 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNN-based Path-aware multi-view Circuit Learning for Technology Mapping
Jan 14, 2026Traditional technology mapping suffers from systemic inaccuracies in delay estimation due to its reliance on abstract, technology-agnostic delay models that fail to capture the nuanced timing behavior behavior of real post-mapping circuits. To address this fundamental limitation, we introduce GPA(graph neural network (GNN)-based Path-Aware multi-view circuit learning), a novel GNN framework that learns precise, data-driven delay predictions by synergistically fusing three complementary views of circuit structure: And-Inverter Graphs (AIGs)-based functional encoding, post-mapping technology emphasizes critical timing paths. Trained exclusively on real cell delays extracted from critical paths of industrial-grade post-mapping netlists, GPA learns to classify cut delays with unprecedented accuracy, directly informing smarter mapping decisions. Evaluated on the 19 EPFL combinational benchmarks, GPA achieves 19.9%, 2.1% and 4.1% average delay reduction over the conventional heuristics methods (techmap, MCH) and the prior state-of-the-art ML-based approach SLAP, respectively-without compromising area efficiency.
Efficient Kilometer-Scale Precipitation Downscaling with Conditional Wavelet Diffusion
Jul 02, 2025


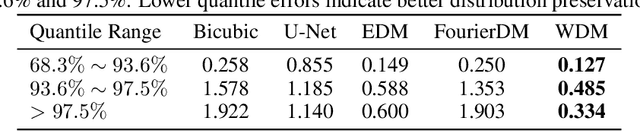
Effective hydrological modeling and extreme weather analysis demand precipitation data at a kilometer-scale resolution, which is significantly finer than the 10 km scale offered by standard global products like IMERG. To address this, we propose the Wavelet Diffusion Model (WDM), a generative framework that achieves 10x spatial super-resolution (downscaling to 1 km) and delivers a 9x inference speedup over pixel-based diffusion models. WDM is a conditional diffusion model that learns the learns the complex structure of precipitation from MRMS radar data directly in the wavelet domain. By focusing on high-frequency wavelet coefficients, it generates exceptionally realistic and detailed 1-km precipitation fields. This wavelet-based approach produces visually superior results with fewer artifacts than pixel-space models, and delivers a significant gains in sampling efficiency. Our results demonstrate that WDM provides a robust solution to the dual challenges of accuracy and speed in geoscience super-resolution, paving the way for more reliable hydrological forecasts.
FAMES: Fast Approximate Multiplier Substitution for Mixed-Precision Quantized DNNs--Down to 2 Bits!
Nov 27, 2024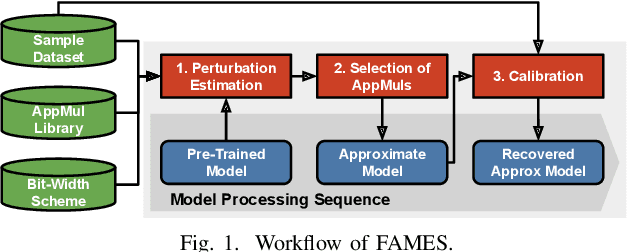
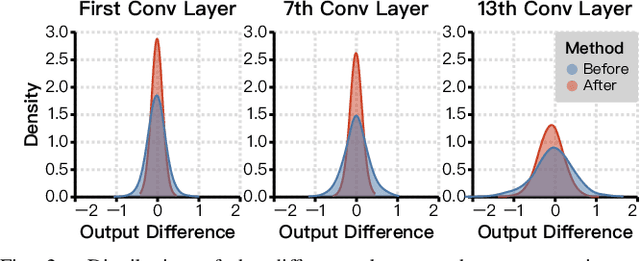
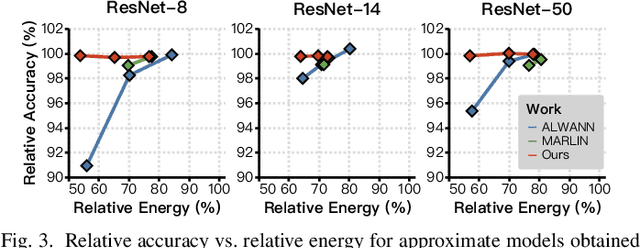
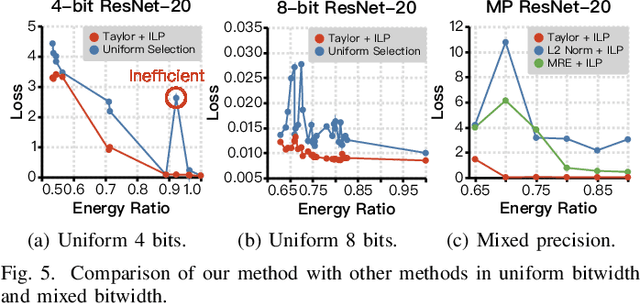
A widely-used technique in designing energy-efficient deep neural network (DNN) accelerators is quantization. Recent progress in this direction has reduced the bitwidths used in DNN down to 2. Meanwhile, many prior works apply approximate multipliers (AppMuls) in designing DNN accelerators to lower their energy consumption. Unfortunately, these works still assume a bitwidth much larger than 2, which falls far behind the state-of-the-art in quantization area and even challenges the meaningfulness of applying AppMuls in DNN accelerators, since a high-bitwidth AppMul consumes much more energy than a low-bitwidth exact multiplier! Thus, an important problem to study is: Can approximate multipliers be effectively applied to quantized DNN models with very low bitwidths? In this work, we give an affirmative answer to this question and present a systematic solution that achieves the answer: FAMES, a fast approximate multiplier substitution method for mixed-precision DNNs. Our experiments demonstrate an average 28.67% energy reduction on state-of-the-art mixed-precision quantized models with bitwidths as low as 2 bits and accuracy losses kept under 1%. Additionally, our approach is up to 300x faster than previous genetic algorithm-based methods.
