scale and suffer from difficulties in handling out-of-scope samples that arise in multi-turn conversational interactions. We introduce MIntRec2.0, a large-scale benchmark dataset for multimodal intent recognition in multi-party conversations. It contains 1,245 dialogues with 15,040 samples, each annotated within a new intent taxonomy of 30 fine-grained classes. Besides 9,304 in-scope samples, it also includes 5,736 out-of-scope samples appearing in multi-turn contexts, which naturally occur in real-world scenarios. Furthermore, we provide comprehensive information on the speakers in each utterance, enriching its utility for multi-party conversational research. We establish a general framework supporting the organization of single-turn and multi-turn dialogue data, modality feature extraction, multimodal fusion, as well as in-scope classification and out-of-scope detection. Evaluation benchmarks are built using classic multimodal fusion methods, ChatGPT, and human evaluators. While existing methods incorporating nonverbal information yield improvements, effectively leveraging context information and detecting out-of-scope samples remains a substantial challenge. Notably, large language models exhibit a significant performance gap compared to humans, highlighting the limitations of machine learning methods in the cognitive intent understanding task. We believe that MIntRec2.0 will serve as a valuable resource, providing a pioneering foundation for research in human-machine conversational interactions, and significantly facilitating related applications. The full dataset and codes are available at https://github.com/thuiar/MIntRec2.0.
Token-Level Contrastive Learning with Modality-Aware Prompting for Multimodal Intent Recognition
Dec 22, 2023


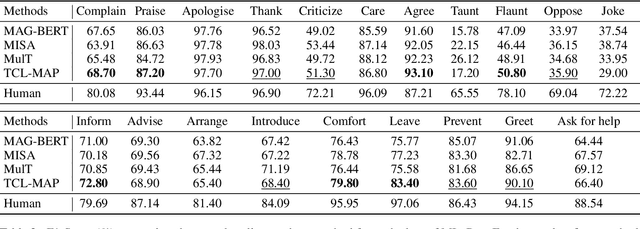
Multimodal intent recognition aims to leverage diverse modalities such as expressions, body movements and tone of speech to comprehend user's intent, constituting a critical task for understanding human language and behavior in real-world multimodal scenarios. Nevertheless, the majority of existing methods ignore potential correlations among different modalities and own limitations in effectively learning semantic features from nonverbal modalities. In this paper, we introduce a token-level contrastive learning method with modality-aware prompting (TCL-MAP) to address the above challenges. To establish an optimal multimodal semantic environment for text modality, we develop a modality-aware prompting module (MAP), which effectively aligns and fuses features from text, video and audio modalities with similarity-based modality alignment and cross-modality attention mechanism. Based on the modality-aware prompt and ground truth labels, the proposed token-level contrastive learning framework (TCL) constructs augmented samples and employs NT-Xent loss on the label token. Specifically, TCL capitalizes on the optimal textual semantic insights derived from intent labels to guide the learning processes of other modalities in return. Extensive experiments show that our method achieves remarkable improvements compared to state-of-the-art methods. Additionally, ablation analyses demonstrate the superiority of the modality-aware prompt over the handcrafted prompt, which holds substantial significance for multimodal prompt learning. The codes are released at https://github.com/thuiar/TCL-MAP.
USNID: A Framework for Unsupervised and Semi-supervised New Intent Discovery
Apr 16, 2023



New intent discovery is of great value to natural language processing, allowing for a better understanding of user needs and providing friendly services. However, most existing methods struggle to capture the complicated semantics of discrete text representations when limited or no prior knowledge of labeled data is available. To tackle this problem, we propose a novel framework called USNID for unsupervised and semi-supervised new intent discovery, which has three key technologies. First, it takes full use of unsupervised or semi-supervised data to mine shallow semantic similarity relations and provide well-initialized representations for clustering. Second, it designs a centroid-guided clustering mechanism to address the issue of cluster allocation inconsistency and provide high-quality self-supervised targets for representation learning. Third, it captures high-level semantics in unsupervised or semi-supervised data to discover fine-grained intent-wise clusters by optimizing both cluster-level and instance-level objectives. We also propose an effective method for estimating the cluster number in open-world scenarios without knowing the number of new intents beforehand. USNID performs exceptionally well on several intent benchmark datasets, achieving new state-of-the-art results in unsupervised and semi-supervised new intent discovery and demonstrating robust performance with different cluster numbers.
MIntRec: A New Dataset for Multimodal Intent Recognition
Sep 09, 2022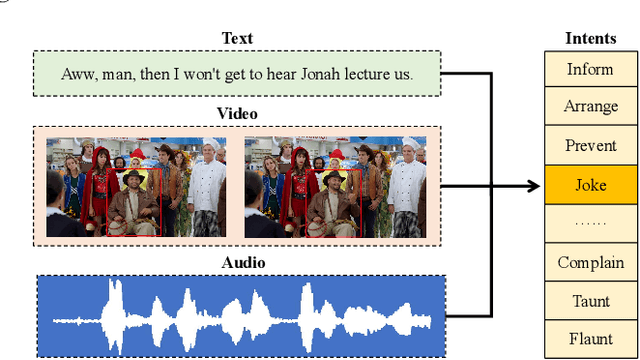

