 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsight Agents: An LLM-Based Multi-Agent System for Data Insights
Jan 27, 2026Today, E-commerce sellers face several key challenges, including difficulties in discovering and effectively utilizing available programs and tools, and struggling to understand and utilize rich data from various tools. We therefore aim to develop Insight Agents (IA), a conversational multi-agent Data Insight system, to provide E-commerce sellers with personalized data and business insights through automated information retrieval. Our hypothesis is that IA will serve as a force multiplier for sellers, thereby driving incremental seller adoption by reducing the effort required and increase speed at which sellers make good business decisions. In this paper, we introduce this novel LLM-backed end-to-end agentic system built on a plan-and-execute paradigm and designed for comprehensive coverage, high accuracy, and low latency. It features a hierarchical multi-agent structure, consisting of manager agent and two worker agents: data presentation and insight generation, for efficient information retrieval and problem-solving. We design a simple yet effective ML solution for manager agent that combines Out-of-Domain (OOD) detection using a lightweight encoder-decoder model and agent routing through a BERT-based classifier, optimizing both accuracy and latency. Within the two worker agents, a strategic planning is designed for API-based data model that breaks down queries into granular components to generate more accurate responses, and domain knowledge is dynamically injected to to enhance the insight generator. IA has been launched for Amazon sellers in US, which has achieved high accuracy of 90% based on human evaluation, with latency of P90 below 15s.
Deep-Learning Recognition of Scanning Transmission Electron Microscopy: Quantifying and Mitigating the Influence of Gaussian Noises
Sep 25, 2024
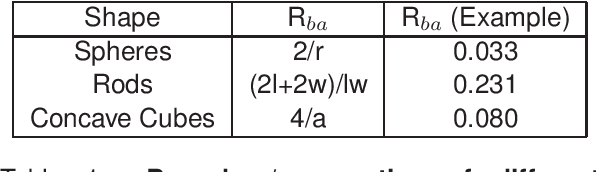
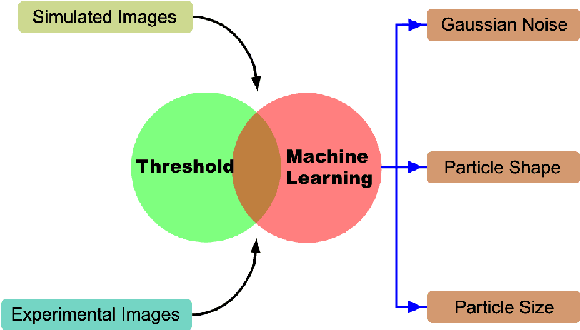
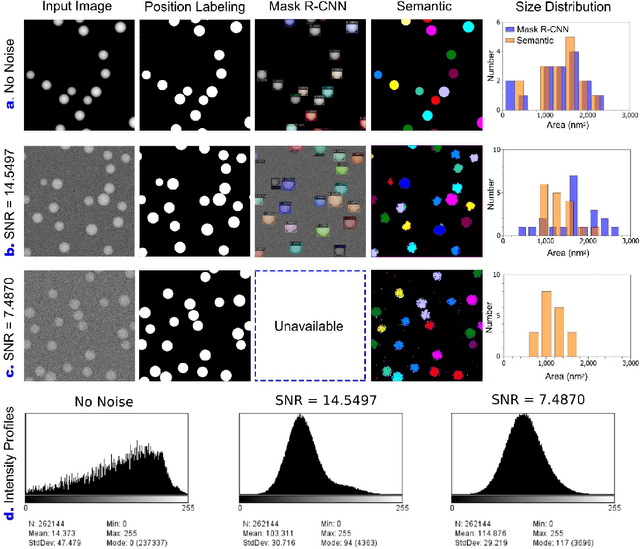
Scanning transmission electron microscopy (STEM) is a powerful tool to reveal the morphologies and structures of materials, thereby attracting intensive interests from the scientific and industrial communities. The outstanding spatial (atomic level) and temporal (ms level) resolutions of the STEM techniques generate fruitful amounts of high-definition data, thereby enabling the high-volume and high-speed analysis of materials. On the other hand, processing of the big dataset generated by STEM is time-consuming and beyond the capability of human-based manual work, which urgently calls for computer-based automation. In this work, we present a deep-learning mask region-based neural network (Mask R-CNN) for the recognition of nanoparticles imaged by STEM, as well as generating the associated dimensional analysis. The Mask R-CNN model was tested on simulated STEM-HAADF results with different Gaussian noises, particle shapes and particle sizes, and the results indicated that Gaussian noise has determining influence on the accuracy of recognition. By applying Gaussian and Non-Local Means filters on the noise-containing STEM-HAADF results, the influences of noises are largely mitigated, and recognition accuracy is significantly improved. This filtering-recognition approach was further applied to experimental STEM-HAADF results, which yields satisfying accuracy compared with the traditional threshold methods. The deep-learning-based method developed in this work has great potentials in analysis of the complicated structures and large data generated by STEM-HAADF.
Efficient Variational Inference for Sparse Deep Learning with Theoretical Guarantee
Nov 15, 2020



Sparse deep learning aims to address the challenge of huge storage consumption by deep neural networks, and to recover the sparse structure of target functions. Although tremendous empirical successes have been achieved, most sparse deep learning algorithms are lacking of theoretical support. On the other hand, another line of works have proposed theoretical frameworks that are computationally infeasible. In this paper, we train sparse deep neural networks with a fully Bayesian treatment under spike-and-slab priors, and develop a set of computationally efficient variational inferences via continuous relaxation of Bernoulli distribution. The variational posterior contraction rate is provided, which justifies the consistency of the proposed variational Bayes method. Notably, our empirical results demonstrate that this variational procedure provides uncertainty quantification in terms of Bayesian predictive distribution and is also capable to accomplish consistent variable selection by training a sparse multi-layer neural network.
