 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$f$-GRPO and Beyond: Divergence-Based Reinforcement Learning Algorithms for General LLM Alignment
Feb 05, 2026Recent research shows that Preference Alignment (PA) objectives act as divergence estimators between aligned (chosen) and unaligned (rejected) response distributions. In this work, we extend this divergence-based perspective to general alignment settings, such as reinforcement learning with verifiable rewards (RLVR), where only environmental rewards are available. Within this unified framework, we propose $f$-Group Relative Policy Optimization ($f$-GRPO), a class of on-policy reinforcement learning, and $f$-Hybrid Alignment Loss ($f$-HAL), a hybrid on/off policy objectives, for general LLM alignment based on variational representation of $f$-divergences. We provide theoretical guarantees that these classes of objectives improve the average reward after alignment. Empirically, we validate our framework on both RLVR (Math Reasoning) and PA tasks (Safety Alignment), demonstrating superior performance and flexibility compared to current methods.
Task-tailored Pre-processing: Fair Downstream Supervised Learning
Jan 17, 2026Fairness-aware machine learning has recently attracted various communities to mitigate discrimination against certain societal groups in data-driven tasks. For fair supervised learning, particularly in pre-processing, there have been two main categories: data fairness and task-tailored fairness. The former directly finds an intermediate distribution among the groups, independent of the type of the downstream model, so a learned downstream classification/regression model returns similar predictive scores to individuals inputting the same covariates irrespective of their sensitive attributes. The latter explicitly takes the supervised learning task into account when constructing the pre-processing map. In this work, we study algorithmic fairness for supervised learning and argue that the data fairness approaches impose overly strong regularization from the perspective of the HGR correlation. This motivates us to devise a novel pre-processing approach tailored to supervised learning. We account for the trade-off between fairness and utility in obtaining the pre-processing map. Then we study the behavior of arbitrary downstream supervised models learned on the transformed data to find sufficient conditions to guarantee their fairness improvement and utility preservation. To our knowledge, no prior work in the branch of task-tailored methods has theoretically investigated downstream guarantees when using pre-processed data. We further evaluate our framework through comparison studies based on tabular and image data sets, showing the superiority of our framework which preserves consistent trade-offs among multiple downstream models compared to recent competing models. Particularly for computer vision data, we see our method alters only necessary semantic features related to the central machine learning task to achieve fairness.
Knowledge Distillation Detection for Open-weights Models
Oct 02, 2025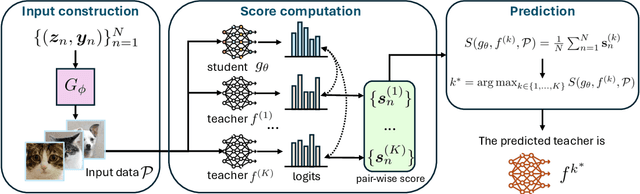

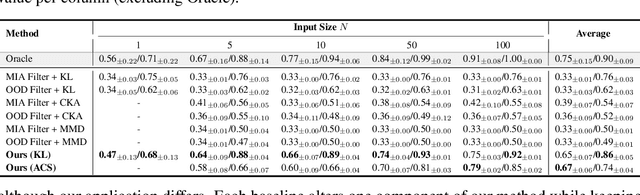
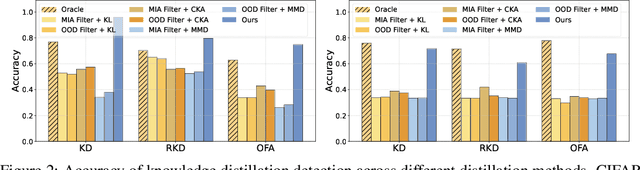
We propose the task of knowledge distillation detection, which aims to determine whether a student model has been distilled from a given teacher, under a practical setting where only the student's weights and the teacher's API are available. This problem is motivated by growing concerns about model provenance and unauthorized replication through distillation. To address this task, we introduce a model-agnostic framework that combines data-free input synthesis and statistical score computation for detecting distillation. Our approach is applicable to both classification and generative models. Experiments on diverse architectures for image classification and text-to-image generation show that our method improves detection accuracy over the strongest baselines by 59.6% on CIFAR-10, 71.2% on ImageNet, and 20.0% for text-to-image generation. The code is available at https://github.com/shqii1j/distillation_detection.
Parallelly Tempered Generative Adversarial Networks
Nov 18, 2024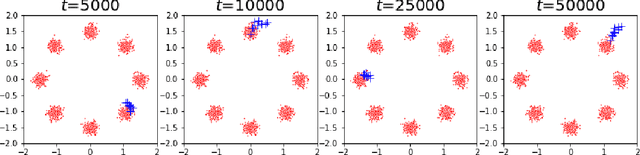