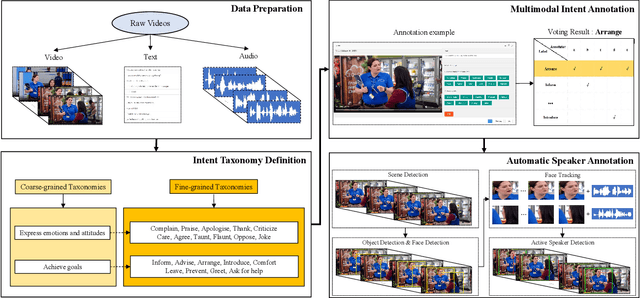

Multimodal intent recognition is a significant task for understanding human language in real-world multimodal scenes. Most existing intent recognition methods have limitations in leveraging the multimodal information due to the restrictions of the benchmark datasets with only text information. This paper introduces a novel dataset for multimodal intent recognition (MIntRec) to address this issue. It formulates coarse-grained and fine-grained intent taxonomies based on the data collected from the TV series Superstore. The dataset consists of 2,224 high-quality samples with text, video, and audio modalities and has multimodal annotations among twenty intent categories. Furthermore, we provide annotated bounding boxes of speakers in each video segment and achieve an automatic process for speaker annotation. MIntRec is helpful for researchers to mine relationships between different modalities to enhance the capability of intent recognition. We extract features from each modality and model cross-modal interactions by adapting three powerful multimodal fusion methods to build baselines. Extensive experiments show that employing the non-verbal modalities achieves substantial improvements compared with the text-only modality, demonstrating the effectiveness of using multimodal information for intent recognition. The gap between the best-performing methods and humans indicates the challenge and importance of this task for the community. The full dataset and codes are available for use at https://github.com/thuiar/MIntRec.
Towards Open Intent Detection
Mar 11, 2022

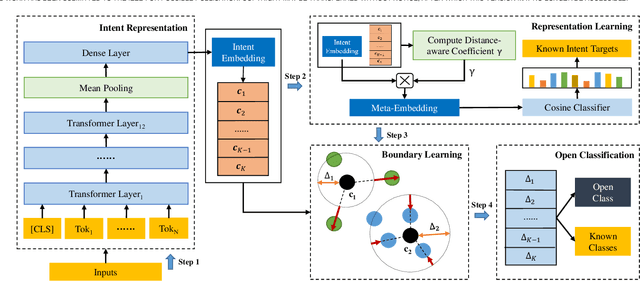

The open intent detection problem is presented in this paper, which aims to identify known intents and detect open intent in natural language understanding. Current methods have two core challenges. On the one hand, the existing methods have limitations in learning robust representations to detect the open intent without any prior knowledge. On the other hand, there lacks an effective approach to learning the specific and compact decision boundary to distinguish the known intents and the open intent. This paper introduces an original pipeline framework, DA-ADB, to address these issues, which successively learns discriminative intent features with distance-aware strategy and appropriate decision boundaries adaptive to the feature space for open intent detection. The proposed method first leverages distance information to enhance the distinguishing capability of the intent representations. Then, it obtains discriminative decision boundaries adaptive to the known intent feature space by balancing both the empirical and open space risks. Extensive experiments show the effectiveness of distance-aware and boundary learning strategies. Compared with the state-of-the-art methods, our method achieves substantial improvements on three benchmark intent datasets. It also yields robust performance with different proportions of labeled data and known categories.
Deep Open Intent Classification with Adaptive Decision Boundary
Dec 23, 2020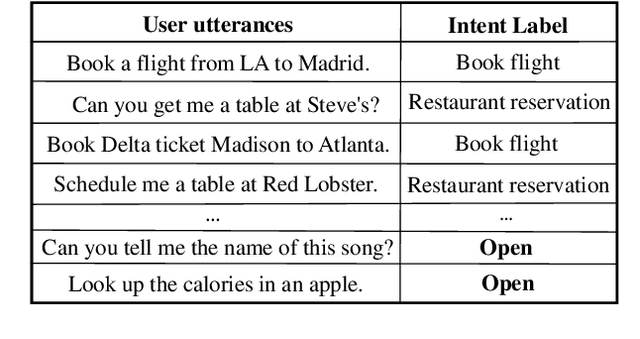

