 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Neural Network approximation of ideal adversarial attack and convergence of adversarial training
Paper and Code
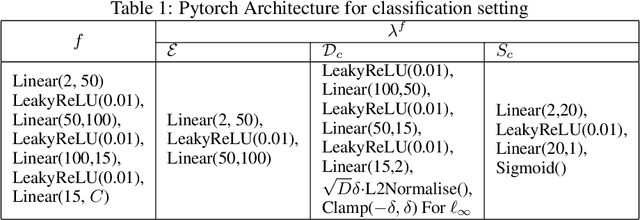
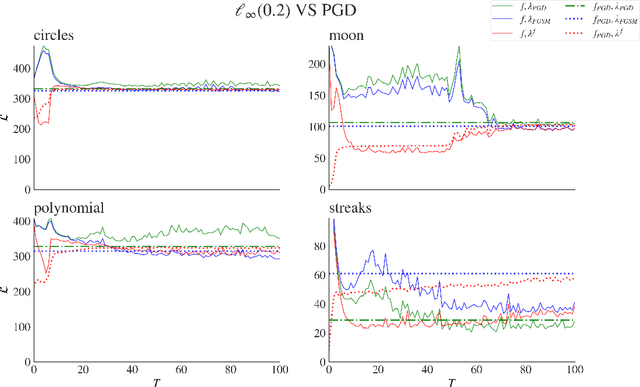
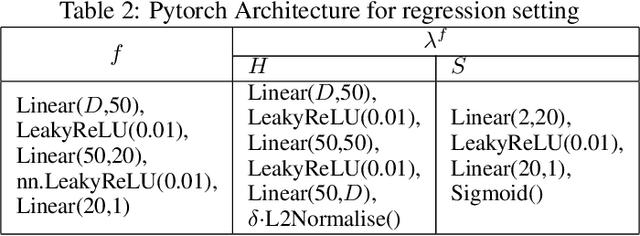
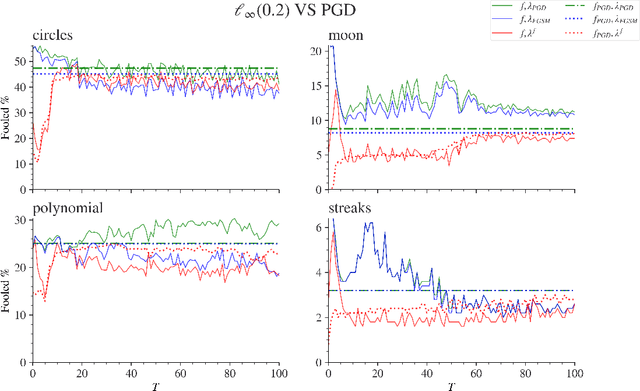
Adversarial attacks are usually expressed in terms of a gradient-based operation on the input data and model, this results in heavy computations every time an attack is generated. In this work, we solidify the idea of representing adversarial attacks as a trainable function, without further gradient computation. We first motivate that the theoretical best attacks, under proper conditions, can be represented as smooth piece-wise functions (piece-wise H\"older functions). Then we obtain an approximation result of such functions by a neural network. Subsequently, we emulate the ideal attack process by a neural network and reduce the adversarial training to a mathematical game between an attack network and a training model (a defense network). We also obtain convergence rates of adversarial loss in terms of the sample size $n$ for adversarial training in such a setting.