A generative adversarial network (GAN) has been a representative backbone model in generative artificial intelligence (AI) because of its powerful performance in capturing intricate data-generating processes. However, the GAN training is well-known for its notorious training instability, usually characterized by the occurrence of mode collapse. Through the lens of gradients' variance, this work particularly analyzes the training instability and inefficiency in the presence of mode collapse by linking it to multimodality in the target distribution. To ease the raised training issues from severe multimodality, we introduce a novel GAN training framework that leverages a series of tempered distributions produced via convex interpolation. With our newly developed GAN objective function, the generator can learn all the tempered distributions simultaneously, conceptually resonating with the parallel tempering in Statistics. Our simulation studies demonstrate the superiority of our approach over existing popular training strategies in both image and tabular data synthesis. We theoretically analyze that such significant improvement can arise from reducing the variance of gradient estimates by using the tempered distributions. Finally, we further develop a variant of the proposed framework aimed at generating fair synthetic data which is one of the growing interests in the field of trustworthy AI.
Adversarial Vulnerability as a Consequence of On-Manifold Inseparibility
Oct 09, 2024
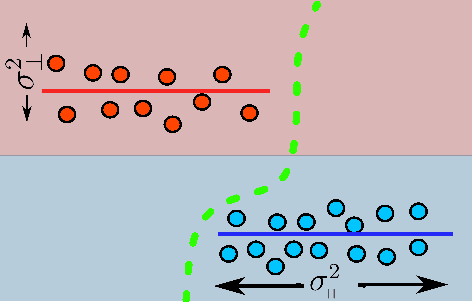
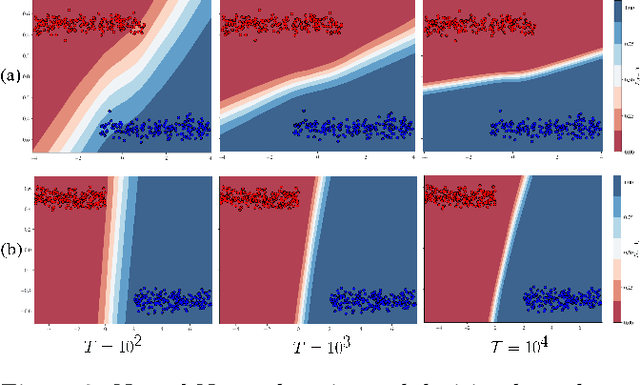
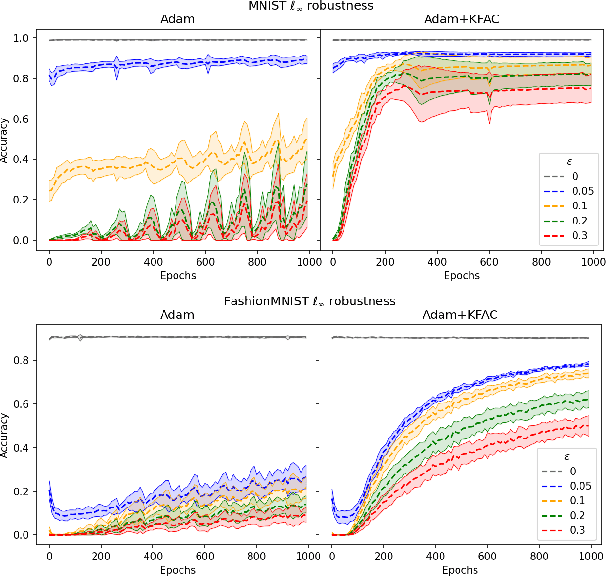
Recent works have shown theoretically and empirically that redundant data dimensions are a source of adversarial vulnerability. However, the inverse doesn't seem to hold in practice; employing dimension-reduction techniques doesn't exhibit robustness as expected. In this work, we consider classification tasks and characterize the data distribution as a low-dimensional manifold, with high/low variance features defining the on/off manifold direction. We argue that clean training experiences poor convergence in the off-manifold direction caused by the ill-conditioning in widely used first-order optimizers like gradient descent. The poor convergence then acts as a source of adversarial vulnerability when the dataset is inseparable in the on-manifold direction. We provide theoretical results for logistic regression and a 2-layer linear network on the considered data distribution. Furthermore, we advocate using second-order methods that are immune to ill-conditioning and lead to better robustness. We perform experiments and exhibit tremendous robustness improvements in clean training through long training and the employment of second-order methods, corroborating our framework. Additionally, we find the inclusion of batch-norm layers hinders such robustness gains. We attribute this to differing implicit biases between traditional and batch-normalized neural networks.
Bayesian Federated Learning with Hamiltonian Monte Carlo: Algorithm and Theory
Jul 09, 2024