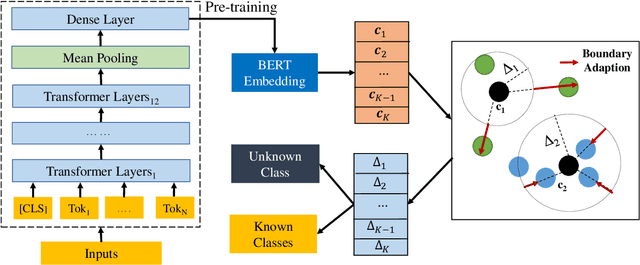
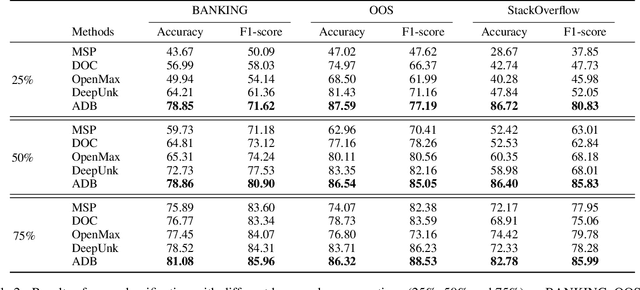
Open intent classification is a challenging task in dialogue system. On the one hand, we should ensure the classification quality of known intents. On the other hand, we need to identify the open (unknown) intent during testing. Current models are limited in finding the appropriate decision boundary to balance the performance of both known and open intents. In this paper, we propose a post-processing method to learn the adaptive decision boundary (ADB) for open intent classification. We first utilize the labeled known intent samples to pre-train the model. Then, we use the well-trained features to automatically learn the adaptive spherical decision boundaries for each known intent. Specifically, we propose a new loss function to balance both the empirical risk and the open space risk. Our method does not need unknown samples and is free from modifying the model architecture. We find our approach is surprisingly insensitive with less labeled data and fewer known intents. Extensive experiments on three benchmark datasets show that our method yields significant improvements compared with the state-of-the-art methods. (Code available at https://github.com/HanleiZhang/Adaptive-Decision-Boundary)
Discovering New Intents with Deep Aligned Clustering
Dec 22, 2020
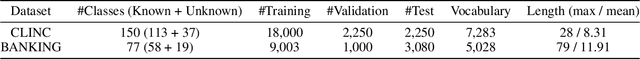

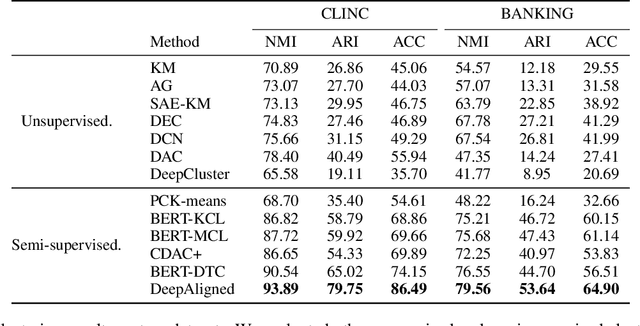
Discovering new intents is a crucial task in a dialogue system. Most existing methods are limited in transferring the prior knowledge from known intents to new intents. These methods also have difficulties in providing high-quality supervised signals to learn clustering-friendly features for grouping unlabeled intents. In this work, we propose an effective method (Deep Aligned Clustering) to discover new intents with the aid of limited known intent data. Firstly, we leverage a few labeled known intent samples as prior knowledge to pre-train the model. Then, we perform k-means to produce cluster assignments as pseudo-labels. Moreover, we propose an alignment strategy to tackle the label inconsistency during clustering assignments. Finally, we learn the intent representations under the supervision of the aligned pseudo-labels. With an unknown number of new intents, we predict the number of intent categories by eliminating low-confidence intent-wise clusters. Extensive experiments on two benchmark datasets show that our method is more robust and achieves substantial improvements over the state-of-the-art methods.(Code available at https://github.com/hanleizhang/DeepAligned-Clustering)