OpenLS-DGF: An Adaptive Open-Source Dataset Generation Framework for Machine Learning Tasks in Logic Synthesis
Nov 16, 2024



This paper introduces OpenLS-DGF, an adaptive logic synthesis dataset generation framework, to enhance machine learning~(ML) applications within the logic synthesis process. Previous dataset generation flows were tailored for specific tasks or lacked integrated machine learning capabilities. While OpenLS-DGF supports various machine learning tasks by encapsulating the three fundamental steps of logic synthesis: Boolean representation, logic optimization, and technology mapping. It preserves the original information in both Verilog and machine-learning-friendly GraphML formats. The verilog files offer semi-customizable capabilities, enabling researchers to insert additional steps and incrementally refine the generated dataset. Furthermore, OpenLS-DGF includes an adaptive circuit engine that facilitates the final dataset management and downstream tasks. The generated OpenLS-D-v1 dataset comprises 46 combinational designs from established benchmarks, totaling over 966,000 Boolean circuits. OpenLS-D-v1 supports integrating new data features, making it more versatile for new challenges. This paper demonstrates the versatility of OpenLS-D-v1 through four distinct downstream tasks: circuit classification, circuit ranking, quality of results (QoR) prediction, and probability prediction. Each task is chosen to represent essential steps of logic synthesis, and the experimental results show the generated dataset from OpenLS-DGF achieves prominent diversity and applicability. The source code and datasets are available at https://github.com/Logic-Factory/ACE/blob/master/OpenLS-DGF/readme.md.
An Adaptive Open-Source Dataset Generation Framework for Machine Learning Tasks in Logic Synthesis
Nov 14, 2024This paper introduces an adaptive logic synthesis dataset generation framework designed to enhance machine learning applications within the logic synthesis process. Unlike previous dataset generation flows that were tailored for specific tasks or lacked integrated machine learning capabilities, the proposed framework supports a comprehensive range of machine learning tasks by encapsulating the three fundamental steps of logic synthesis: Boolean representation, logic optimization, and technology mapping. It preserves the original information in the intermediate files that can be stored in both Verilog and Graphmal format. Verilog files enable semi-customizability, allowing researchers to add steps and incrementally refine the generated dataset. The framework also includes an adaptive circuit engine to facilitate the loading of GraphML files for final dataset packaging and sub-dataset extraction. The generated OpenLS-D dataset comprises 46 combinational designs from established benchmarks, totaling over 966,000 Boolean circuits, with each design containing 21,000 circuits generated from 1000 synthesis recipes, including 7000 Boolean networks, 7000 ASIC netlists, and 7000 FPGA netlists. Furthermore, OpenLS-D supports integrating newly desired data features, making it more versatile for new challenges. The utility of OpenLS-D is demonstrated through four distinct downstream tasks: circuit classification, circuit ranking, quality of results (QoR) prediction, and probability prediction. Each task highlights different internal steps of logic synthesis, with the datasets extracted and relabeled from the OpenLS-D dataset using the circuit engine. The experimental results confirm the dataset's diversity and extensive applicability. The source code and datasets are available at https://github.com/Logic-Factory/ACE/blob/master/OpenLS-D/readme.md.
