 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEPHN: Different Expression Parallel Heterogeneous Network using virtual gradient optimization for Multi-task Learning
Jul 24, 2023

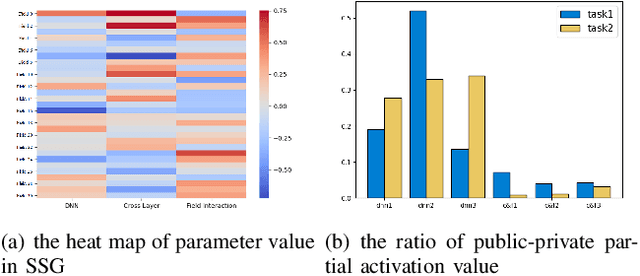

Recommendation system algorithm based on multi-task learning (MTL) is the major method for Internet operators to understand users and predict their behaviors in the multi-behavior scenario of platform. Task correlation is an important consideration of MTL goals, traditional models use shared-bottom models and gating experts to realize shared representation learning and information differentiation. However, The relationship between real-world tasks is often more complex than existing methods do not handle properly sharing information. In this paper, we propose an Different Expression Parallel Heterogeneous Network (DEPHN) to model multiple tasks simultaneously. DEPHN constructs the experts at the bottom of the model by using different feature interaction methods to improve the generalization ability of the shared information flow. In view of the model's differentiating ability for different task information flows, DEPHN uses feature explicit mapping and virtual gradient coefficient for expert gating during the training process, and adaptively adjusts the learning intensity of the gated unit by considering the difference of gating values and task correlation. Extensive experiments on artificial and real-world datasets demonstrate that our proposed method can capture task correlation in complex situations and achieve better performance than baseline models\footnote{Accepted in IJCNN2023}.
FaFCNN: A General Disease Classification Framework Based on Feature Fusion Neural Networks
Jul 24, 2023



There are two fundamental problems in applying deep learning/machine learning methods to disease classification tasks, one is the insufficient number and poor quality of training samples; another one is how to effectively fuse multiple source features and thus train robust classification models. To address these problems, inspired by the process of human learning knowledge, we propose the Feature-aware Fusion Correlation Neural Network (FaFCNN), which introduces a feature-aware interaction module and a feature alignment module based on domain adversarial learning. This is a general framework for disease classification, and FaFCNN improves the way existing methods obtain sample correlation features. The experimental results show that training using augmented features obtained by pre-training gradient boosting decision tree yields more performance gains than random-forest based methods. On the low-quality dataset with a large amount of missing data in our setup, FaFCNN obtains a consistently optimal performance compared to competitive baselines. In addition, extensive experiments demonstrate the robustness of the proposed method and the effectiveness of each component of the model\footnote{Accepted in IEEE SMC2023}.
DADIN: Domain Adversarial Deep Interest Network for Cross Domain Recommender Systems
May 20, 2023



Click-Through Rate (CTR) prediction is one of the main tasks of the recommendation system, which is conducted by a user for different items to give the recommendation results. Cross-domain CTR prediction models have been proposed to overcome problems of data sparsity, long tail distribution of user-item interactions, and cold start of items or users. In order to make knowledge transfer from source domain to target domain more smoothly, an innovative deep learning cross-domain CTR prediction model, Domain Adversarial Deep Interest Network (DADIN) is proposed to convert the cross-domain recommendation task into a domain adaptation problem. The joint distribution alignment of two domains is innovatively realized by introducing domain agnostic layers and specially designed loss, and optimized together with CTR prediction loss in a way of adversarial training. It is found that the Area Under Curve (AUC) of DADIN is 0.08% higher than the most competitive baseline on Huawei dataset and is 0.71% higher than its competitors on Amazon dataset, achieving the state-of-the-art results on the basis of the evaluation of this model performance on two real datasets. The ablation study shows that by introducing adversarial method, this model has respectively led to the AUC improvements of 2.34% on Huawei dataset and 16.67% on Amazon dataset.
MIntRec: A New Dataset for Multimodal Intent Recognition
Sep 09, 2022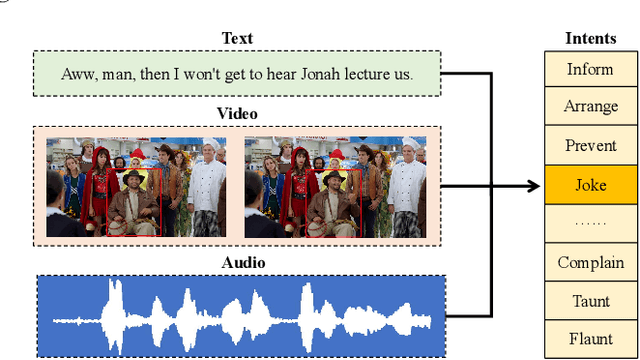