This work introduces a novel and efficient Bayesian federated learning algorithm, namely, the Federated Averaging stochastic Hamiltonian Monte Carlo (FA-HMC), for parameter estimation and uncertainty quantification. We establish rigorous convergence guarantees of FA-HMC on non-iid distributed data sets, under the strong convexity and Hessian smoothness assumptions. Our analysis investigates the effects of parameter space dimension, noise on gradients and momentum, and the frequency of communication (between the central node and local nodes) on the convergence and communication costs of FA-HMC. Beyond that, we establish the tightness of our analysis by showing that the convergence rate cannot be improved even for continuous FA-HMC process. Moreover, extensive empirical studies demonstrate that FA-HMC outperforms the existing Federated Averaging-Langevin Monte Carlo (FA-LD) algorithm.
Effect of Ambient-Intrinsic Dimension Gap on Adversarial Vulnerability
Mar 06, 2024



The existence of adversarial attacks on machine learning models imperceptible to a human is still quite a mystery from a theoretical perspective. In this work, we introduce two notions of adversarial attacks: natural or on-manifold attacks, which are perceptible by a human/oracle, and unnatural or off-manifold attacks, which are not. We argue that the existence of the off-manifold attacks is a natural consequence of the dimension gap between the intrinsic and ambient dimensions of the data. For 2-layer ReLU networks, we prove that even though the dimension gap does not affect generalization performance on samples drawn from the observed data space, it makes the clean-trained model more vulnerable to adversarial perturbations in the off-manifold direction of the data space. Our main results provide an explicit relationship between the $\ell_2,\ell_{\infty}$ attack strength of the on/off-manifold attack and the dimension gap.
Benefits of Transformer: In-Context Learning in Linear Regression Tasks with Unstructured Data
Feb 01, 2024In practice, it is observed that transformer-based models can learn concepts in context in the inference stage. While existing literature, e.g., \citet{zhang2023trained,huang2023context}, provide theoretical explanations on this in-context learning ability, they assume the input $x_i$ and the output $y_i$ for each sample are embedded in the same token (i.e., structured data). However, in reality, they are presented in two tokens (i.e., unstructured data \cite{wibisono2023role}). In this case, this paper conducts experiments in linear regression tasks to study the benefits of the architecture of transformers and provides some corresponding theoretical intuitions to explain why the transformer can learn from unstructured data. We study the exact components in a transformer that facilitate the in-context learning. In particular, we observe that (1) a transformer with two layers of softmax (self-)attentions with look-ahead attention mask can learn from the prompt if $y_i$ is in the token next to $x_i$ for each example; (2) positional encoding can further improve the performance; and (3) multi-head attention with a high input embedding dimension has a better prediction performance than single-head attention.
Better Representations via Adversarial Training in Pre-Training: A Theoretical Perspective
Jan 26, 2024Pre-training is known to generate universal representations for downstream tasks in large-scale deep learning such as large language models. Existing literature, e.g., \cite{kim2020adversarial}, empirically observe that the downstream tasks can inherit the adversarial robustness of the pre-trained model. We provide theoretical justifications for this robustness inheritance phenomenon. Our theoretical results reveal that feature purification plays an important role in connecting the adversarial robustness of the pre-trained model and the downstream tasks in two-layer neural networks. Specifically, we show that (i) with adversarial training, each hidden node tends to pick only one (or a few) feature; (ii) without adversarial training, the hidden nodes can be vulnerable to attacks. This observation is valid for both supervised pre-training and contrastive learning. With purified nodes, it turns out that clean training is enough to achieve adversarial robustness in downstream tasks.
Fair Supervised Learning with A Simple Random Sampler of Sensitive Attributes
Nov 10, 2023



As the data-driven decision process becomes dominating for industrial applications, fairness-aware machine learning arouses great attention in various areas. This work proposes fairness penalties learned by neural networks with a simple random sampler of sensitive attributes for non-discriminatory supervised learning. In contrast to many existing works that critically rely on the discreteness of sensitive attributes and response variables, the proposed penalty is able to handle versatile formats of the sensitive attributes, so it is more extensively applicable in practice than many existing algorithms. This penalty enables us to build a computationally efficient group-level in-processing fairness-aware training framework. Empirical evidence shows that our framework enjoys better utility and fairness measures on popular benchmark data sets than competing methods. We also theoretically characterize estimation errors and loss of utility of the proposed neural-penalized risk minimization problem.