 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multimodal Clustering for Semantics Discovery in Multimodal Utterances
Paper and Code
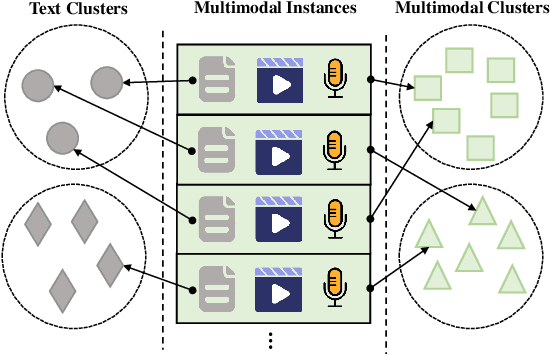
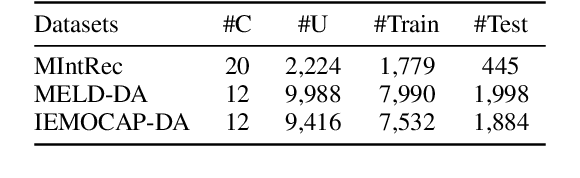
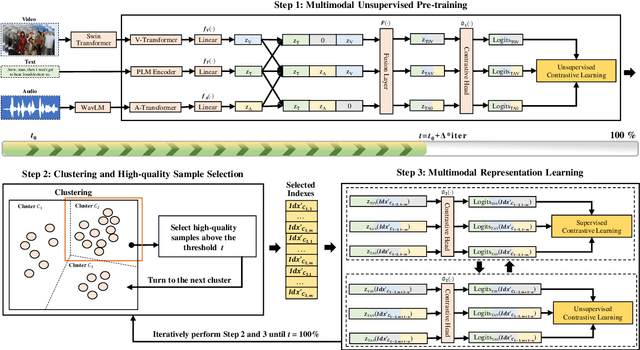
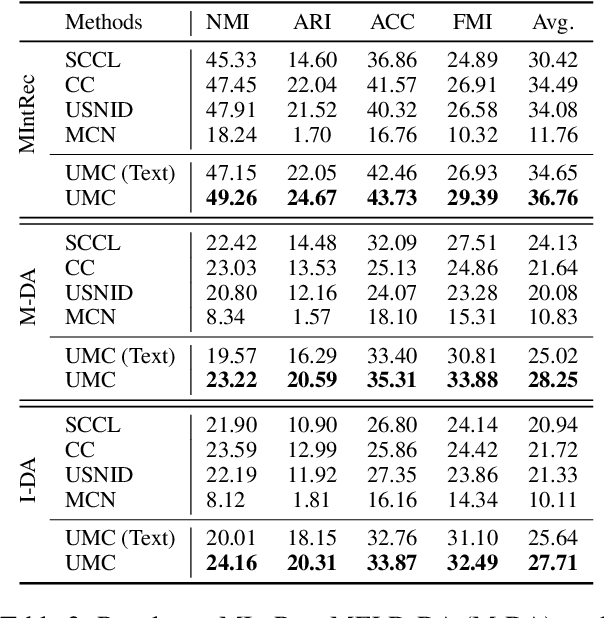
Discovering the semantics of multimodal utterances is essential for understanding human language and enhancing human-machine interactions. Existing methods manifest limitations in leveraging nonverbal information for discerning complex semantics in unsupervised scenarios. This paper introduces a novel unsupervised multimodal clustering method (UMC), making a pioneering contribution to this field. UMC introduces a unique approach to constructing augmentation views for multimodal data, which are then used to perform pre-training to establish well-initialized representations for subsequent clustering. An innovative strategy is proposed to dynamically select high-quality samples as guidance for representation learning, gauged by the density of each sample's nearest neighbors. Besides, it is equipped to automatically determine the optimal value for the top-$K$ parameter in each cluster to refine sample selection. Finally, both high- and low-quality samples are used to learn representations conducive to effective clustering. We build baselines on benchmark multimodal intent and dialogue act datasets. UMC shows remarkable improvements of 2-6\% scores in clustering metrics over state-of-the-art methods, marking the first successful endeavor in this domain. The complete code and data are available at https://github.com/thuiar/UMC.