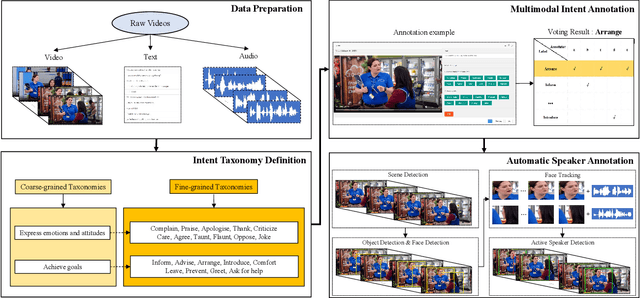

Multimodal intent recognition is a significant task for understanding human language in real-world multimodal scenes. Most existing intent recognition methods have limitations in leveraging the multimodal information due to the restrictions of the benchmark datasets with only text information. This paper introduces a novel dataset for multimodal intent recognition (MIntRec) to address this issue. It formulates coarse-grained and fine-grained intent taxonomies based on the data collected from the TV series Superstore. The dataset consists of 2,224 high-quality samples with text, video, and audio modalities and has multimodal annotations among twenty intent categories. Furthermore, we provide annotated bounding boxes of speakers in each video segment and achieve an automatic process for speaker annotation. MIntRec is helpful for researchers to mine relationships between different modalities to enhance the capability of intent recognition. We extract features from each modality and model cross-modal interactions by adapting three powerful multimodal fusion methods to build baselines. Extensive experiments show that employing the non-verbal modalities achieves substantial improvements compared with the text-only modality, demonstrating the effectiveness of using multimodal information for intent recognition. The gap between the best-performing methods and humans indicates the challenge and importance of this task for the community. The full dataset and codes are available for use at https://github.com/thuiar/MIntRec.
Towards Open Intent Detection
Mar 11, 2022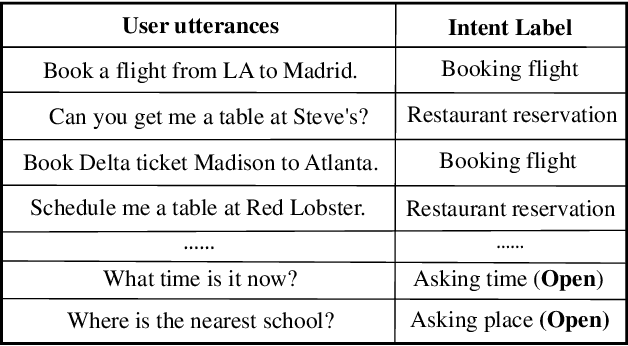

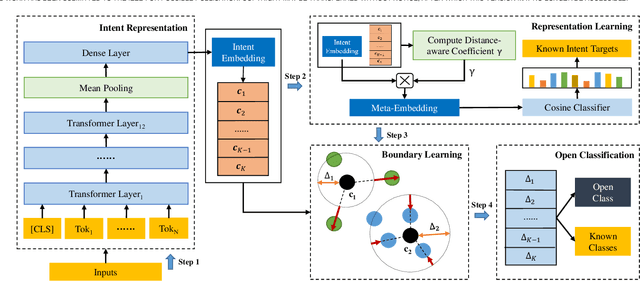

The open intent detection problem is presented in this paper, which aims to identify known intents and detect open intent in natural language understanding. Current methods have two core challenges. On the one hand, the existing methods have limitations in learning robust representations to detect the open intent without any prior knowledge. On the other hand, there lacks an effective approach to learning the specific and compact decision boundary to distinguish the known intents and the open intent. This paper introduces an original pipeline framework, DA-ADB, to address these issues, which successively learns discriminative intent features with distance-aware strategy and appropriate decision boundaries adaptive to the feature space for open intent detection. The proposed method first leverages distance information to enhance the distinguishing capability of the intent representations. Then, it obtains discriminative decision boundaries adaptive to the known intent feature space by balancing both the empirical and open space risks. Extensive experiments show the effectiveness of distance-aware and boundary learning strategies. Compared with the state-of-the-art methods, our method achieves substantial improvements on three benchmark intent datasets. It also yields robust performance with different proportions of labeled data and known categories.