 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasySize: Elastic Analog Circuit Sizing via LLM-Guided Heuristic Search
Aug 07, 2025Analog circuit design is a time-consuming, experience-driven task in chip development. Despite advances in AI, developing universal, fast, and stable gate sizing methods for analog circuits remains a significant challenge. Recent approaches combine Large Language Models (LLMs) with heuristic search techniques to enhance generalizability, but they often depend on large model sizes and lack portability across different technology nodes. To overcome these limitations, we propose EasySize, the first lightweight gate sizing framework based on a finetuned Qwen3-8B model, designed for universal applicability across process nodes, design specifications, and circuit topologies. EasySize exploits the varying Ease of Attainability (EOA) of performance metrics to dynamically construct task-specific loss functions, enabling efficient heuristic search through global Differential Evolution (DE) and local Particle Swarm Optimization (PSO) within a feedback-enhanced flow. Although finetuned solely on 350nm node data, EasySize achieves strong performance on 5 operational amplifier (Op-Amp) netlists across 180nm, 45nm, and 22nm technology nodes without additional targeted training, and outperforms AutoCkt, a widely-used Reinforcement Learning based sizing framework, on 86.67\% of tasks with more than 96.67\% of simulation resources reduction. We argue that EasySize can significantly reduce the reliance on human expertise and computational resources in gate sizing, thereby accelerating and simplifying the analog circuit design process. EasySize will be open-sourced at a later date.
Back to Fundamentals: Low-Level Visual Features Guided Progressive Token Pruning
Apr 25, 2025Vision Transformers (ViTs) excel in semantic segmentation but demand significant computation, posing challenges for deployment on resource-constrained devices. Existing token pruning methods often overlook fundamental visual data characteristics. This study introduces 'LVTP', a progressive token pruning framework guided by multi-scale Tsallis entropy and low-level visual features with twice clustering. It integrates high-level semantics and basic visual attributes for precise segmentation. A novel dynamic scoring mechanism using multi-scale Tsallis entropy weighting overcomes limitations of traditional single-parameter entropy. The framework also incorporates low-level feature analysis to preserve critical edge information while optimizing computational cost. As a plug-and-play module, it requires no architectural changes or additional training. Evaluations across multiple datasets show 20%-45% computational reductions with negligible performance loss, outperforming existing methods in balancing cost and accuracy, especially in complex edge regions.
FAMES: Fast Approximate Multiplier Substitution for Mixed-Precision Quantized DNNs--Down to 2 Bits!
Nov 27, 2024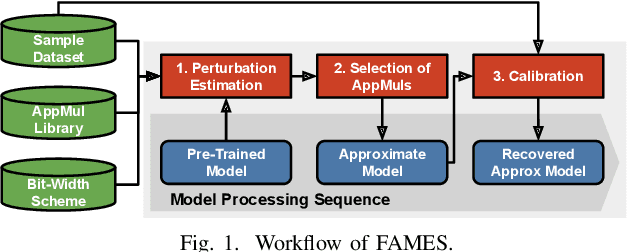
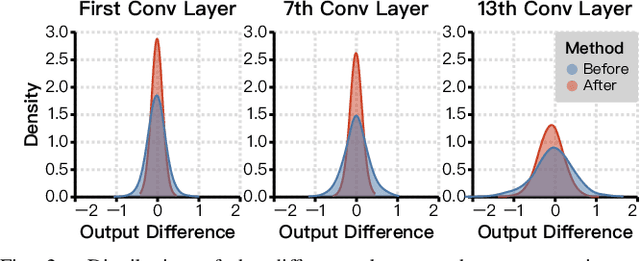
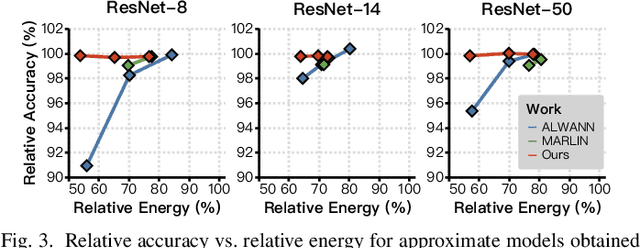
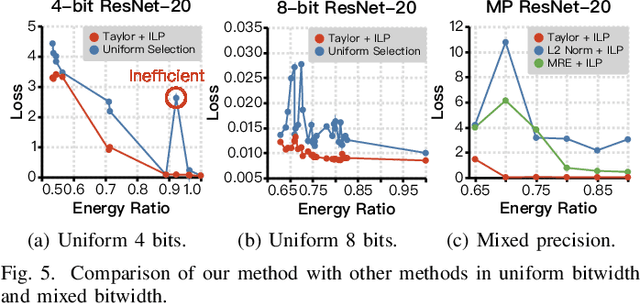
A widely-used technique in designing energy-efficient deep neural network (DNN) accelerators is quantization. Recent progress in this direction has reduced the bitwidths used in DNN down to 2. Meanwhile, many prior works apply approximate multipliers (AppMuls) in designing DNN accelerators to lower their energy consumption. Unfortunately, these works still assume a bitwidth much larger than 2, which falls far behind the state-of-the-art in quantization area and even challenges the meaningfulness of applying AppMuls in DNN accelerators, since a high-bitwidth AppMul consumes much more energy than a low-bitwidth exact multiplier! Thus, an important problem to study is: Can approximate multipliers be effectively applied to quantized DNN models with very low bitwidths? In this work, we give an affirmative answer to this question and present a systematic solution that achieves the answer: FAMES, a fast approximate multiplier substitution method for mixed-precision DNNs. Our experiments demonstrate an average 28.67% energy reduction on state-of-the-art mixed-precision quantized models with bitwidths as low as 2 bits and accuracy losses kept under 1%. Additionally, our approach is up to 300x faster than previous genetic algorithm-based methods.