Nearly Optimal Variational Inference for High Dimensional Regression with Shrinkage Priors
Oct 24, 2020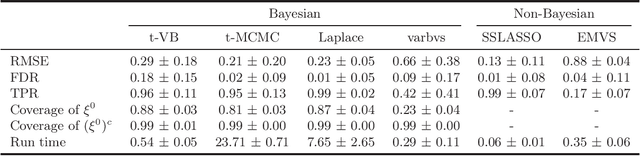
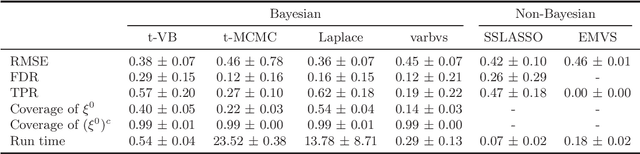
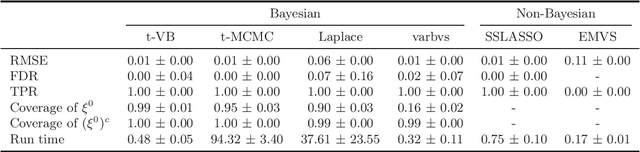
We propose a variational Bayesian (VB) procedure for high-dimensional linear model inferences with heavy tail shrinkage priors, such as student-t prior. Theoretically, we establish the consistency of the proposed VB method and prove that under the proper choice of prior specifications, the contraction rate of the VB posterior is nearly optimal. It justifies the validity of VB inference as an alternative of Markov Chain Monte Carlo (MCMC) sampling. Meanwhile, comparing to conventional MCMC methods, the VB procedure achieves much higher computational efficiency, which greatly alleviates the computing burden for modern machine learning applications such as massive data analysis. Through numerical studies, we demonstrate that the proposed VB method leads to shorter computing time, higher estimation accuracy, and lower variable selection error than competitive sparse Bayesian methods.
Stein Neural Sampler
Oct 08, 2018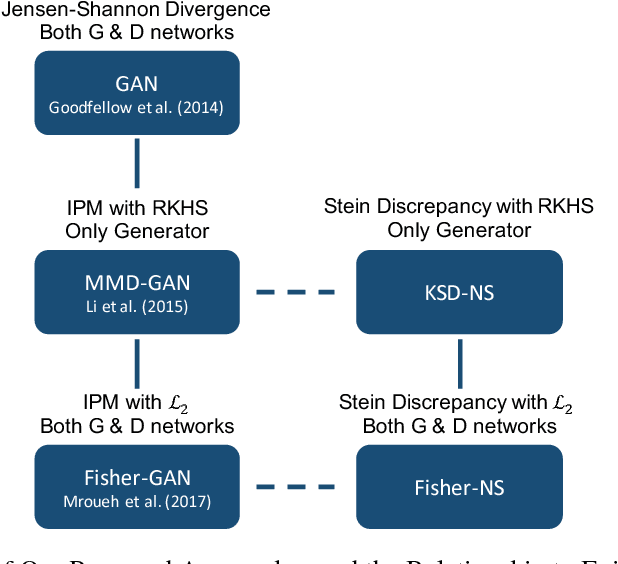
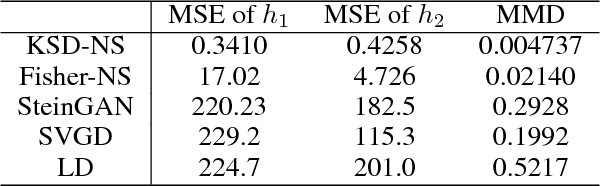
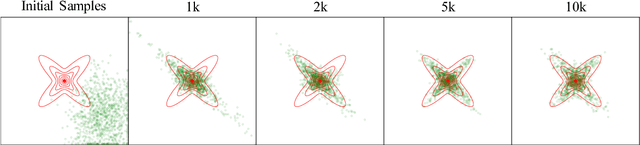
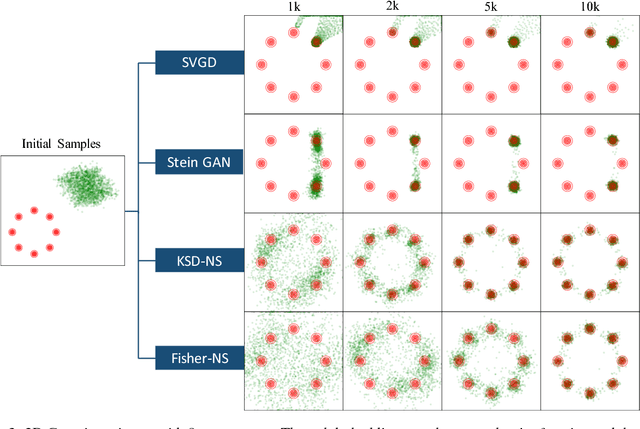
We propose two novel samplers to produce high-quality samples from a given (un-normalized) probability density. The sampling is achieved by transforming a reference distribution to the target distribution with neural networks, which are trained separately by minimizing two kinds of Stein Discrepancies, and hence our method is named as Stein neural sampler. Theoretical and empirical results suggest that, compared with traditional sampling schemes, our samplers share the following three advantages: 1. Being asymptotically correct; 2. Experiencing less convergence issue in practice; 3. Generating samples instantaneously.