 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAiEDA: An Open-Source AI-Aided Design Library for Design-to-Vector
Nov 08, 2025Recent research has demonstrated that artificial intelligence (AI) can assist electronic design automation (EDA) in improving both the quality and efficiency of chip design. But current AI for EDA (AI-EDA) infrastructures remain fragmented, lacking comprehensive solutions for the entire data pipeline from design execution to AI integration. Key challenges include fragmented flow engines that generate raw data, heterogeneous file formats for data exchange, non-standardized data extraction methods, and poorly organized data storage. This work introduces a unified open-source library for EDA (AiEDA) that addresses these issues. AiEDA integrates multiple design-to-vector data representation techniques that transform diverse chip design data into universal multi-level vector representations, establishing an AI-aided design (AAD) paradigm optimized for AI-EDA workflows. AiEDA provides complete physical design flows with programmatic data extraction and standardized Python interfaces bridging EDA datasets and AI frameworks. Leveraging the AiEDA library, we generate iDATA, a 600GB dataset of structured data derived from 50 real chip designs (28nm), and validate its effectiveness through seven representative AAD tasks spanning prediction, generation, optimization and analysis. The code is publicly available at https://github.com/OSCC-Project/AiEDA, while the full iDATA dataset is being prepared for public release, providing a foundation for future AI-EDA research.
OpenLS-DGF: An Adaptive Open-Source Dataset Generation Framework for Machine Learning Tasks in Logic Synthesis
Nov 16, 2024



This paper introduces OpenLS-DGF, an adaptive logic synthesis dataset generation framework, to enhance machine learning~(ML) applications within the logic synthesis process. Previous dataset generation flows were tailored for specific tasks or lacked integrated machine learning capabilities. While OpenLS-DGF supports various machine learning tasks by encapsulating the three fundamental steps of logic synthesis: Boolean representation, logic optimization, and technology mapping. It preserves the original information in both Verilog and machine-learning-friendly GraphML formats. The verilog files offer semi-customizable capabilities, enabling researchers to insert additional steps and incrementally refine the generated dataset. Furthermore, OpenLS-DGF includes an adaptive circuit engine that facilitates the final dataset management and downstream tasks. The generated OpenLS-D-v1 dataset comprises 46 combinational designs from established benchmarks, totaling over 966,000 Boolean circuits. OpenLS-D-v1 supports integrating new data features, making it more versatile for new challenges. This paper demonstrates the versatility of OpenLS-D-v1 through four distinct downstream tasks: circuit classification, circuit ranking, quality of results (QoR) prediction, and probability prediction. Each task is chosen to represent essential steps of logic synthesis, and the experimental results show the generated dataset from OpenLS-DGF achieves prominent diversity and applicability. The source code and datasets are available at https://github.com/Logic-Factory/ACE/blob/master/OpenLS-DGF/readme.md.
An Adaptive Open-Source Dataset Generation Framework for Machine Learning Tasks in Logic Synthesis
Nov 14, 2024This paper introduces an adaptive logic synthesis dataset generation framework designed to enhance machine learning applications within the logic synthesis process. Unlike previous dataset generation flows that were tailored for specific tasks or lacked integrated machine learning capabilities, the proposed framework supports a comprehensive range of machine learning tasks by encapsulating the three fundamental steps of logic synthesis: Boolean representation, logic optimization, and technology mapping. It preserves the original information in the intermediate files that can be stored in both Verilog and Graphmal format. Verilog files enable semi-customizability, allowing researchers to add steps and incrementally refine the generated dataset. The framework also includes an adaptive circuit engine to facilitate the loading of GraphML files for final dataset packaging and sub-dataset extraction. The generated OpenLS-D dataset comprises 46 combinational designs from established benchmarks, totaling over 966,000 Boolean circuits, with each design containing 21,000 circuits generated from 1000 synthesis recipes, including 7000 Boolean networks, 7000 ASIC netlists, and 7000 FPGA netlists. Furthermore, OpenLS-D supports integrating newly desired data features, making it more versatile for new challenges. The utility of OpenLS-D is demonstrated through four distinct downstream tasks: circuit classification, circuit ranking, quality of results (QoR) prediction, and probability prediction. Each task highlights different internal steps of logic synthesis, with the datasets extracted and relabeled from the OpenLS-D dataset using the circuit engine. The experimental results confirm the dataset's diversity and extensive applicability. The source code and datasets are available at https://github.com/Logic-Factory/ACE/blob/master/OpenLS-D/readme.md.
FaFCNN: A General Disease Classification Framework Based on Feature Fusion Neural Networks
Jul 24, 2023