A Novel Learning Algorithm for Bayesian Network and Its Efficient Implementation on GPU
Oct 18, 2012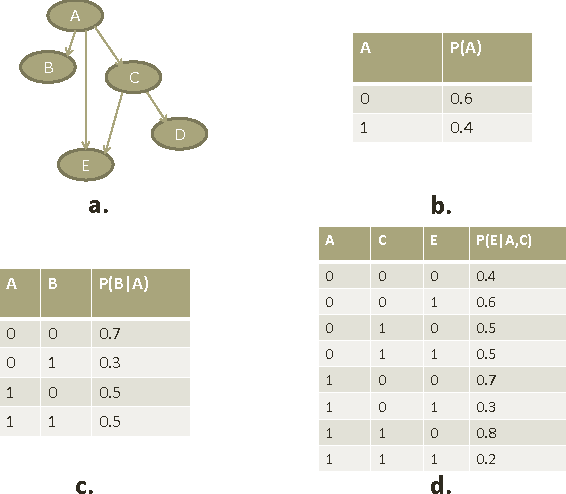
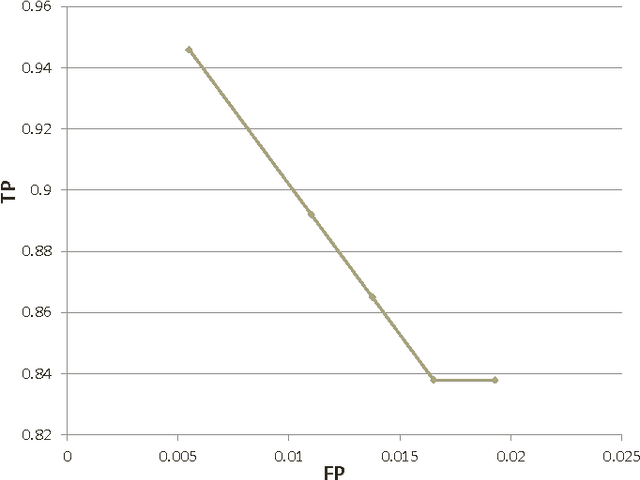
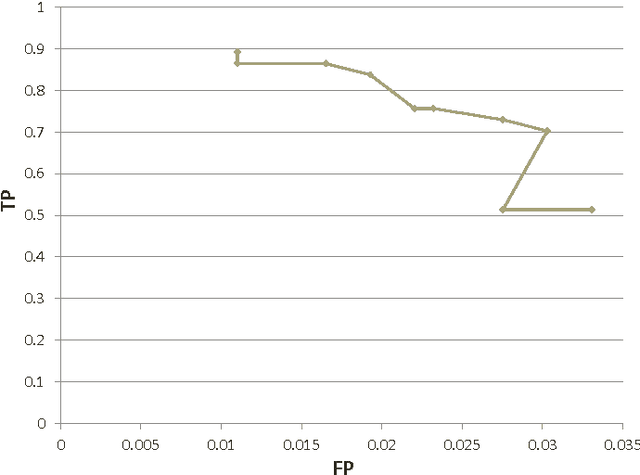
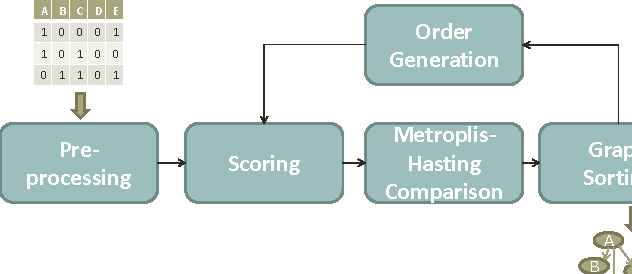
Computational inference of causal relationships underlying complex networks, such as gene-regulatory pathways, is NP-complete due to its combinatorial nature when permuting all possible interactions. Markov chain Monte Carlo (MCMC) has been introduced to sample only part of the combinations while still guaranteeing convergence and traversability, which therefore becomes widely used. However, MCMC is not able to perform efficiently enough for networks that have more than 15~20 nodes because of the computational complexity. In this paper, we use general purpose processor (GPP) and general purpose graphics processing unit (GPGPU) to implement and accelerate a novel Bayesian network learning algorithm. With a hash-table-based memory-saving strategy and a novel task assigning strategy, we achieve a 10-fold acceleration per iteration than using a serial GPP. Specially, we use a greedy method to search for the best graph from a given order. We incorporate a prior component in the current scoring function, which further facilitates the searching. Overall, we are able to apply this system to networks with more than 60 nodes, allowing inferences and modeling of bigger and more complex networks than current methods.