 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Kilometer-Scale Precipitation Downscaling with Conditional Wavelet Diffusion
Jul 02, 2025


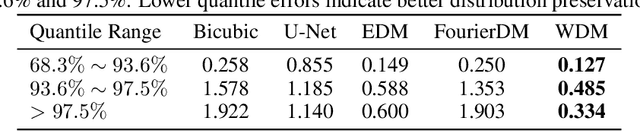
Effective hydrological modeling and extreme weather analysis demand precipitation data at a kilometer-scale resolution, which is significantly finer than the 10 km scale offered by standard global products like IMERG. To address this, we propose the Wavelet Diffusion Model (WDM), a generative framework that achieves 10x spatial super-resolution (downscaling to 1 km) and delivers a 9x inference speedup over pixel-based diffusion models. WDM is a conditional diffusion model that learns the learns the complex structure of precipitation from MRMS radar data directly in the wavelet domain. By focusing on high-frequency wavelet coefficients, it generates exceptionally realistic and detailed 1-km precipitation fields. This wavelet-based approach produces visually superior results with fewer artifacts than pixel-space models, and delivers a significant gains in sampling efficiency. Our results demonstrate that WDM provides a robust solution to the dual challenges of accuracy and speed in geoscience super-resolution, paving the way for more reliable hydrological forecasts.
Towards Better Generalization: Weight Decay Induces Low-rank Bias for Neural Networks
Oct 03, 2024



We study the implicit bias towards low-rank weight matrices when training neural networks (NN) with Weight Decay (WD). We prove that when a ReLU NN is sufficiently trained with Stochastic Gradient Descent (SGD) and WD, its weight matrix is approximately a rank-two matrix. Empirically, we demonstrate that WD is a necessary condition for inducing this low-rank bias across both regression and classification tasks. Our work differs from previous studies as our theoretical analysis does not rely on common assumptions regarding the training data distribution, optimality of weight matrices, or specific training procedures. Furthermore, by leveraging the low-rank bias, we derive improved generalization error bounds and provide numerical evidence showing that better generalization can be achieved. Thus, our work offers both theoretical and empirical insights into the strong generalization performance of SGD when combined with WD.