There are two fundamental problems in applying deep learning/machine learning methods to disease classification tasks, one is the insufficient number and poor quality of training samples; another one is how to effectively fuse multiple source features and thus train robust classification models. To address these problems, inspired by the process of human learning knowledge, we propose the Feature-aware Fusion Correlation Neural Network (FaFCNN), which introduces a feature-aware interaction module and a feature alignment module based on domain adversarial learning. This is a general framework for disease classification, and FaFCNN improves the way existing methods obtain sample correlation features. The experimental results show that training using augmented features obtained by pre-training gradient boosting decision tree yields more performance gains than random-forest based methods. On the low-quality dataset with a large amount of missing data in our setup, FaFCNN obtains a consistently optimal performance compared to competitive baselines. In addition, extensive experiments demonstrate the robustness of the proposed method and the effectiveness of each component of the model\footnote{Accepted in IEEE SMC2023}.
Landslide Surface Displacement Prediction Based on VSXC-LSTM Algorithm
Jul 24, 2023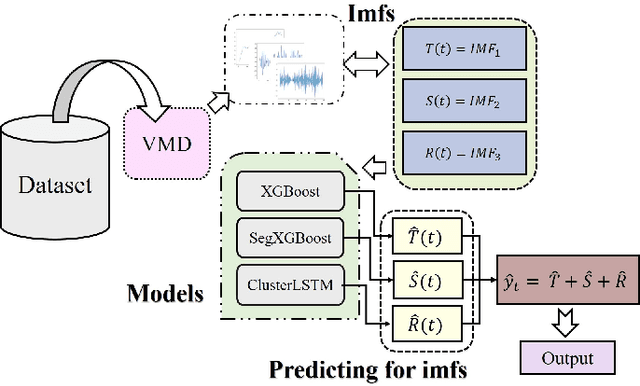
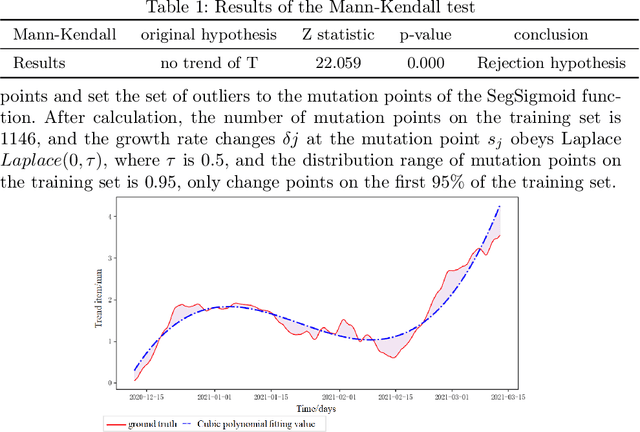
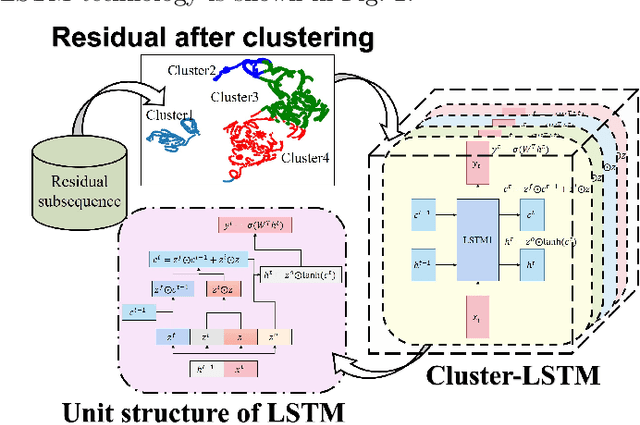

Landslide is a natural disaster that can easily threaten local ecology, people's lives and property. In this paper, we conduct modelling research on real unidirectional surface displacement data of recent landslides in the research area and propose a time series prediction framework named VMD-SegSigmoid-XGBoost-ClusterLSTM (VSXC-LSTM) based on variational mode decomposition, which can predict the landslide surface displacement more accurately. The model performs well on the test set. Except for the random item subsequence that is hard to fit, the root mean square error (RMSE) and the mean absolute percentage error (MAPE) of the trend item subsequence and the periodic item subsequence are both less than 0.1, and the RMSE is as low as 0.006 for the periodic item prediction module based on XGBoost\footnote{Accepted in ICANN2023}.